

快速摘要: DeepSeek-V3.2提出了三大核心技术突破:(1) DeepSeek Sparse Attention(DSA),一种高效的注意力机制,在长上下文场景中大幅降低计算复杂度同时保持模型性能;(2) 可扩展的强化学习框架,后训练预算超过预训练成本的10%,使DeepSeek-V3.2性能与GPT-5相当,高计算量变体DeepSeek-V3.2-Speciale超越GPT-5,在2025 IMO和IOI中均取得金牌级表现;(3) 大规模智能体任务合成管线,生成超过1800个不同环境和85000个复杂prompt,显著提升了模型在工具调用场景中的泛化能力和指令遵循能力。
论文DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models。
本文提出DeepSeek-V3.2,其关键技术突破如下:(1) **DeepSeek Sparse Attention (DSA):**提出DSA,一种高效的注意力机制,在长上下文场景中,能在保持模型性能的同时大幅降低计算复杂度。(2) **Scalable Reinforcement Learning Framework:**通过实施稳健的强化学习,并扩展后训练计算规模,DeepSeek-V3.2性能可与GPT-5相当,高计算量变体DeepSeek-V3.2-Speciale超越了GPT-5,推理能力与 Gemini-3.0-Pro 持平,在2025 IMO和IOI中均取得金牌级表现。(3) **Large-Scale Agentic Task Synthesis Pipeline:**为将推理融入工具调用场景,开发了一种新颖的合成 pipeline,可系统性地大规模生成训练数据。这种方法有助于可扩展的agentic后训练,在复杂、交互式环境中,显著提升模型的泛化能力和遵循指令能力。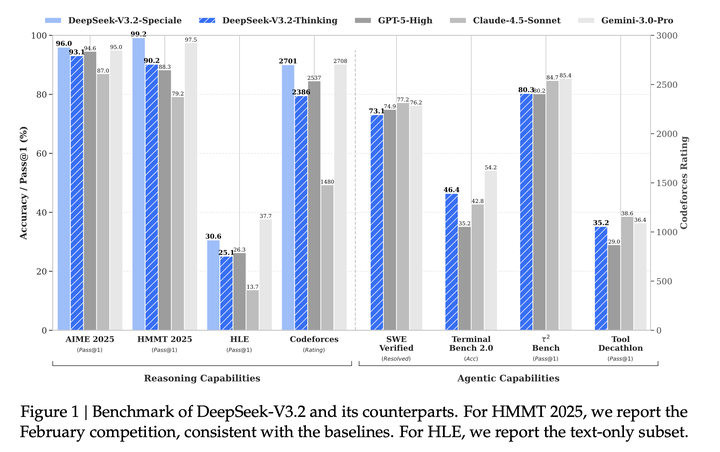
DeepSeek分析了当前开源模型存在的一些问题。首先,在架构方面,对普通注意力机制的过度依赖,会严重限制长序列场景下的效率。这种低效给scalable deployment 和有效的post-training都带来了巨大障碍。其次,在资源分配方面,开源模型在post-training的计算投入不足,会限制在困难任务上的表现。最后,在AI agents情境下,与专有模型相比,开源模型在泛化能力和指令遵循能力上存在明显差距。
为了解决这些关键问题,DeepSeek引入DeepSeek Sparse Attention (DSA),这种架构有效解决了效率瓶颈,即使在长上下文场景中也能保持模型性能。其次开发了一个稳定且可扩展的RL训练框架,能在post-training阶段进行显著scaling,该框架分配的**后训练预算超过预训练成本的10%。**此外,DeepSeek还提出了一种tool use场景的可泛化reasoning方法。首先,利用DeepSeek-V3实施冷启动阶段,在单一trajectory中统一reasoning和tool use。随后,推进到大规模agent任务合成,生成超过1800个不同的环境和85000个复杂prompt。这些广泛的合成数据驱动强化学习过程,显著增强模型在agent情境下的泛化能力和指令遵循能力。### DeepSeek-V3.2 Architecture
使用DeepSeek Sparse Attention结构,使用Lightning indexer,即轻量的 scorer(低维head、可用低精度如 FP8)为每个 query 对历史每个token 快速计算一个index score,再对index scores做Top-k,选出少量 key/value,然后在这些被选出的key/value上做MLA。
DeepSeek-V3.2 继续训练自V3.1-Terminus,和V3.1一样都使用MLA,采用MLA的MQA 模式来实现 DSA,其中每个 latent vector都会被该 query token 的所有query head共享: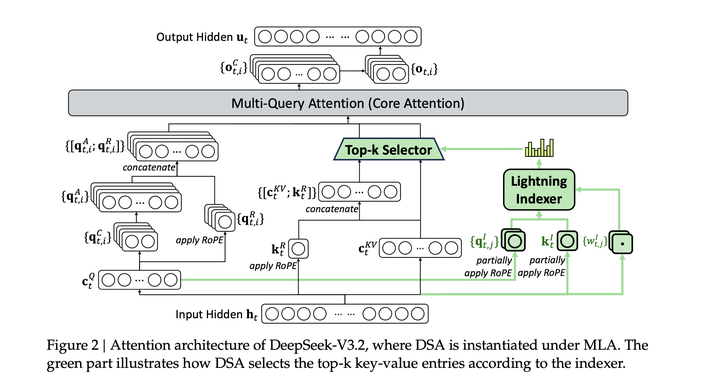
其中lightning indexer会有一个warm up的阶段,冻结lightning indexer之外的所有模型参数,用KL作为训练目标,KL 的目标是让 indexer 的预测分布逼近 dense attention的真实分布:
之后再训练sparse attention,indexer每次为query选出top-k的重要tokens,主模型只在这些tokens上计算注意力;indexer继续学习main attention分布,但只学习top-k 内:
截至2025年9月,在一系列侧重多样化能力的benchmark测试上评估了DeepSeek-V3.2-Exp,并与DeepSeek-V3.1-Terminus进行了对比,结果显示性能相似。DeepSeek-V3.2-Exp 在处理长序列时显著提升了计算效率,而且在短上下文和长上下文任务上,其性能并未出现明显下降。
**人工偏好评估:**考虑到直接的人类偏好评估本质上容易受到偏差影响,使用ChatbotArena作为间接评估框架,DeepSeek-V3.1-Terminus与DeepSeek-V3.2-Exp采用相同的后训练策略,其Elo分数几乎相同。这表明,即便引入了稀疏注意力机制,新一代基础模型的性能仍与前一版本持平。
长上下文评估:在 DeepSeek-V3.2-Exp发布后,有多个独立的长上下文评估使用了DeepSeek-V3.2-Exp未见过的测试集。代表性的benchmark是AA-LCR3,其中DeepSeek-V3.2-Exp在推理模式下的得分比DeepSeek-V3.1-Terminus高四分。在Fiction.liveBench评测中,DeepSeek-V3.2-Exp在多个指标上均持续优于 DeepSeek-V3.1-Terminus。这些结果表明,DeepSeek-V3.2-Exp在长上下文任务上没有性能回退。### 推理成本
DSA降低了attention的计算复杂度,与DeepSeek-V3.1-Terminus中的MLA相比,其计算量要小得多。结合优化实现,DSA 在长上下文场景中实现了显著的端到端加速。
如图展示了DeepSeek-V3.1-Terminus 和DeepSeek-V3.2的token cost对比: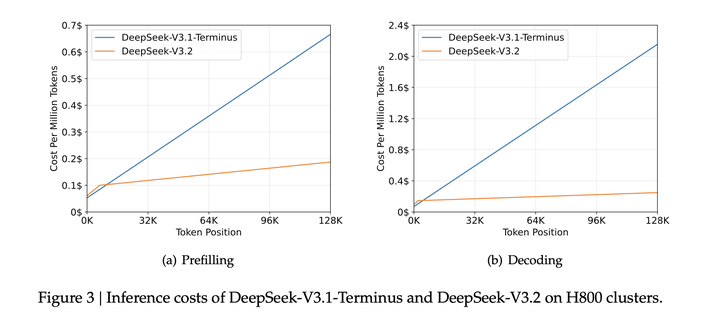
和预训练相同,使用sparse attention训练。后训练包括 specialist distillation 和mixed RL training两部分流程。
Specialist distillation:针对每个任务,首先开发专门针对该特定领域的专业模型,所有专业模型均从同一个预训练的 DeepSeek-V3.2 base checkpoint 进行微调。除了写作任务和通用问答,还涵盖六个专业领域:数学、编程、通用逻辑推理、general agentic tasks, agentic coding和 agentic search,所有领域都支持思考和非思考模式。每个专家模型都通过Large-scale RL计算进行训练。
之后,会用不同的专业模型为思考模式和非思考模式生成训练数据。实验结果表明,在蒸馏后数据上训练的模型,性能仅略低于特定领域的专业模型,且通过后续的强化学习训练,性能差距可有效消除。
DeepSeek-V3.2 整合了从专家模型蒸馏而来的推理、智能体和人类对齐数据,经过数千步的持续强化学习训练,以达到最终checkpoint。为探究深度思考的潜力,还开发了一个实验变体DeepSeek-V3.2-Speciale。该模型在强化学习训练期间,**仅使用推理数据进行训练,且降低了长度惩罚。**此外,还纳入了来自DeepSeekMath-V2的数据集和奖励方法,以增强数学证明方面的能力。
**Mixed RL training:**使用 GRPO 作为强化学习训练算法。**将推理、智能体和人类对齐训练合并到一个强化学习阶段。这种方法在有效平衡不同领域性能的同时,规避了多阶段训练范式中常见的灾难性遗忘问题。**对于推理和智能体任务,我们采用基于规则的结果奖励、长度惩罚和语言一致性奖励。对于通用任务,采用生成式奖励模型,每个 prompt 都有自己的评估标准。
**Scaling RL:**采用改进的GRPO算法:
没有用DAPO中的loss aggregatie的方式,还是在seq-level求mean。另外,adv的计算使用了Dr.GRPO的策略,没有除std。
和其他算法的差异:- 带有KL约束:使用K3估计 (相比于KL估计,非负,无偏差,方差小),但进行了改进,用importance ratio进行修正 **( inference-training mismatch修正)****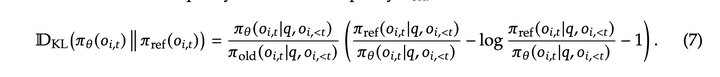
这种调整直接带来的结果是,KL 估计器的梯度变为无偏的,消除了系统性的估计误差,从而促进稳定收敛。这与原始的 K3 估计器形成鲜明对比,尤其是在采样的 token 在当前策略下的概率远低于参考策略(即π_θ≪π_ref)时。在这种情况下,K3 估计器的梯度会给这些标记分配极大、无界的权重,以最大化它们的似然,会导致有噪声的梯度更新,这些更新不断累积,会在后续迭代中降低样本质量**,并引发不稳定的训练动态。在实践中,发现不同领域需要不同强度的 KL 正则化。对于某些领域,比如数学领域,应用相对较弱的 KL 惩罚,甚至完全不用KL,都能带来性能提升。- off-Policy Sequence Masking:对于seq_level ratio较大,off-policy较为严重的负样本sequence,会直接mask掉。只mask负样本,计算π_θ和π_old (用inference计算)之间的 KL,超过阈值进行mask。仅对具有负adv的序列进行mask的原因:直观而言,模型从自身错误中学习受益最大,而高度 off-policy 的负样本可能有害,有可能误导或破坏优化过程的稳定性(Qwen的SAPO中也提到对负样本的打压会影响训练的稳定性,正负样本的超参数需要分别设置)
**Thinking Context Management:**DeepSeek-V3.2 将思考能力整合到工具调用场景中。实验观察到,复制 DeepSeek-R1 的策略(在第二轮message到达时discarding reasoning content)会导致显著的token低效问题。这种方法会迫使模型在每次后续工具调用时,都对整个问题进行冗余的重新推理。为缓解此问题,开发了一种严格针对工具调用场景的上下文管理方法,如图所示: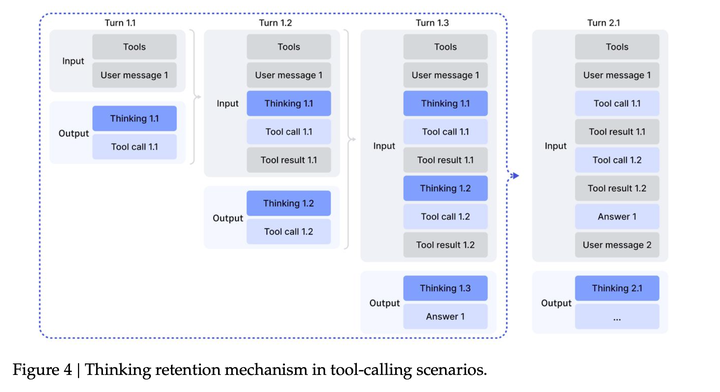
冷启动:由于存在reasoning data (non-agentic) 和 non-reasoning agentic data,整合这两种能力的一个直接的策略是精心设计prompt,让模型具备足够的能力来准确遵循明确的指令,从而能够在推理过程中无缝融入工具执行: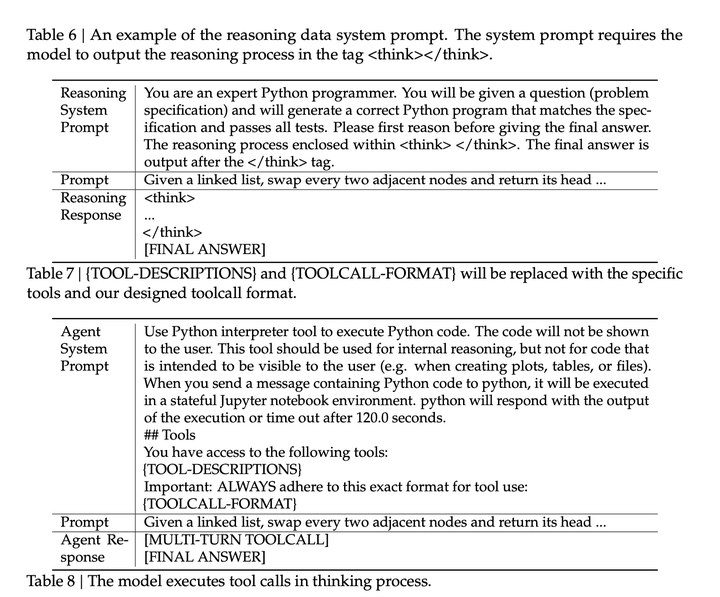
大规模智能体任务:对于搜索、代码工程和代码解释等任务,使用真实世界的工具,包括实际的网页搜索 API、编码工具和 Jupyter Notebook。虽然这些强化学习环境是真实的,但所使用的prompt是从互联网资源中提取的或人工合成的,而非来自实际的用户交互。对于其他任务,环境和提示都是人工构建的。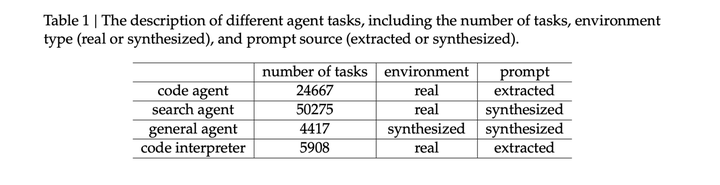
按照这个工作流程,获得数千个 <环境、工具、任务、验证器> tuples。然后,使用 DeepSeek-V3.2 在该数据集上进行强化学习,仅保留 pass@100 非零的实例,得到1827 个环境及其对应的任务(共 4417个任务)。示例任务和解决方案如下:
DeepSeek-V3.2 在推理任务上的性能与 GPT-5-high 相近,但略逊于 Gemini-3.0-Pro: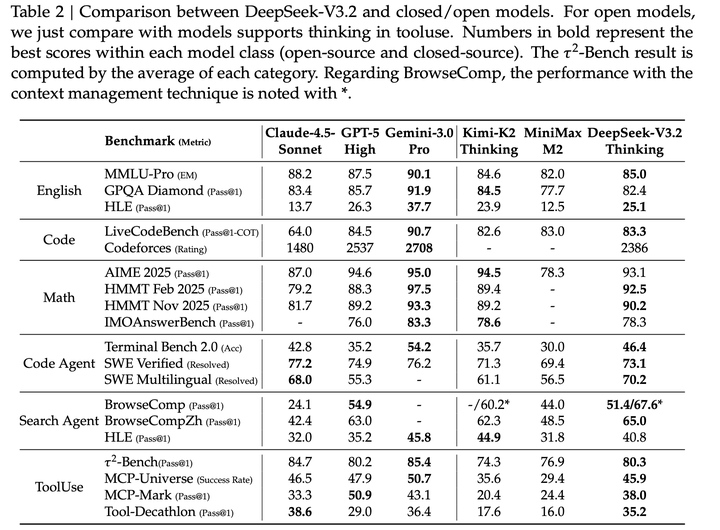
与K2-Thinking相比,DeepSeek-V3.2得分相当,但输出token数量少得多。这些性能提升可归因于分配给强化学习训练的计算资源增加。近几个月来,DeepSeek观察到与扩展强化学习训练预算一致的性能改进,该预算已超过预训练成本的10%。可以推测,额外的计算预算分配可进一步增强推理能力。此处呈现的 DeepSeek-V3.2 性能受长度约束奖励模型限制;移除该限制后,模型性能还能进一步提升。
在代码智能体评估中,DeepSeek-V3.2在SWE-bench Verified和Terminal Bench 2.0上显著优于开源模型。关于Terminal Bench 2.0,报告的46.4分是使用 Claude Code 框架取得的。还在非思考模式下用Terminus评估了 DeepSeek-V3.2,得分为 39.3。对于 SWE-bench Verified,主要得分是使用内部框架获得的。在其他设置(包括 Claude Code 和 RooCode框架以及非思考模式)下的测试,产生了72到74的一致结果。
对于搜索agent评估,使用标准商业搜索API评估模型。由于DeepSeek-V3.2仅支持最大 128K的上下文长度,约20%+的测试用例超出此限制。为解决该问题,采用上下文管理方法得出最终得分。作为参考,不使用上下文管理时得分为 51.4。
在工具使用benchmark上,DeepSeek-V3.2大幅缩小了开源与闭源大语言模型之间的性能差距。对于τ2-bench,将模型本身作为用户智能体,取得了 63.8(航空)、81.1(零售)和 96.2(电信)的最终类别得分。对于MCP,采用函数调用格式,并将工具输出置于指定为tool角色的消息中,而非user角色。在测试中,观察到 DeepSeek-V3.2 经常进行冗余的自我验证,生成过长的轨迹。这种倾向往往导致上下文长度超出128K限制,尤其是在 MCP-Mark GitHub 和 Playwright 评估等任务中。因此,这种现象阻碍了DeepSeek-V3.2 的最终性能。不过,整合上下文管理策略可进一步提升性能。即使 DeepSeek-V3.2 存在该问题,它仍显著优于现有的开源模型。值得注意的是,由于这些benchmark中使用的环境和工具集在强化学习训练期间未遇到,观察到的改进表明 DeepSeek-V3.2 有能力将其推理策略泛化到领域外的智能体场景。
DeepSeek-V3.2-Speciale通过利用更多的推理token实现了更优性能,在多个benchmark上超越了最先进的Gemini-3.0-Pro。在未进行针对性训练的情况下,在 2025 IOI和ICPC WF中取得了金牌级别的表现。此外,该模型在复杂证明任务中表现出色,在 2025 IMO和CMO中达到金牌门槛: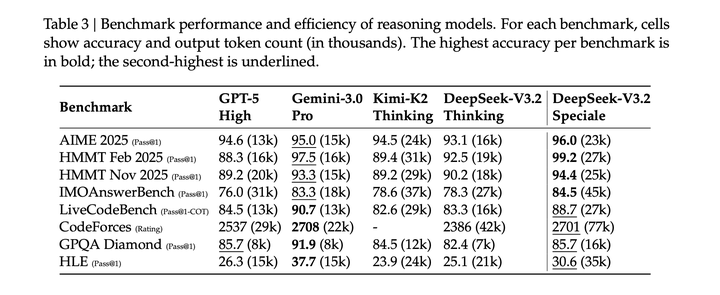
开展消融实验,研究合成agent任务的效果,聚焦于两个问题。第一,合成任务对强化学习而言是否具有足够的挑战性?第二,这些合成任务的泛化能力如何,能否迁移到不同的下游任务或真实世界环境中?
为解决第一个问题,从通用合成agent任务中随机采样50个实例,评估用于合成的模型以及前沿闭源大语言模型。如图,DeepSeek-V3.2-Exp的准确率仅为 12%,而前沿闭源模型的准确率最高为 62%。这些结果表明,合成数据中包含了对 DeepSeek-V3.2-Exp 和前沿闭源模型都具有挑战性的智能体任务: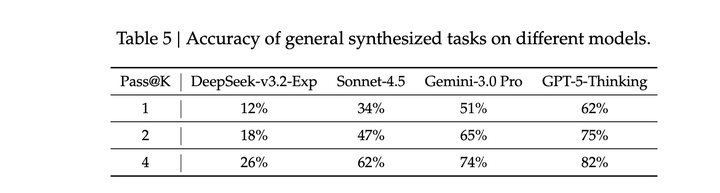
为探究基于合成数据的强化学习能否泛化到不同任务或真实世界环境,将强化学习应用于 DeepSeek-V3.2的SFT checkpoint,为排除CoT和其他强化学习数据的影响,仅在非思考模式下对合成智能体任务进行强化学习,将该模型与DeepSeek-V3.2-SFT和DeepSeek-V3.2-Exp进行比较,其中DeepSeek-V3.2-Exp 仅在搜索和代码环境中用强化学习训练。
如图所示,在合成数据上进行大规模强化学习,在Tau2Bench、MCP-Mark 和 MCP-Universe 基准测试中,相较于DeepSeek-V3.2-SFT有显著提升。相比之下,将强化学习限制在代码和搜索场景中,并未改善这些benchmark测试的性能,这进一步凸显了合成数据的潜力: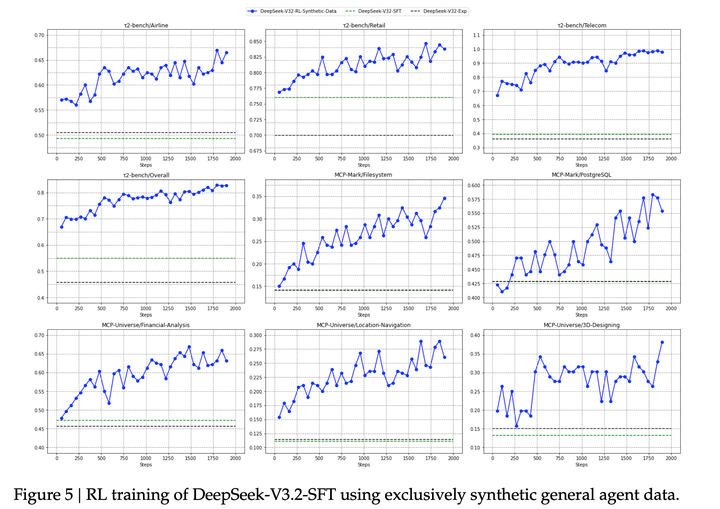
即便有128K 这样扩展后的上下文窗口,智能体工作流程(尤其是在基于搜索的场景中)仍经常遇到最大长度限制,从而过早截断推理过程。这一瓶颈阻碍了test-time compute潜力的充分发挥。为解决此问题,引入上下文管理,在测试时token使用量超过上下文窗口长度的 80% 时,采用以下策略:- Summary:总结溢出的轨迹并重新启动rollout过程;- Discard-75%:丢弃轨迹中前75%的工具调用历史以腾出空间;- Discard-all:通过丢弃所有之前的工具调用历史来重置上下文。
为作比较,还实现了一个Parallel-fewest-step策略,即采样N条独立轨迹并选择步骤最少的轨迹。
在BrowseComp benchmark上评估这些策略。如图所示,在不同的计算预算下,Context Management策略为执行额外的执行步骤提供更多空间,从而带来显著的性能提升: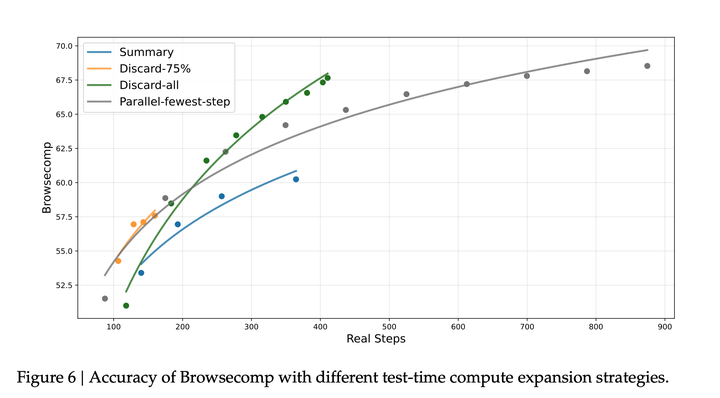
例如,summary策略将平均步骤从140扩展到364,性能从53.4 提升到60.2。不过,其整体效率相对较低。尽管Discard-all策略简单,但在效率和可扩展性方面表现良好,得分为67.6,与Parallel-fewest-step相当,同时使用的步骤显著更少。找到串行和并行扩展的最优组合,以最大化效率和可扩展性,仍是未来工作的关键方向。### 未来工作
与Gemini-3.0-Pro等前沿闭源模型相比,DeepSeek仍存在一定局限。首先,由于总训练浮点运算次数较少,DeepSeek-V3.2中的世界知识广度仍落后于领先的专有规模。DeepSeek计划在未来的迭代中,通过扩大预训练计算规模来弥补这一知识差距。其次,token效率仍是一个挑战;DeepSeek-V3.2 通常需要更长的生成轨迹(即更多token)才能匹配 Gemini-3.0-Pro 等模型的输出质量。未来的工作将聚焦于优化模型推理链的智能密度,以提高效率。第三,在解决复杂任务方面,仍落后于前沿模型,未来进一步完善基础模型和训练后流程。
Comments