
快速摘要: MiniMax-M1是基于Lightning Attention的MoE架构大模型,拥有456B总参数和45.9B激活参数,在MiniMax-Text-01基础上通过大规模强化学习训练而成。论文提出CISPO算法,通过对重要性采样权重进行裁剪而非token梯度更新裁剪,实现了2倍以上的训练加速。模型支持从40K到80K的分阶段长度扩展,并针对长上下文训练中的梯度爆炸和训练崩溃问题提出了早期截断等解决方案。MiniMax-M1与DeepSeek-R1和Qwen3-235B等强模型性能相当或更优,在复杂软件工程、工具利用和长上下文任务上具有特别优势。
论文MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
本文提出MiniMax-M1,MiniMax-M1使用MoE与lightning attention架构,在MiniMax-Text-01模型的基础上训练出来的,该模型总共有456B参数,激活45.9B参数。MiniMax-M1是在数学推理,软件工程等各种任务上,使用大规模强化学习进行训练的。除了lightning attention在RL训练中固有的效率优势外,本文还提出了CISPO,CISPO对重要性采样权重进行裁剪而非token梯度更新进行裁剪,可进一步提高RL效率。实验表明,MiniMax-M1与原始DeepSeek-R1和Qwen3-235B等强大的开源模型相当或更优,在复杂软件工程、工具利用和长上下文任务方面具有特别优势,同时FLOPs消耗更少。
MiniMax-M1在benchmark上的评估结果如下: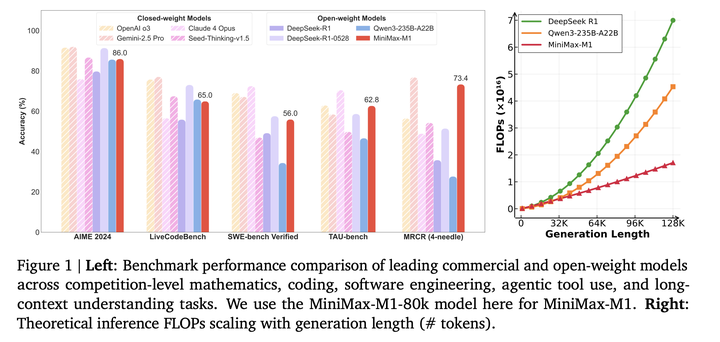
论文分别从Pre-Training和SFT,强化学习,训练数据,评估等角度介绍了MiniMax-M
的训练过程。### Pre-Training和SFT
首先对基础模型进行持续预训练,以增强其内在推理能力。之后进行冷启动SFT,让模型学会指定的推理模式。。
**持续预训练:**为了提高基础模型的推理和长上下文能力,同时确保多样性,使用额外的7.5T个token继续训练MiniMax-Text-01模型。- 数据:改进了此前抓取预训练数据的网页,PDF解析机制,并增强了启发式清理规则。从包括网页、论坛和教科书在内的各种来源提取QA对,同时避免使用合成数据。此外,对问答数据进行语义去重,以保持其多样性和独特性。将STEM,书籍和推理相关数据的比例提高到70%,增强基础模型处理复杂任务的能力。- 训练方案:降低了混合专家辅助损失的系数,并调整了并行训练策略以支持更大的训练bsz大小,从而减轻了辅助损失对整体模型性能的不利影响。基于MiniMax-Text-01,首先以8e-5的恒定学习率对2.5T个标记进行持续训练,随后在5 T个标记上对学习率进行衰减到8e-6。- 长上下文扩展:观察到训练长度的过度激进扩展可能导致训练过程中出现梯度爆炸。这是因为对于lightning attention,早期层和后期层具有不同的衰减率,这使得早期层更关注局部信息。通过更平滑地扩展上下文长度来解决这个问题,从32K的上下文窗口开始,逐步将训练上下文扩展到1M。
**SFT:**在持续预训练之后进行SFT,使用高质量样例CoT数据进行训练,数据样本涵盖数学、编码、STEM、写作、问答和多轮聊天等多个领域。数学和编码样本约占所有数据的60%。### RL
本文提出了CISPO算法,来提升RL阶段的训练效率。
原始GRPO算法如下所示:
GRPO使用PPO的clip的方式,对importance weight进行clip。然而对于那些表示转折分岔点的token来说,由于base模型中较少出现这样的词,对应的概率较低,因此在策略更新的时候会被裁剪掉,无法对策略梯度做出贡献。Clip higher等方法试图解决类似的问题,但是本文发现在MiniMax的base模型上用clip higher的效果较差。因此本文提出CIPSO算法。
原始的reinforce算法: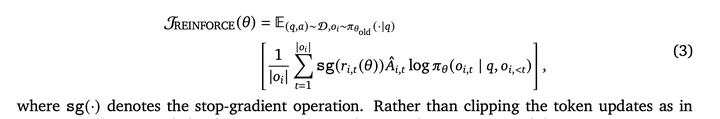
CIPSO只对importance weight进行clip,而不对log_prob进行clip,并且使用token-level的loss:
只对importance weight进行clip的方式会使所有的token都进入到训练中,保留策略梯度。
在此基础上对外层再进行额外的clip,去除掉ratio过高/过低的策略梯度,从而达到PPO on-policy更新的约束:
实验表明,CISPO的样本利用率较高,实现了2倍以上的训练加速: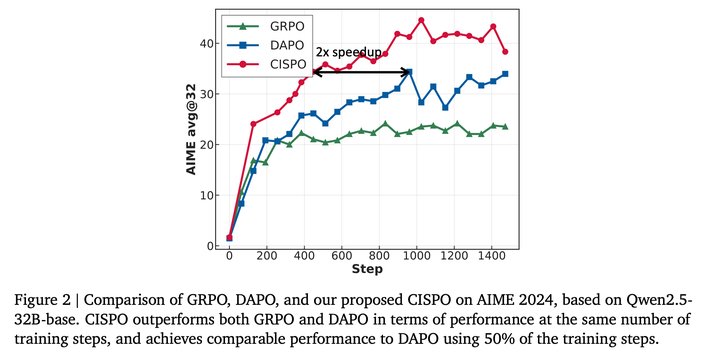
使用lightning attention时,需要将attention输出头的的精度提升到FP32,会使训练和推理之间的概率相关性大幅提高: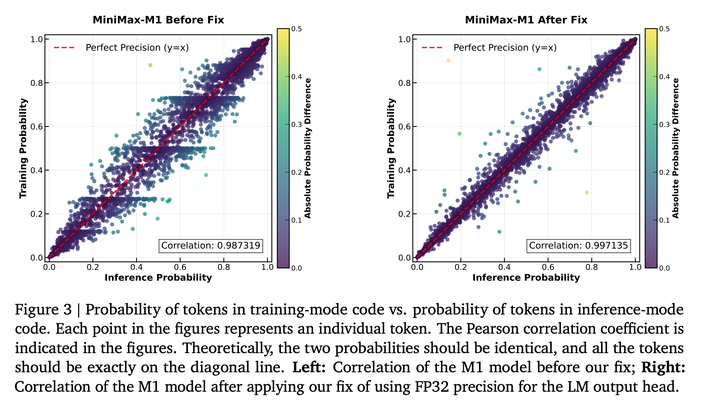
另外,本文发现了优化器超参数的敏感性。采用AdamW优化器,而β₁、β₂和ε的不当配置可能导致训练过程不收敛。使用VeRL的默认配置,其中beta = (0.9, 0.999)且eps=1e-8,可能会导致此类问题。基于此,本文设置β₁=0.9,β₂=0.95,且eps=1e-15。
**在强化学习训练过程中,复杂的prompt可能会导致长且重复的回答,其梯度在loss中占比较多会威胁模型的稳定性。本文提出的目标是抢先终止这些生成循环,而不是惩罚已经重复的文本。**实验中观察到,一旦模型进入重复循环,每个标记的概率就会飙升。因此,实施了一条早期截断规则:**如果连续3000个token的概率都高于0.99,则停止生成。**这种方法消除了这些病态的长尾情况,成功减少模型训练的不稳定性,并提高了生成吞吐量。### 训练数据
基于规则可验证场景的数据:使用基于规则的reward进行判断,并且加入了格式奖励。- 数学推理:数学数据集包含数十万个高质量竞赛级别的问题,这些问题是精心从公开来源和官方数学竞赛中挑选并整理的,涵盖了广泛的难度级别,每个问题都配有标准参考解答。数据清洗流程首先去除不完整的样本以及存在格式或排版错误的样本。随后在RL数据源上进行去重,并严格分离SFT数据集以避免数据泄露。此外,采用n-gram和基于嵌入的方法来消除常用数学基准测试集的潜在污染,从而确保评估的完整性和公平性。过滤掉包含多个子问题、基于证明的问题以及易受随机猜测影响的二元问题(例如,真/假问题)。将多项选择题重新表述为开放式格式,以更好地与强化学习框架保持一致。接下来,采用内部模型从参考解答中提取最终答案,仅保留那些提取的答案能被基于规则的答案检查器正确解析的样本。最后,使用一个强大的推理模型计算每个问题的pass@10,并仅保留通过率严格在0到0.9之间的样本,为强化学习提供包含近5万个高质量数学样本的数据集。- 逻辑推理:对于逻辑推理数据,精心挑选了41个需要非平凡推理能力的逻辑推理任务,如密码和数独,然后实现了一个数据合成框架来合成所有数据。使用SynLogic框架来实现数据合成流程,该流程具有特定任务的数据生成器和基于规则的任务特定验证器,从而实现自动逻辑数据生成。根据当前强大推理模型的可解性限制设定了一个上限难度边界,要求其pass@10大于零。同样,使用MiniMax-Text-01模型达到0到0.5之间通过率的最低难度参数来设定下限难度边界。此外,随着模型在训练过程中能力的提升,我们在后期阶段增加数据的难度。使用此框架,为强化学习训练合成了大约5.3万个逻辑推理样本。- 编程:从公开的OJ平台和流行的编程网站上收集公开可用的问题。对于缺乏测试用例的问题,开发了一个基于LLM的工作流程,并使用MiniMax-Text-01模型生成全面的测试用例。同样,最后会根据模型采样的通过率筛选出不同难度的问题,保留具有适度挑战性和高质量算法问题的样本。通过此过程,为强化学习训练生成了3万个编程数据样本。- 软件工程:对于软件工程领域,通过利用来自公共GitHub存储库的真实世界数据构建可验证的强化学习环境。数据集主要包括问题和PR,涵盖了常见的软件开发问题,包括错误定位、代码修复和测试用例合成。并且发了一个复杂的容器化沙盒环境,能够模拟真实的软件开发工作流程,执行实际代码,为智能体提出的干预措施提供直接且可验证的正确性和有效性反馈。预定义或新生成的测试用例的通过/失败状态作为强化学习框架的主要奖励信号。成功执行并通过所有相关测试用例会产生正奖励,而编译错误、运行时故障或测试用例回归则会导致零或负奖励。通过此过程,生成了数千个高质量数据样本。每个样本包括问题描述(例如,来自某个问题的错误报告)、初始错误代码和一组相关测试用例。
通用领域的数据:对于不易通过规则验证的数据,使用奖励模型来提供反馈。
通用强化学习数据集总共包含2.5万个复杂样本。这些样本大致可分为两类:具有答案但难以通过规则验证的样本,以及没有答案的样本。- 具有答案的任务:包括STEM和其他事实性问题,答案客观但可能有多种有效表达方式,这种多样性往往使基于规则的答案检查器不准确。数据清洗过程与数学推理中使用的类似,并且使用生成式奖励模型(GenRM)作为验证器。为了评估真实答案与模型响应之间的一致性,采用五级奖励来评估。首先,构建了一个人工标注的奖励模型benchmark,然后,通过比较GenRM选择的BoN回复与benchmark上的pass@N指标来评估GenRM的有效性。GenRM的性能通过其在人工标注benchmark上的准确性以及BoN与pass@N之间的性能差距来评估。- 没有答案的任务:此类涵盖更广泛的任务,包括指令跟随、创意写作等。尽管这些query通常是开放式的且没有真实答案,但会通过各种内部和外部模型生成response,然后这些参考答案将经过内部的质量评估。在强化学习训练期间,采用pair-wise的方式来评估模型。每次比较产生-1、0或1的分数,表明模型输出比参考答案更差、相似或更好。对于具有特定约束的指令约束的任务,会同时利用基于规则的奖励来评估response是否满足约束,并且用基于模型的奖励来评估response质量。为了尽量减少潜在的偏差,训练数据会通过多种方法进行优化,例如多盲一致判断、位置切换一致判断等。
长度偏差问题:建立了特定指标来检测强化学习策略是否病态地扩展输出长度以最大化GenRM奖励,而在最终效果上没有增益。在检测到这种有害的扩展长度的行为后,会触发GenRM的重新校准。
数据多样性:从具有基于规则奖励的推理密集型任务开始,然后逐渐融入通用领域任务。
长度扩展:首次强化学习训练是在输出长度限制为40 k个token的情况下进行的,在强化学习训练期间将生成长度进一步扩展到80 k个token。- 数据:为了高效地训练80 k长度的强化学习模型,利用之前训练的40 k长度模型来指导数据过滤过程,移除容易被解决的样本。然后调整数据分布,以支持更具挑战性的数学和编码问题。此外,在观察到合成推理数据会破坏长上下文强化学习训练后,对该类型的数据进行下采样。- 长度扩展策略:从40 k输出长度开始,逐步将其扩展到48 k,56 k、64 k、72 k,最终达到80 k。这种分阶段的方法确保了每一步的训练稳定性。向后续长度的过渡由一组经验指标决定。这些指标包括生成序列的困惑度收敛性,以及输出长度的第99个百分位数是否接近当前上下文窗口限制。这些信号为模型的扩展准备情况提供了有价值的见解,使我们能够在整个过程中保持稳健的训练。- 解决扩展过程中的训练不稳定性:在训练后期遇到训练崩溃的情况,即生成序列的后部分为不连贯或混乱的文本。实验确定了根本原因:在输出长度扩展过程中,负样本的长度增加速度远快于正样本,因此在生成序列的后部分积累了不成比例的大量负梯度。这种不平衡源于GRPO adv归一化的固有性质以token-level loss。为了解决这个问题,实施了三个关键解决方案:(1)检测重复模式(连续的高概率标记)并提前停止,以防止重复response过度消耗上下文窗口;(2)结合sample-level loss和token-level归一化,以缓解负-正样本不平衡并减轻不利影响;(3)降低梯度裁剪阈值以进一步稳定生成。### 评估
在数学、通用编码、软件工程、推理与知识、长上下文、智能体工具使用、事实性和通用助手能力等领域进行评估。使用temperature=1.0和top-p=0.95抽样对所有任务进行评估。实验结果如下: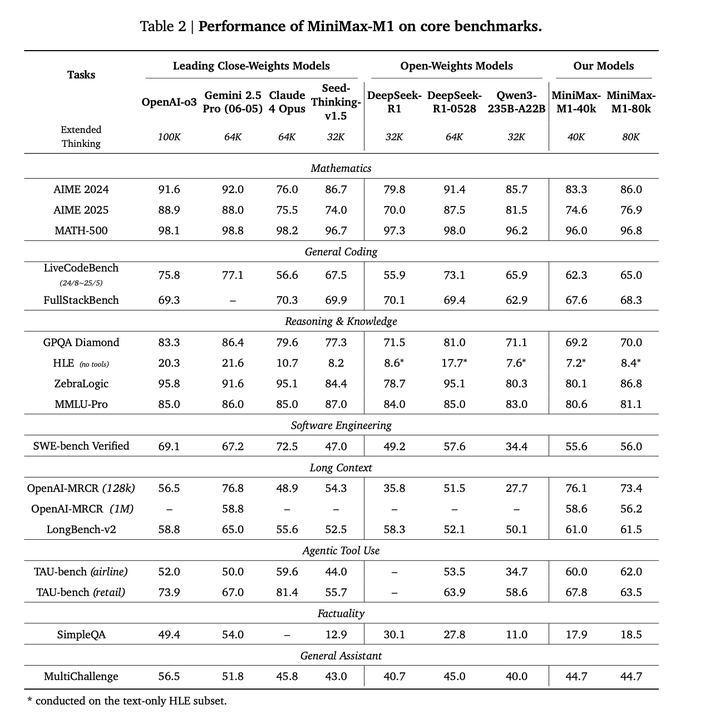
训练过程中,模型性能和长度呈正相关: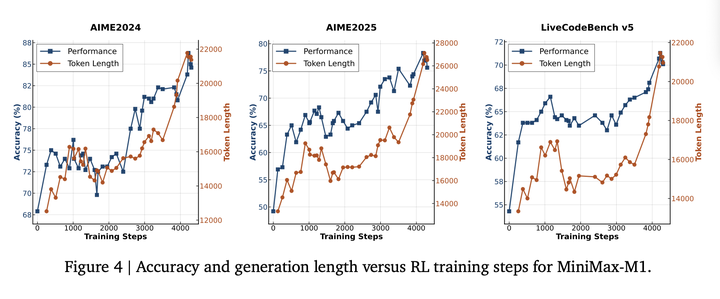
评论