

快速摘要: Kimi K2.5是月之暗面推出的开源多模态智能体模型,基于万亿参数MoE架构(1.04T总参数、32B激活参数),通过约15T混合视觉与文本token的大规模联合预训练完成迭代。核心技术包括原生多模态预训练(早期融合视觉与文本)、Zero-Vision SFT(仅用文本数据激活视觉智能体能力)、联合多模态强化学习等。此外,K2.5提出了Agent Swarm框架与PARL(并行智能体强化学习),通过动态任务拆解与并行子智能体调度,将推理延迟最高降低4.5倍,在代码生成、视觉理解、智能体任务等多领域取得SOTA表现。
论文Kimi K2.5: Visual Agentic Intelligence
本文提出Kimi K2.5,一款开源多模态智能体模型。K2.5聚焦文本与视觉模态的联合优化,实现双模态能力的相互增强,核心技术涵盖文本-视觉联合预训练、零视觉SFT、文本-视觉联合强化学习等一系列方案。同时,K2.5提出了**Agent Swarm,**一套自主式并行智能体编排框架,能够将复杂任务动态拆解为多个异构子问题并并行执行。
大量评估结果表明,Kimi K2.5 在代码生成、计算机视觉、逻辑推理、智能体任务等多个领域均取得了SOTA表现;与单智能体基线模型相比,Agent Swarm框架可将推理延迟最高降低4.5倍。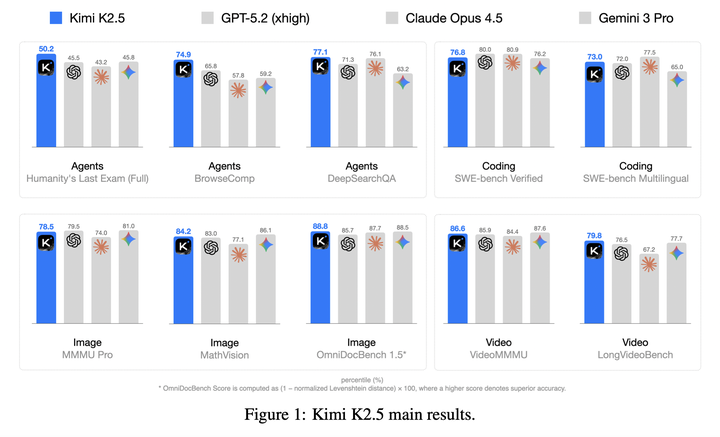
论文分别从文本与视觉的联合优化,Agent Swarm两个方面介绍K2.5的升级优化。### 文本与视觉的联合优化
Kimi K2.5是基于Kimi K2构建的原生多模态模型,通过约15 T混合视觉与文本token的大规模联合预训练完成迭代。
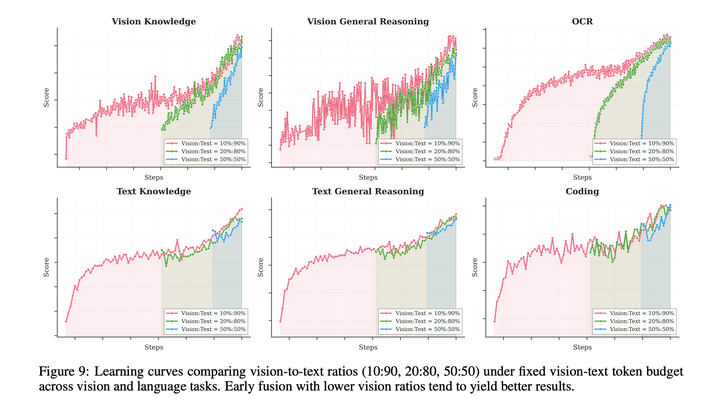
**原生多模态预训练:**多模态预训练的一个核心设计问题是:在视觉-文本token总预算固定的前提下,最优的视觉-文本联合训练策略是什么?传统认知认为,应在大语言模型训练的后期阶段,以高占比(如 50% 及以上)引入视觉token,以此加速多模态能力的习得,本质上是将多模态能力视为语言能力的事后附加项。
然而,本文的实验给出了截然不同的结论。在视觉与文本token总预算固定的前提下,通过改变视觉占比与视觉注入的时机开展了消融实验。为严格匹配不同占比的目标要求,先使用纯文本token对模型进行了特定计算量的预训练,再引入视觉数据。
本文发现视觉占比对最终的多模态性能影响极小。实际上,在视觉-文本token总预算固定的前提下,以更低的视觉占比实现早期融合,能取得更优的效果。这一发现推动了原生多模态预训练策略的诞生:并未在训练后期集中进行高占比的视觉训练,而是在训练早期就引入适中的视觉占比并贯穿训练全程,让模型自然地学习均衡的多模态表征,同时受益于双模态的长期联合优化。
**Zero-Vision SFT:**VLM并非天然具备基于视觉的工具调用能力,这给多模态强化学习带来了冷启动问题。传统方法通过人工标注或提示工程构建的CoT数据解决该问题,但这类方法的数据多样性有限,往往将视觉推理局限于简单图表和基础工具操作(裁剪、旋转、翻转)。
高质量的文本SFT数据相对丰富且具备多样性。本文提出了一种新颖的方法zero-vision SFT,**该方法在后训练阶段仅使用文本SFT数据,即可激活模型的视觉智能体能力。**在该方法中,所有图像操作均通过IPython中的程序化操作实现,本质上是对传统视觉工具使用方式的泛化。这种零视觉激活方式能够实现多样化的推理行为,包括通过二值化和计数实现物体尺寸估算等像素级操作,还可泛化至目标定位、计数、OCR等视觉锚定任务。
下图展示了强化学习的训练曲线,其训练起点均来自零视觉SFT。实验结果表明,零视觉 SFT足以激活模型的视觉能力,同时能保证跨模态的泛化性。这一现象很可能源于文本与视觉数据联合预训练机制。初步实验显示,与零视觉SFT相比,文本-视觉联合SFT在视觉智能体任务上的表现要差得多,这可能是由于缺乏高质量的视觉数据所致。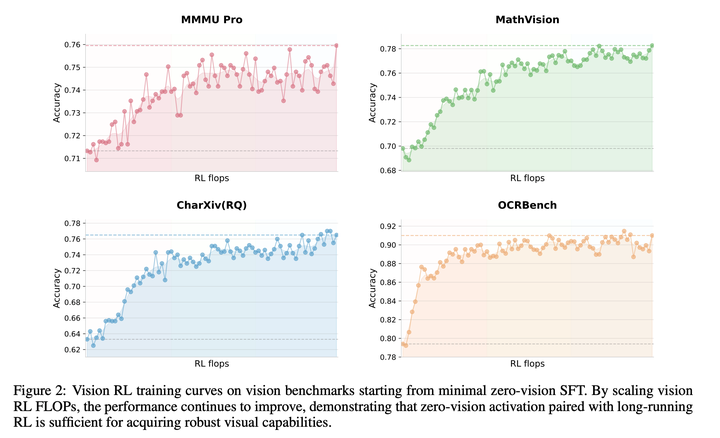
**基于结果的视觉强化学习:**在零视觉有监督微调之后,模型需要进一步优化,才能可靠地将视觉输入融入推理流程。仅依靠文本驱动的能力激活存在明显的失效场景:视觉输入有时会被忽略,模型无法在需要时关注到图像内容。本文在必须依赖视觉理解才能正确求解的任务上,采用了基于结果的强化学习。将这些任务划分为三大领域:- 视觉锚定与计数:对图像内的目标进行精准定位与数量统计;- 图表与文档理解:对结构化视觉信息进行解读与文本提取;- 强视觉依赖的STEM问题:经过筛选、必须通过视觉输入才能求解的数学与科学问题。
在这些任务上开展基于结果的强化学习,既能提升模型的基础视觉能力,也能优化更复杂的智能体行为。提取这些任务的执行轨迹用于RFT,可构建一套自优化的数据流水线,让后续的联合强化学习阶段能够利用更丰富的多模态推理轨迹。
**视觉强化学习可提升文本任务性能:**为探究视觉与文本性能之间潜在的权衡关系,在视觉强化学习前后,对模型在纯文本benchmark上的表现进行了评测。基于结果的视觉强化学习,让模型在文本任务上的性能取得了显著提升,包括 MMLU-Pro(84.7% → 86.4%)、GPQA-Diamond(84.3% → 86.4%)以及 LongBench v2(56.7% → 58.9%)。
分析表明,视觉强化学习提升了模型在结构化信息提取任务中的校准能力,降低了与视觉锚定推理(如计数、OCR)相似的查询的结果不确定性。这些发现证明,视觉强化学习能够促进跨模态泛化,在无任何语言能力退化的前提下,提升文本推理能力。
**联合多模态强化学习:**Kimi K2.5的后训练阶段采用了联合多模态强化学习范式。
与传统的按模态划分专属专家模块的方案不同,并非按照输入模态划分强化学习领域,而是按照能力维度划分,包括知识、推理、代码、智能体等。这些领域专家从纯文本和多模态查询中联合学习,同时生成式奖励模型(GRM)同样跨异构模态轨迹进行优化,不存在模态壁垒。该范式确保了模型通过文本或视觉输入习得的能力提升,能够天然地泛化并增强另一模态的相关能力,从而最大化跨模态的能力迁移效果。### Agent Swarm
现有的智能体系统,其推理与工具调用步骤的串行执行对于简单、短周期的任务或许有效,但随着任务复杂度提升、上下文累积量增加,其局限性会愈发凸显。当任务需要大规模信息收集与复杂的多分支推理时,串行系统往往会遭遇严重的性能瓶颈。单个智能体逐步骤执行任务的能力上限,会导致实际推理深度与工具调用预算快速耗尽,最终限制系统处理复杂场景的能力。
为解决这一问题,本文提出了智能体集群(Agent Swarm)与并行智能体强化学习(Parallel Agent Reinforcement Learning, PARL)。K2.5并不会将任务作为单条推理链执行,也不依赖预定义的并行化启发式规则,而是通过动态任务拆解、子智能体实例化、并行子任务调度来启动智能体集群。K2.5并不预设并行化天然具备优势;关于是否并行、何时并行、如何并行的决策,完全通过环境反馈与强化学习驱动的探索来显式学习。
如图所示,随着编排器在训练过程中不断优化并行策略,累计奖励平稳提升,模型的自适应并行能力也随之持续增强。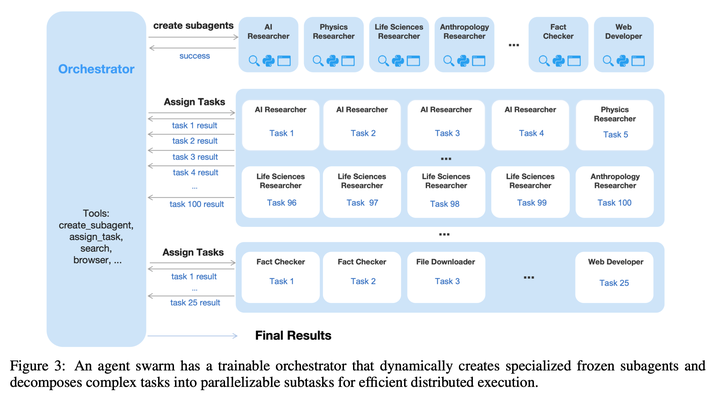
架构与学习设置:PARL框架采用解耦式架构,包含一个可训练的编排器,以及从固定的中间策略checkpoint实例化的、权重冻结的subagent。该设计刻意规避了端到端联合优化,从而解决两大核心难题:credit assignment模糊与训练不稳定。
在这种多智能体场景下,基于结果的奖励天然具有稀疏性与噪声特性:最终答案正确,不代表所有subagent的执行都完美无缺;同理,单次执行失败,也不意味着所有subagent都出现了错误。通过冻结subagent,并将其输出视为环境观测值、而非可微的决策节点,将高层级的协调逻辑与低层级的执行能力解耦,从而实现了更鲁棒的收敛。
为提升训练效率,先使用小体量的subagent训练编排器,再逐步切换至更大的模型强化学习框架还支持动态调整subagent与编排器的推理实例配比,从而最大化集群整体的资源利用率。
**PARL 奖励函数:**将 PARL 的奖励函数定义为: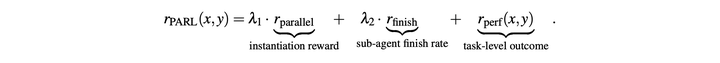
其中,性能奖励r_perf用于评估给定任务x对应的解决方案y的整体完成度与质量。在此基础上补充了两个辅助奖励,分别解决并行编排学习中的两类核心挑战:- 引入r_parallel奖励是为了缓解串行坍缩问题,即编排器退化为单智能体串行执行的局部最优解。该奖励项鼓励模型探索并发调度空间。- r_finish奖励则聚焦于已分配子任务的成功完成情况,用于防范虚假并行问题:这是一种奖励作弊行为,编排器会通过生成大量无意义任务拆解的subagent,来大幅拉高并行指标。通过为已完成的子任务提供奖励,rfinish约束了任务拆解的可行性,引导策略学习有效、合理的任务分解方式。
为确保最终策略围绕核心优化目标收敛,超参数λ1与λ2会在训练过程中逐步退火至 0。
critical steps作为资源约束:为衡量并行智能体场景下的计算时间开销,借鉴计算图中的关键路径概念,定义了关键步(critical steps)。将一个任务episode建模为以t=1,…,T为索引的执行阶段序列。在每个阶段中,主智能体执行一个动作。该动作既可以是直接的工具调用,也可以是实例化一组并行执行的子智能体。
一个任务episode的总关键步定义为: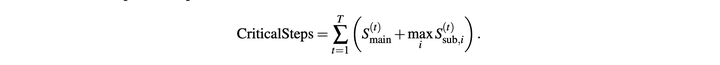
通过使用关键步而非总步数来约束训练与评测,该框架能够显式激励高效的并行化。**在该指标下,单纯创建大量子任务、而不缩短并行组的最长执行时间,几乎无法带来收益;而均衡的任务拆解能够缩短最长并行分支的耗时,直接减少关键步。**因此,该机制会引导编排器以最小化端到端延迟为目标,在子智能体间分配任务,而非单纯追求并发数或总执行工作量的最大化。
**并行智能体能力诱导的prompt构建:**为引导编排器利用并行化的优势,构建了一套合成prompt数据集,专门用于挑战串行智能体执行的能力上限。这些提示词主要分为两类:一类是广域搜索任务,需要同时探索大量独立的信息源;另一类是深度搜索任务,需要多分支推理,并在最后进行结果聚合。还加入了大量来自真实工作负载的任务,例如长上下文文档分析、大规模文件下载。
这些任务如果串行执行,很难在固定的推理步数与工具调用预算内完成。通过这样的prompt设计,能够引导编排器并行分配子任务,从而在更少的关键步内完成单串行智能体无法实现的任务。关键的是,这些prompt并不会显式指示模型进行并行化,而是通过任务分布的设计,让并行拆解与调度策略成为天然的最优解。### K2.5 method Overview
Base模型:Kimi K2.5的基座为Kimi K2,这是一款万亿参数量的MoE模型,基于15 T高质量文本token完成预训练。**Kimi K2 采用了MuonClip优化器,并搭配 QK-Clip 机制保障训练稳定性。**该模型总参数量达1.04 T,激活参数量为 32B,共包含384个专家,每token激活8个专家(稀疏度为 48)。
**模型架构:**Kimi K2.5的多模态架构由三部分组成:三维原生分辨率视觉编码器(MoonViT-3D)、MLP层,以及Kimi K2 MoE语言模型,整体遵循Kimi-VL确立的设计原则。
MoonViT-3D:Kimi-VL采用 MoonViT以原生分辨率处理图像,无需复杂的子图切分与拼接操作。MoonViT以SigLIP-SO-400M权重初始化,融合了NaViT的图像块打包策略:单张图像被切分为图像块、展平后,按顺序拼接为一维序列,从而能够高效地对不同分辨率的图像进行同步训练。为最大化图像理解能力的跨模态迁移,提出了MoonViT-3D,它具备统一的架构、全参数共享、一致的嵌入空间。将"分块 - 打包"的设计思想泛化到时序维度:最多4个连续帧被视为一个时空体,来自这些帧的二维图像块会被联合展平,并打包为一维序列,让完全相同的注意力机制能够在空间与时间维度上无缝运行。额外的时序注意力提升了模型对高速运动与视觉特效的理解能力,而参数共享则最大化了从静态图像到动态视频的知识泛化,实现了优异的视频理解性能,且无需引入专用的视频模块或架构分支。在进入MLP 投影层之前,轻量级时序池化会对每个时序块内的图像块进行聚合,实现 4 倍的时序压缩,大幅拓展了可处理的视频长度。最终形成了一套统一的流水线:图像预训练习得的知识与能力,通过单一的共享参数空间与特征表示,完整地迁移到视频任务中。
**预训练Pipline:**Kimi K2.5 的预训练基于 Kimi K2 语言模型checkpoint展开,分三个阶段处理了约 15 T token: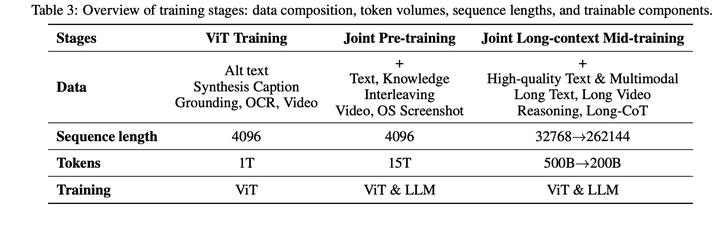
第一阶段,独立的ViT训练,构建鲁棒的原生分辨率视觉编码器;
第二阶段,联合预训练,同步增强语言能力与多模态能力;
第三阶段,针对高质量数据与长上下文激活的mid-training 优化,完善模型的图像与长上下文窗口能力。
**ViT 训练阶段:**MoonViT-3D基于SigLIP,在图像-文本、视频-文本配对数据上进行持续预训练,其中文本部分包含多种目标:图像替代文本、图像与视频的合成描述、定位边界框、OCR 文本。与Kimi-VL中的实现不同,本次持续预训练不包含对比损失,仅引入了基于输入图像/视频条件的字幕生成交叉熵损失。
采用两阶段对齐策略:第一阶段,通过caption loss,用1 T token、极低的训练 FLOPs,将 MoonViT-3D与Moonlight-16B-A3B完成对齐。该阶段让 MoonViT-3D 能够优先理解高分辨率的图像与视频。在极短的第二阶段,仅更新MLP投影层,打通ViT与1 T参数大语言模型的衔接,为后续更顺滑的联合预训练做准备。
**联合训练阶段:**联合预训练阶段基于接近训练完成的 Kimi K2 checkpoint,额外使用 15 T 4K 序列长度的视觉-文本token继续训练。该数据方案在 Kimi K2 预训练分布的基础上,引入了独特的token,调整了数据占比(提升了代码相关内容的权重),并控制了每个数据源的最大训练轮次。
第三阶段执行长上下文激活,融合了更高质量的训练中期数据,通过YaRN插值法逐步拓展上下文长度,显著提升了模型在长上下文文本理解与长视频理解上的泛化能力。### 后训练
**SFT:**遵循 Kimi K2确立的SFT流水线,通过K2 Thinking生成的高质量候选回复,以及一系列自研的内部专家模型,完成了K2.5的SFT迭代。数据生成策略采用了针对特定领域定制的专用流水线,将人工标注与先进的提示工程、多阶段验证相结合。该方法构建了大规模的指令微调数据集,包含多样化的提示词与复杂的推理轨迹,最终训练模型优先采用交互式推理,以及针对复杂真实世界应用的精准工具调用。
**RL:**强化学习是后训练流程的核心阶段。为实现文本与视觉模态的联合优化,同时为智能体集群提供PARL能力支撑,开发了一套统一的智能体强化学习环境,并对强化学习算法进行了优化。
RL采用如下损失函数:
该损失函数引入了token-level的裁剪机制,用于缓解训练与推理框架差异放大的off-policy问题。该机制通过简单的梯度mask方案实现:对于对数比率落在区间[α,β]内的token,正常计算梯度;对于超出该范围的token,梯度置零。与标准 PPO clip的关键区别在于,严格限制对数比率的上界与下界,无论裁剪符号的正负。经验表明,该机制对于需要长周期、多步工具调用推理的复杂场景的训练稳定性至关重要。采用MuonClip优化器来最小化该目标函数。
**奖励函数:**对于推理、智能体任务等具备可验证解的任务,采用基于规则的结果奖励。为优化资源消耗,还引入了预算控制奖励,用于提升token效率。对于通用任务,采用生成式奖励模型(Generative Reward Models, GRMs),提供与Kimi内部价值标准对齐的细粒度评估。
此外,针对视觉任务,设计了任务专属的奖励函数:- 对于视觉锚定与点位定位任务,采用基于软匹配的F1值奖励,其中锚定任务的软匹配通过交并比(IoU)计算,点位任务的软匹配通过高斯加权的最优匹配距离计算;- 对于多边形分割任务,将预测多边形栅格化为二值掩码,与真值掩码计算分割IoU,以此分配奖励;- 对于OCR任务,采用归一化编辑距离,量化预测结果与真值之间的字符级对齐程度;- 对于计数任务,奖励基于预测值与真值的绝对差值分配。
此外,合成了复杂的视觉谜题任务,并采用大语言模型验证器提供反馈。
**生成式奖励模型:**Kimi K2 针对开放式生成任务采用了自评判式的指标奖励,K2.5 则延续了这一技术路线,将GRM系统性地部署到更广泛的智能体行为与多模态轨迹场景中。在对话助手、代码智能体、搜索智能体、人工制品生成智能体等多样化场景中,将GRM叠加在已验证的奖励信号之上。
GRM并非二元的评判器,而是细粒度的评估器,与Kimi的用户体验核心价值对齐,包括有用性、响应及时性、上下文相关性、细节详略得当、生成的美学质量,以及对指令的严格遵循。该设计让奖励信号能够捕捉到纯基于规则或任务专属验证器难以编码的、精细化的偏好梯度。为缓解奖励作弊与对单一偏好信号的过拟合,采用了多套针对不同任务场景定制的GRM评判指标。
**token高效强化学习:**token效率是支持test time scaling的核心指标。test time scaling本质上是以计算量换取推理质量,而要获得实际的性能增益,需要通过算法创新主动平衡这一权衡关系。此前的研究发现,施加与问题匹配的token预算,能够有效约束推理阶段的计算开销,激励模型生成更简洁的思维链推理模式,避免无意义的token膨胀。但同时也观察到一种长度过拟合现象:在严格的预算约束下训练的模型,往往无法泛化到更高的计算量级;最终模型无法利用推理阶段额外的token预算解决复杂问题,只会退化为截断式的推理模式。
本文提出了Toggle,一种在推理时缩放优化与预算约束优化之间交替执行的训练启发式方法。对于第t轮训练迭代,奖励函数定义如下:
其中λ和m为算法的超参数,K为单个问题的采样轨迹数。具体而言,该算法每经过m轮迭代,就会在两个优化阶段之间切换:- 阶段 0(预算受限阶段):训练模型在任务匹配的token预算内解决问题。为避免模型为了效率过早牺牲效果,该约束为条件生效:仅当模型在给定问题上的平均准确率超过阈值λ时,才会强制执行该预算约束。- 阶段 1(标准缩放阶段):允许模型生成不超过最大token上限的回答,激励模型利用更多计算资源实现更优的推理时缩放效果。
与问题匹配的预算,是从正确回答子集的token长度的ρ分位数估算得到:
该预算在训练开始时完成一次估算,之后保持固定。
在 K2 Thinking上验证了 Toggle 的有效性。如图所示,在所有基准测试中均观察到输出长度的持续下降。平均而言,Toggle将输出token数减少了25%~30%,同时对模型性能的影响可忽略不计。同时,思维链中的冗余模式(如重复验证、机械计算)显著减少。此外,Toggle展现出了极强的领域泛化能力:例如,仅在数学与编程任务上训练的模型,在 GPQA和MMLU-Pro基准测试中,依然实现了token数的持续下降,且性能仅出现轻微衰减。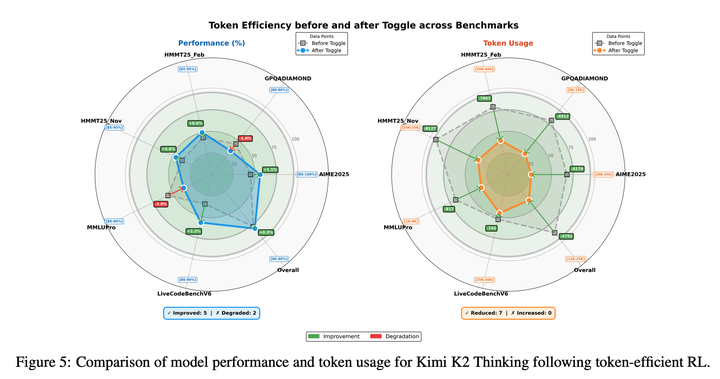
Kimi K2.5继承了Kimi K2的训练基础设施。针对多模态训练,提出了解耦编码器流程(Decoupled Encoder Process, DEP),将视觉编码器融入现有流水线的同时,的额外开销可忽略不计。
DEP:在采用流水线并行的典型多模态训练范式中,视觉编码器与文本嵌入层被共同部署在流水线的第一阶段(Stage-0)。然而,由于多模态输入本身存在尺寸差异(如图像数量、分辨率不同),Stage-0 的计算负载与显存占用都会出现剧烈波动。这迫使现有视觉-语言模型为多模态训练定制专属的流水线并行配置。这种折中方案虽能缓解显存压力,但无法从根本上解决多模态输入尺寸差异带来的负载不均衡问题。更关键的是,它还导致无法直接复用已为纯文本训练深度优化的并行策略。
K2.5利用视觉编码器在计算图中的独特拓扑位置,在训练中采用了DEP,每个训练步分为三个阶段:- 均衡视觉前向传播:首先对全局batch内的所有视觉数据执行前向传播。由于视觉编码器体量较小,无论采用何种其他并行策略,都会在所有GPU上部署该编码器的副本。在此阶段,会基于负载指标(如图像数量或图像块数量),将前向计算负载均匀分配到所有GPU上,彻底消除流水线并行与视觉token数量差异带来的负载不均衡问题。为将峰值显存占用降至最低,会丢弃所有中间激活值,仅保留最终的输出激活值,最终将结果汇总回流水线并行第0阶段(PP Stage-0)。- 主干网络训练:该阶段对Transformer主干网络执行前向传播与反向传播。由于前一阶段已丢弃中间激活值,此时可以完全复用所有在纯文本训练中经过验证的高效并行策略。该阶段结束后,梯度会在视觉编码器的输出端完成累积。- 视觉重计算与反向传播:重新执行视觉编码器的前向传播,随后执行反向传播,计算视觉编码器参数对应的梯度。
DEP不仅实现了负载均衡,还将视觉编码器与主干网络的优化策略完全解耦。K2.5无缝继承了K2的并行策略,其多模态训练效率可达纯文本训练的90%。同期研究工作LongCat-Flash-Omni采用了相似的设计理念。### 评估
在一系列全面的benchmark测试集上对Kimi K2.5 进行了评估,覆盖文本推理、竞技性代码生成、多模态理解(图像与视频)、自主智能体执行、计算机使用能力等多个维度。benchmark测试分类遵循以下能力维度:- 推理与通用能力: HLE、AIME 2025、HMMT 2025(2 月)、IMO-AnswerBench、GPQA-Diamond、MMLU-Pro、SimpleQA Verified、AdvancedIF、LongBench v2。- 代码能力:SWE-Bench Verified、SWE-Bench Pro、SWE-Bench Multilingual、Terminal Bench 2.0、PaperBench(CodeDev)、CyberGym、SciCode、OIbench(cpp)、LiveCodeBench(v6)。- 智能体能力:BrowseComp、WideSearch、DeepSearchQA、FinSearchComp(T2&T3)、Seal-0、GDPVal。- 图像理解: (math & reasoning) MMMU-Pro, MMMU (val),CharXiv (RQ), Math-Vision and MathVista (mini); (vision knowledge) SimpleVQA,WorldVQA; (perception),ZeroBench (w/ and w/o tools), BabyVision, BLINK ,MMVP; (OCR & document) OCR-Bench, OmniDocBench 1.5 ,InfoVQA。- 视频理解:VideoMMMU、MMVU、MotionBench、Video-MME、LongVideoBench、LVBench。- 计算机使用能力:OSWorld-Verified、WebArena。
评估设置:Kimi K2.5 的所有评测均采用以下配置:temp=1.0,top-p=0.95,上下文长度 256k token。所有无公开可用分数的基准测试,均在完全相同的设置下重新评估。
评估结果如下: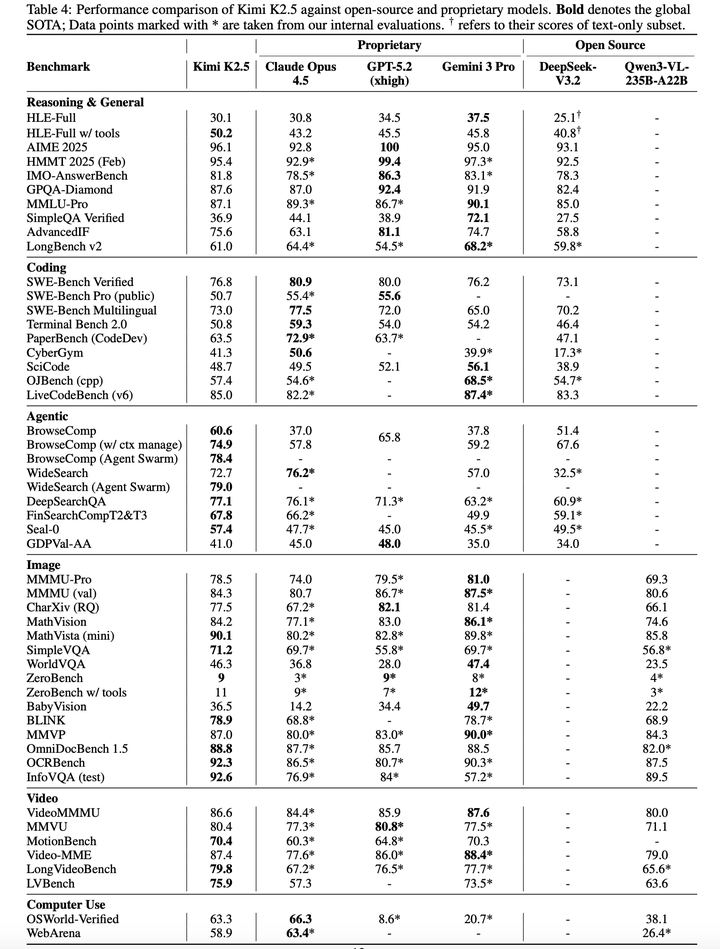
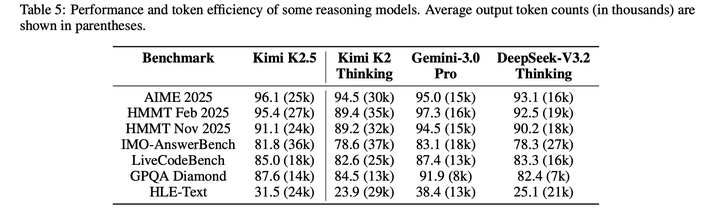
**Agent Swarm评测结果:**为严谨地验证Agent Swarm的有效性,选取了3个代表性benchmark测试,覆盖深度推理、大规模检索、真实场景复杂度三大维度:- BrowseComp:一项极具挑战的深度研究benchmark,需要多步推理与复杂的信息合成能力。- WideSearch:专为评估跨多源信息的广域、多步信息检索与推理能力设计的benchmark。- 自研 Swarm benchmark:内部开发的智能体benchmark,用于评估真实世界高复杂度场景下的智能体集群表现,覆盖四大领域:WildSearch(无约束的全网真实信息检索)、Batch Download(大规模多样化资源获取)、WideRead(超 100 个输入文档的大规模文档理解)、Long-Form Writing(超 10 万字的长文本连贯生成)。该基准包含极端规模的场景,可对智能体系统的编排能力、可扩展性、协调能力进行压力测试。
下表展示了Kimi K2.5 agent swarm,与单智能体配置、闭源基线模型的性能对比。结果证明,多智能体编排带来了显著的性能提升:
agent swarm能够有效地将计算并行性转化为定性的能力增益,尤其适用于需要广域探索、多源验证、并行处理独立子任务的场景。
并行带来的执行时间节省:除了任务性能的提升,agent swarm通过并行子智能体执行,实现了墙钟时间的大幅降低。在WideSearch 基准上,与单智能体基线相比,它将达到目标性能所需的执行时间缩短了 3~4.5 倍。
如图所示,这种效率增益会随任务复杂度提升而扩大:当目标条目级F1从 30% 提升至 70% 时,单智能体的执行时间从基线的约 1.8 倍增长至 7.0 倍,而agent swarm始终保持接近恒定的低延迟,仅为基线的 0.6~1.6 倍。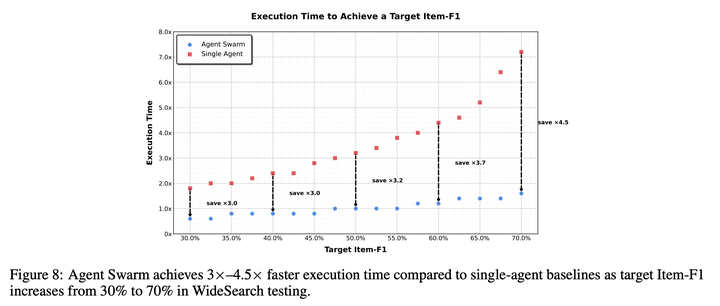
这些结果表明,agent swarm能够有效地将串行工具调用转化为并行操作,避免了任务难度提升时,完成时间通常出现的线性增长。
动态子智能体创建与调度:在智能体集群中,子智能体是动态实例化的,而非预定义的。通过PARL,编排器能够学习自适应策略,针对不断变化的任务结构与问题状态,创建并调度自主运行的子智能体。
与静态拆解方法不同,这种学习到的策略让编排器能够基于查询,推理所需的子智能体数量、启动时机与专业方向。最终,这种自适应分配策略会自然地形成异构的智能体群组。
作为主动上下文管理的智能体集群:除了更优的性能与运行时加速,多智能体架构支撑的智能体集群,本身也是一种主动、智能的上下文管理机制。这种方法与推理时上下文截断策略有本质区别:这类策略通过压缩或丢弃累积的历史记录来应对上下文溢出,虽然能有效减少token用量,但本质上是被动响应式的,往往会牺牲结构信息或中间推理过程。
与之相反,agent swarm通过显式编排,实现了主动的上下文控制。长周期任务会被拆解为并行、语义隔离的子任务,每个子任务由专用的子智能体在有限的本地上下文内执行。
关键的是,这些子智能体维护独立的工作内存,执行本地推理时,不会直接修改或污染中心编排器的全局上下文。只有与任务相关的输出(而非完整的交互轨迹)会被选择性地回传给编排器。这种设计实现了上下文分片,而非上下文截断,让系统能够在额外的架构维度上扩展有效上下文长度,同时保留模块性、信息局部性与推理完整性。
如图所示,在BrowseComp基准上,这种主动策略在效率与准确率上均超越了全丢弃策略。通过在编排器层面保留任务级连贯性,同时严格限制子智能体的上下文边界,agent swarm实现了带选择性上下文持久化的并行执行,仅保留高层级协调信号或关键中间结果。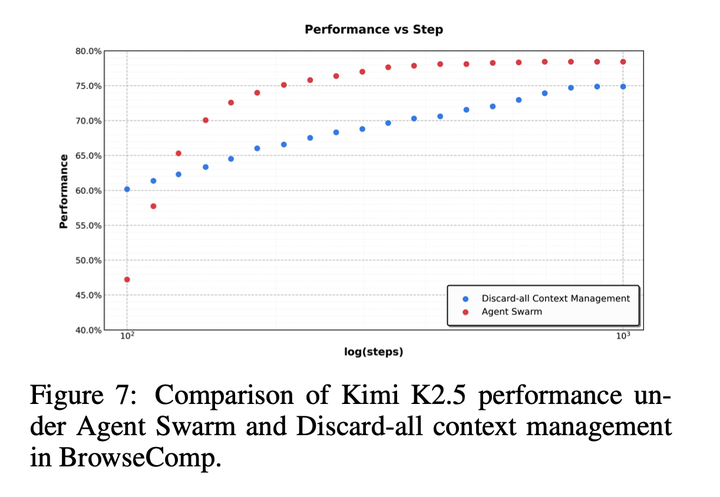
因此,agent swarm相当于一个主动、结构化的上下文管理器,相比统一的上下文截断,它能用显著更少的关键步实现更高的准确率。
Comments