
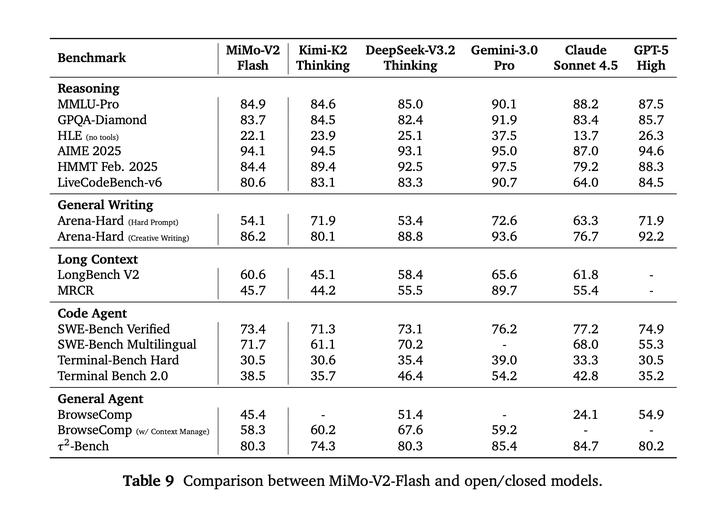
快速摘要: MiMo-V2-Flash是小米推出的MoE模型(309B总参数、15B激活参数),采用混合注意力架构将滑动窗口注意力与全局注意力以5:1比例交错,并集成MTP(Multi-Token Prediction)在27T token上进行预训练。后训练阶段提出Multi-Teacher On-Policy Distillation(MOPD)范式,通过领域专精的教师模型提供token级密集奖励。推理时MTP可作为speculative decoding的draft model,使用3个MTP层实现最高2.6倍解码加速。模型在智能体强化学习方面进行了大规模扩展,构建了涵盖代码调试、终端操作、网页开发等多样化训练环境。
论文MiMo-V2-Flash Technical Report
本文提出了MiMo-V2-Flash,是MoE模型,总参数为309B,激活参数为15B,旨在实现快速、强大的reasoning和agent能力。MiMo-V2-Flash采用混合注意力架构,将Sliding Window Attention (SWA)与全局注意力交错,在 5:1 的混合比例下,滑动窗口为128个token。该模型使用MTP在 27T个token上进行预训练,原生上下文长度为32k,随后扩展到 256k。为了高效scaling post-training,MiMo-V2-Flash 引入了Multi-Teacher On-Policy Distillation (MOPD)范式。在该框架中,领域专精的teacher模型(通过大规模强化学习训练)提供密集的、token-level的奖励,使student模型能够掌握teacher的专业知识。在推理过程中,通过将MTP重新用作speculative decoding的draft model,MiMo-V2-Flash使用三个MTP层时,可实现高达3.6的接受长度和2.6倍的解码加速。
本文分为模型架构、预训练、后训练、评估、推理加速等方面介绍MiMo-V2-Flash。### MiMo-V2-Flash Model Architecture
使用Hyprid Attention结构,由Local Sliding Window Attention (SWA)和Global Attention (GA)组成,它堆叠了 M = 8 个混合模块,每个模块的结构是先有N=5个连续的 SWA模块,随后是一个GA模块。唯一的例外是第一个Transformer模块,使用全局注意力和密集前馈网络(FFN),以稳定早期的表征学习。MiMo-V2-Flash中使用的滑动窗口大小 W为128。SWA模块和GA模块均采用稀疏MoE FFN。每个MoE层总共包含256个专家,每个token激活8个专家,不存在共享专家。
MiMo-V2-Flash 还集成了MTP,以提升模型性能(包括质量和效率)。MTP模块使用密集 FFN而非MoE,并且应用SWA而非GA,使其在投机解码时更加轻量化。每个MTP模块的参数数量仅为0.33B。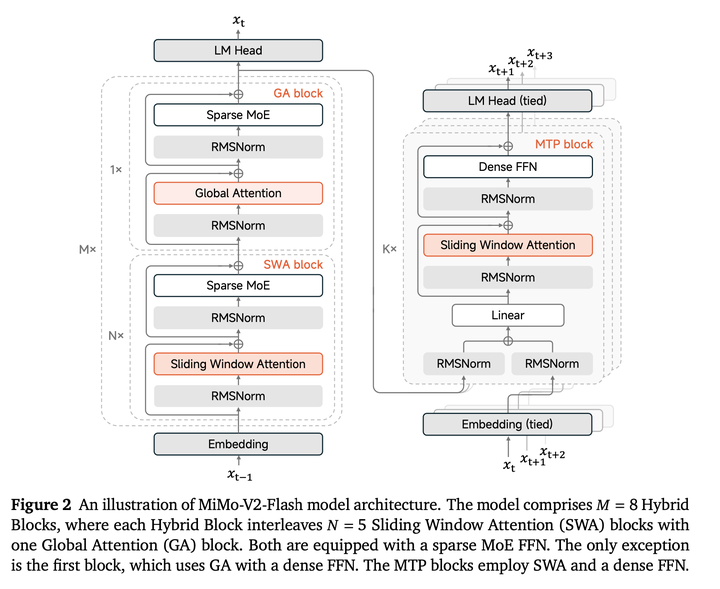
详细配置如下: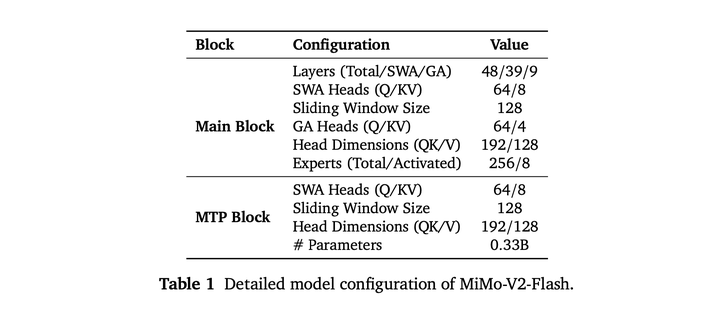
采用了与DeepSeek-V3类似的FP8混合精度框架。具体来说,对于attention output projections,以及嵌入和输出head参数,保留BF16精度,而对于MoE路由参数,维持FP32精度。这种混合精度配置在不显著影响训练效率或内存占用的情况下,提升了数值稳定性。
**Hybrid Sliding Window Attention Architecture:**learnable attention sinks bias显著提升了混合SWA模型的性能,达到甚至超越了全GA层的基线模型。
learnable attention sinks bias采用类似gpt-oss的设计:

模型架构评估对比,在32B dense模型上进行研究,进行pre-training和SFT: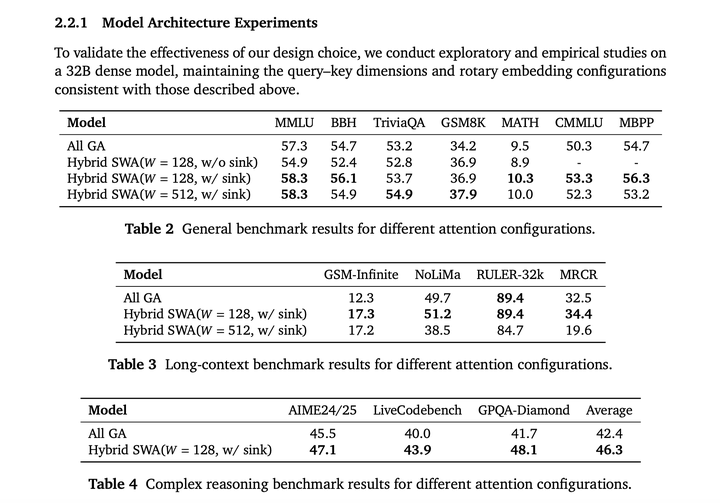
实验表明,混合SWA(窗口大小128)不仅优于混合SWA(窗口大小512),还能超越全 GA基线,这可能源于更好的正则化和有效的稀疏性。更小的窗口迫使模型关注局部上下文,减轻了对虚假模式的过拟合。此外,更紧凑的窗口(窗口大小128)促使SWA建模局部信息,同时将长距离依赖交给全局注意力层,从而实现更清晰的分工,学习更准确、高效。相比之下,更大的窗口(窗口大小512)可能会模糊这种区分,导致SWA部分处理长距离依赖,削弱局部和全局信息的分离,进而导致次优性能。
MTP:MTP能够提高训练效率。MiMo强调将MTP用作原生draft模型,来投机解码,从而在实际部署中加快速度。- **加快大语言模型解码速度:**MTP通过生成多个draft token来提高FFN和注意力的算术强度,主模型随后会并行验证这些draft token。这种方法能够实现token-level并行,且不会增加 KV 缓存的输入输出(I/O)。- **加快强化学习训练速度:**MTP加速特别适用于强化学习训练,MTP解决了强化学习训练中的两个关键问题:能实现小bsz情况下高效且有效的强化学习。当前的强化学习训练依赖大bsz、off-policy算法来最大化吞吐量。**On-policy策略通常更稳定、更有效,但小bsz会未充分利用GPU资源。MTP通过扩展token-level而非bsz大小来缓解这一限制,使小bsz、on-policy策略的强化学习训练更具实用性。**MTP也能缓解因长尾滞后项导致的GPU空闲问题。随着rollout阶段的推进,处理长序列且bsz小(通常接近1)的长尾滞后项会导致显著的GPU空闲。在这种情况下,MTP 提高了注意力和FFN的计算效率,大幅降低了整体延迟。
在MiMo-V2-Flash中,MTP模块特意设计得较为轻量,以避免其成为新的推理瓶颈。使用小型密集FFN而非MoE来限制参数数量,并采用滑动窗口注意力(SWA)而非全局注意力(GA)来降低KV缓存和注意力计算成本。在预训练期间,仅附加一个MTP头到模型,以避免额外的训练开销。在post-training,这个头会被复制K次,形成K步MTP模块,并且所有头会联合进行multi-step prediction。每个头都会接收主模型的隐藏状态和词元嵌入作为输入,从而提供更丰富的预测信息。### Pre-training
MiMo-V2-Flash的预训练语料库包含27T个token,来自各类高质量数据源,包括公共网络内容、书籍、学术论文、代码、数学资料以及更广泛的科学、技术、工程和数学(STEM)材料。数据处理流程遵循MiMo-7B的流程,同时刻意转向处理具有长程依赖关系的数据。着重关注长格式文档数据,并精心整理代码语料库,涵盖代码仓库级别的代码、拉取请求、问题和提交历史,以增强模型捕捉扩展后的上下文关系以及执行复杂多步推理的能力。
MiMo-V2-Flash的预训练分为三个连续阶段:- 阶段 1(pre-training,0-22 T token):模型在多样化、高质量的通用语料库上进行训练,使用32K的上下文长度,以建立强大的基础语言能力。- 阶段 2(mid-training,22-26 T token):通过上采样以代码为中心的数据,并纳入大约 5% 的合成推理数据来修改数据混合,进一步增强逻辑推理和程序合成能力。- 阶段 3(上下文扩展,26-27 T token):遵循阶段2的数据分布,将模型的上下文窗口扩展到256K,并上采样具有长程依赖关系的数据,从而能够更有效地对扩展上下文和长期推理进行建模。
模型超参数:包含48个Transformer层,其中有39 个滑动窗口注意力层和 9 个全局注意力层。隐藏维度设置为4096。除第一层外,所有层都配备MoE。每个MoE层包含256个路由专家,每个token激活8个专家,每个专家的中间隐藏维度为 2048。FFN层的中间隐藏维度设置为16384。所有可学习参数都使用标准差为0.006的标准正态分布随机初始化。预训练期间使用单个MTP层。
训练超参数:使用AdamW优化器,设置β1=0.9,β2=0.95,权重衰减为 0.1。应用梯度裁剪,最大范数为1.0。学习率调度分为两个阶段。在阶段1,学习率从0线性warm up到3.2×10−4,前500Btoken,随后在12 T token内保持为3.2×10−4,最后在 10 T token内余弦衰减到1.0×10−4。阶段2 从1.0×10−4开始,在 4 T token内余弦衰减到3.0×10−5。bsz在前 500 B token内从 0 warm up到2048,然后在两个阶段的剩余部分保持恒定。关于辅助loss,所有阶段的 MoE sequence辅助损失系数设置为1.0×10−5。在阶段1和阶段2,expert bias设置为 0.001。阶段1的MTP损失权重设置为0.3,阶段 2和阶段3设置为0.1。
长上下文扩展:在阶段 1,将预训练序列长度设置为32768,全局注意力(GA)的RoPE基频为640000,滑动窗口注意力(SWA)的为 10000。在阶段 3,序列长度扩展到262144,GA RoPE基频调整为5000000。阶段3的学习率从3.0×10−5衰减到1.0×10−5,遵循余弦调度,bsz固定为 256。阶段3的expert bias更新因子降低到1.0×10−5。### Pre-training评估
评估结果如下: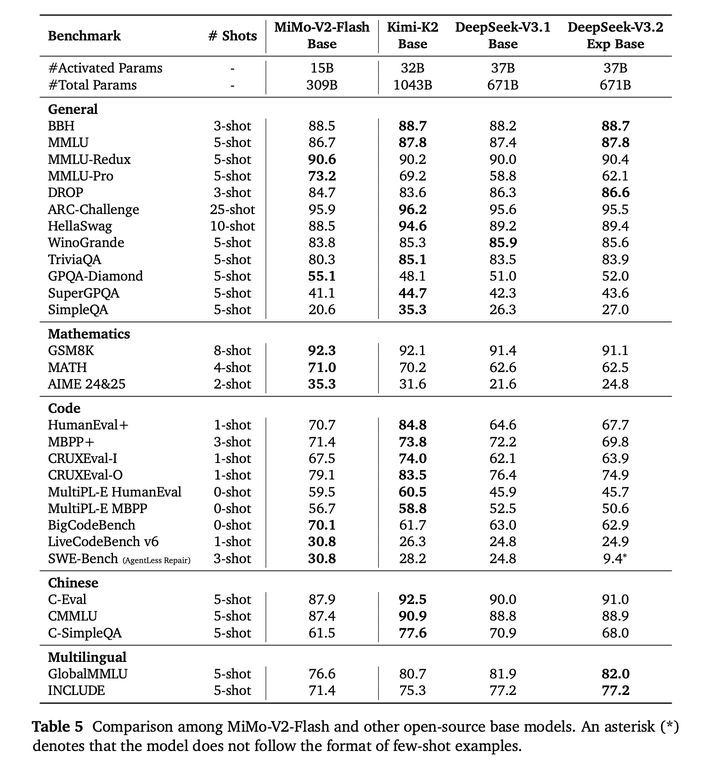
MiMo-V2-Flash-Base 在大多数benchmark测试中表现出竞争力,并且在推理任务(MMLU-Pro、GPQA-Diamond、AIME)上始终优于同类模型。然而,由于参数数量有限,与更大的模型相比,MiMo-V2-Flash的知识容量较低,这在SimpleQA中有所体现。
长上下文任务对比: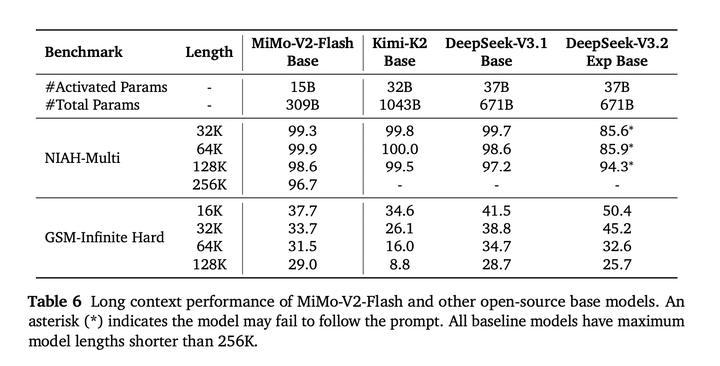
对于长上下文检索,在32K到256K的范围内实现了接近100% 的成功率。在极端压力的长上下文推理benchmark GSM-Infinite 上,MiMo-V2-Flash也表现出色,从16K到128K的性能下降极小。这些结果有力地证明了MiMo-V2-Flash的混合 SWA 架构、vanilla 32K预训练和上下文扩展训练的有效性和可扩展性。### Post-training
提出了Multi-Teacher On-Policy Distillation (MOPD)训练策略,包括SFT,各专项模型RL训练,Multi-Teacher On-Policy蒸馏三个阶段: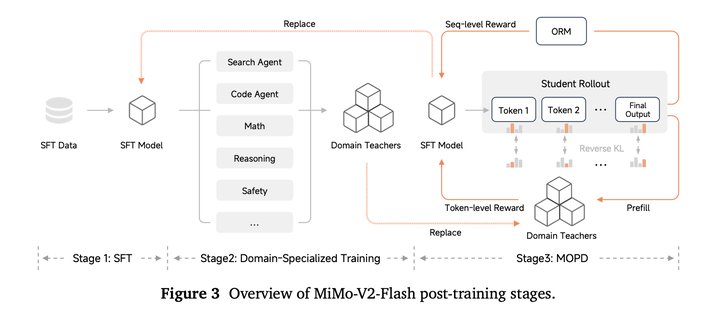
MODP训练的teacher和student对比: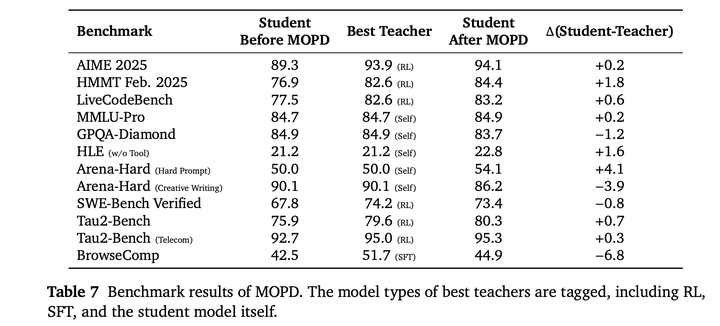
**SFT训练:**SFT数据包括通用对话、推理、编码和智能体任务。这些样本涵盖了思考模式和非思考模式,response由内部的领域专用模型checkpoints生成。
通过初步实验,确定了MoE SFT训练的一个关键稳定性指标:零梯度参数的数量(num - zeros)。num-zeros增加表明专家之间的负载平衡在恶化,而num-zeros减少则意味着模型对训练数据存在过拟合。因此,在整个训练过程中维持稳定的 num-zeros对SFT至关重要。此外,这种稳定性对于确保后续强化学习阶段的鲁棒性和收敛性也极为关键。
实验表明,num-zeros的稳定性关键取决于两个超参数:expert bias更新率和AdamW优化器中的ε参数。本文使用以下超参数配置训练:采用余弦衰减学习率调度,从5.0×10−5衰减到5.0×10−6,bsz大小为128,AdamW 的ε设置为1.0×10−8。MoE expert bias更新率设为1.0×10−4,sequence辅助loss系数设为1.0×10−6 。
各专项RL训练:
**非agent强化学习训练:**非智能体强化学习训练侧重于提升模型在单轮任务中的表现,这类任务中模型无需交互式反馈或多步执行就能生成完整回应。主要目标是在可验证领域(如数学、编码、逻辑)提高模型的推理准确性,同时在开放式对话中让其输出兼具帮助性与安全性。生成奖励信号的方法会依据任务特点而变。对于结果可验证的领域,采用混合验证系统,结合编程工具和大语言模型评判器,依据精心整理的问题-解决方案对自动评估正确性。对于帮助性和安全性等主观质量,实施基于评分标准的框架,由先进的大语言模型评判器根据详细评分标准和参考答案评估回应,生成细致的奖励信号,引导模型呈现期望的行为。
**agent强化学习训练:**智能体强化学习训练模型在需要规划、行动执行以及根据反馈适应的交互式多轮环境中运行。从环境多样性和计算资源两个关键维度对智能体强化学习进行scaling。
**scaling智能体环境多样性:**构建了多样的智能体训练环境,涵盖代码调试、终端操作、网页开发和通用工具使用等方面: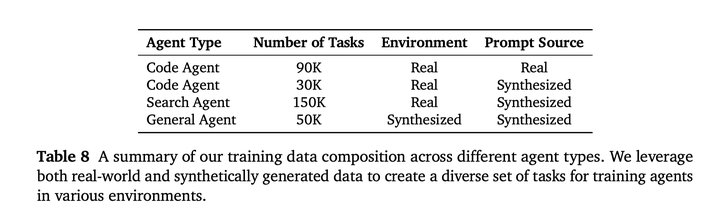
规模化智能体计算:在多样的智能体环境集合上进行训练,发现规模化智能体强化学习计算不仅能提升代码智能体的性能,还能有效推广到其他任务类型。下图展示了代码智能体的强化学习训练曲线,模型在约12万个环境中执行策略滚动和更新。这种规模化显著改善了基础模型在 SWE-Bench-Verified 和 SWE-Bench-Multilingual上的表现: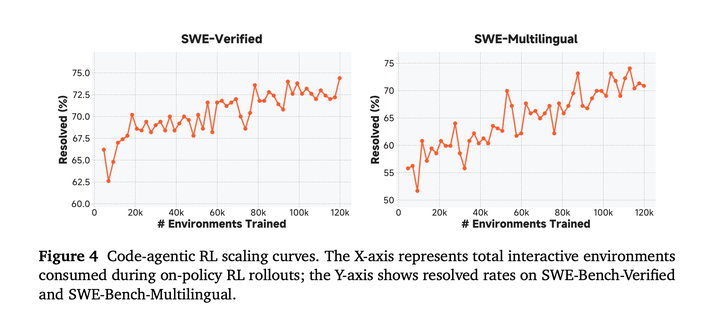
此外,大规模代码智能体强化学习训练能有效泛化到其他智能体任务: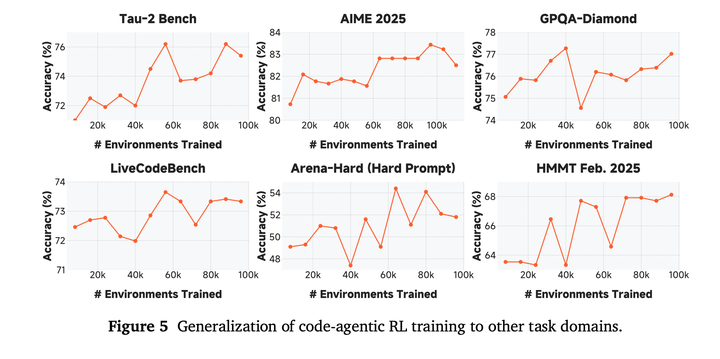
MODP训练:
计算专项模型和通用模型的reverse kl: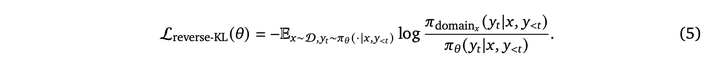
梯度为: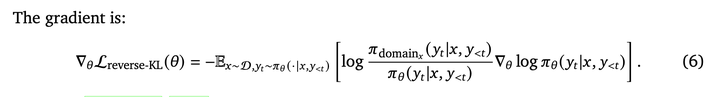
可应用train-infer mismatch的importance sampling和discard:
将reverse KL作为reward的一部分,加上outcome的reward:
带有outcome reward的效果会更好: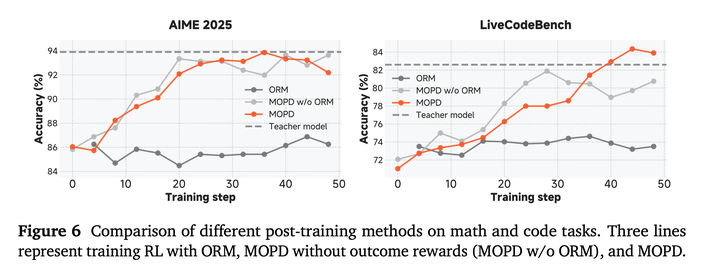
强化学习(包括MOPD)基建使用 SGLang作为推理引擎,使用Megatron-LM作为训练引擎。为实现稳定、高效且灵活的强化学习训练,实施了三个扩展模块:Rollout Routing Replay,数据调度,以及结合Toolbox的工具管理器。
Rollout Routing Replay(R3):由于数值精度问题,MoE模型在rollout和训练过程中,会因专家路由不一致而受到影响。R3使用来自rollout的相同路由专家进行强化学习训练,对于多轮智能体训练,在rollout期间采用request-level prefix cache。该cache存储来自先前轮次的KV cache和 MoE 路由专家,允许在同一请求的后续生成步骤中重复使用它们。与当前推理引擎中常用的cache不同,这里的请求级前缀cache避免了重新prefix或请求间输出cache共享,确保路由专家的采样一致性。
**数据调度器:**MiMo-V2-Flash扩展了Seamless Rollout Engine并实施了数据调度器,按细粒度序列(sequence)而非micro-batch进行调度,从而解决分布式MoE训练中GPU 空闲的问题。在动态采样过程中,当序列返回用于奖励计算时,会参考其历史pass rate,并在必要时为GPU分配新的prompt,以实现负载均衡。引入了partial rollout,将过长的轨迹拆分到多个训练step中,同时限制样本的staleness以及每个batch中partial样本所占的比例。通过对partial rollout采用staleness-aware truncated importance sampling,在不牺牲模型质量的前提下显著加速了RL训练。Data Scheduler支持按数据源定制的配置,包括:采样配额、调度优先级、长度限制和温度参数,并根据配置的比例、结合pass rate来接收样本。基于优先级的调度机制可以在不同时间模式的数据源之间重叠奖励计算与推理过程,从而保证GPU的高利用率。
**工具箱和工具管理器:**实施工具箱和工具管理器,以解决强化学习智能体训练中的全局资源竞争和局部低效问题。这些模块利用Ray进行高效调度。工具箱作为集中式资源分配器,为并发任务中的工具强制执行资源配额和QPS限制。采用容错的Ray actor池,消除冷启动延迟。工具管理器与工具箱集成,通过环境预暖和序列级异步奖励计算来加速训练。它通过超时恢复和实时监控维持训练稳定性。通过分离工具管理和rollout工作流,工具箱将特定任务逻辑与系统级策略隔离,在不影响稳定性的情况下实现模块化扩展。### MTP加速
分析了模型的预测不确定性(以下一token的交叉熵衡量)与多token预测(MTP)模块效率之间的关系: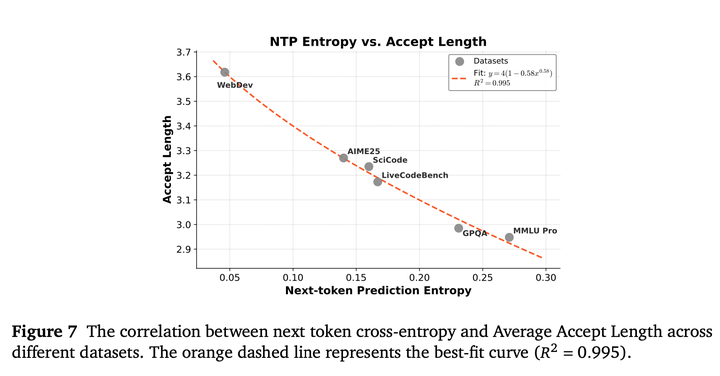
如图所示,记录了在多个benchmark上评估了使用3层MTP时的平均接受长度,涵盖从代码生成任务(如 WebDev、LiveCodeBench)到复杂推理任务(如 AIME25、MMLU Pro)。
结果显示二者存在显著的负相关关系:- 低熵上下文(如WebDev)允许更长的接受序列,最长可达约3.6个token;- 内在不确定性更高的任务(如MMLU Pro)由于预测分歧更大,其接受长度明显更短。
这一行为可以通过拟合函数准确建模:
表明下一token的交叉熵是决定MTP吞吐率的关键因素。
在MiMo-V2-Flash上评估了使用3 层MTP的解码加速效果,在不同的节点内batch size和接受长度下进行测试,输入长度为16K,输出长度为1K。
结果表明,在不增加任何硬件成本的情况下,MTP始终优于基线方法。值得注意的是,加速比与接受长度近似呈线性增长关系**:**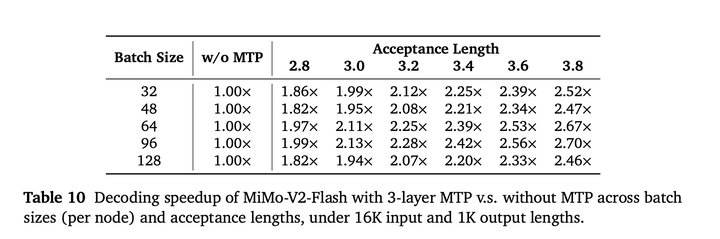
在不同 batch size下,MTP 的加速效果有所差异,这取决于对应的计算/I/O需求以及内核执行效率。
评论