Future is now
fanfer
记录 AI 系统、工程实践、论文阅读与长期问题。
Latest stories

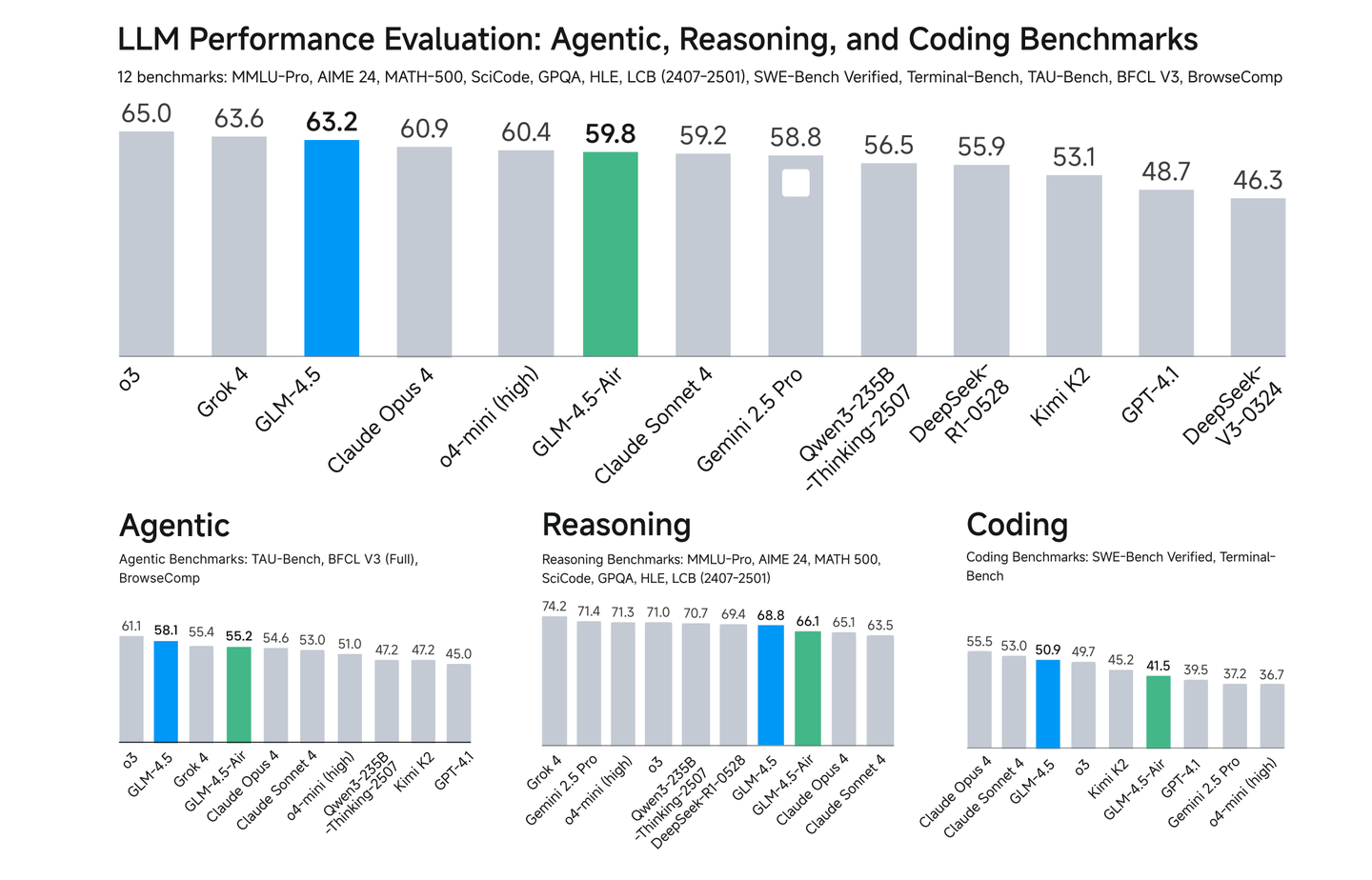
MiniMax-M1
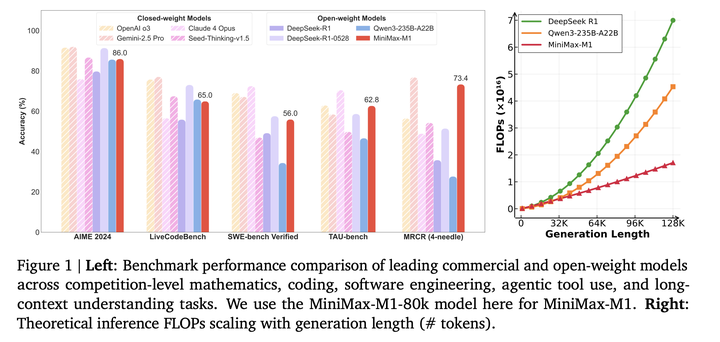
MiniMax-M1:基于Lightning Attention的MoE模型(456B总参数,45.9B激活),提出CISPO算法提升RL训练效率,支持80K长上下文推理,在复杂软件工程和工具利用任务上表现突出。

Future is now
记录 AI 系统、工程实践、论文阅读与长期问题。
MiniMax-M1:基于Lightning Attention的MoE模型(456B总参数,45.9B激活),提出CISPO算法提升RL训练效率,支持80K长上下文推理,在复杂软件工程和工具利用任务上表现突出。