
快速摘要: Ring-1T是首个万亿级参数的开源思考模型,采用MoE架构(1T总参数,激活50B),在AIME-2025上达到93.4分、CodeForces 2088分,并在IMO-2025获得银牌。针对万亿参数模型强化学习训练中的训推不一致、rollout效率低下和系统瓶颈问题,论文提出了三项核心创新:IcePoP算法通过token-level的mask和clip稳定RL训练,C3PO++通过动态分区提高长尾生成的资源利用率,ASystem高性能框架解决了大规模分布式RL训练的系统瓶颈。训练流程采用三阶段范式(Long-CoT SFT、reasoning-oriented RL、general-oriented RL),在开源模型中处于领先地位。
论文Every Step Evolves: Scaling Reinforcement Learning for Trillion-Scale Thinking Model
本文提出Ring-1T,首个具有万亿级参数的开源思考模型,采用MOE架构,总共有1 T参数,激活50B参数。在万亿参数规模下训练模型会有训练与推理之间的不匹配、rollout处理效率低下以及强化学习系统的瓶颈问题。为了解决这些问题,本文提出了三项创新:(1)IcePop通过token-level的mask和clip来稳定强化学习训练,减少训练与推理不一致带来的不稳定性;(2)C3PO++通过动态分区提高固定token预算下长尾生成的资源利用率;(3)ASystem是一个高性能强化学习框架,能够克服阻碍万亿参数模型训练的系统瓶颈。Ring-1T在benchmark测试中取得了突破性成果:在AIME-2025上得分为93.4,HMMT-2025上为86.72,CodeForces上为2088,ARC-AGI-v1上为55.94,在IMO-2025上获得了银牌。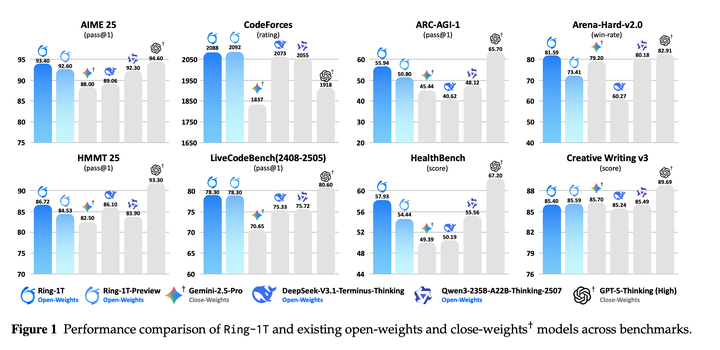
论文分别从训练方法,基建,评估等角度介绍了Ring-1T的后训练过程。### 训练流程
Ring-1T的训练包括三个阶段,包括Long-CoT SFT,reasoning-oriented RL和general-oriented RL: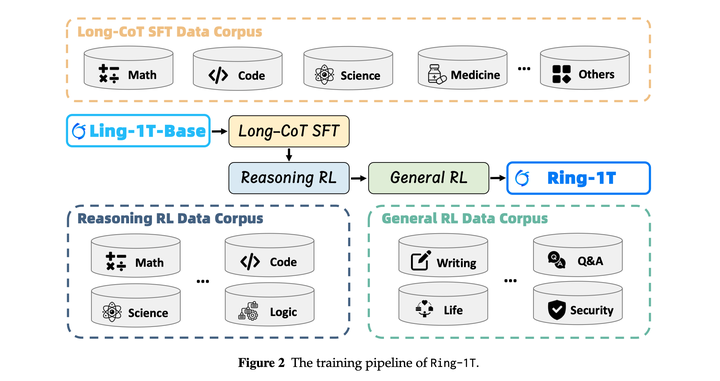
在这一阶段,旨在通过Long-CoT SFT赋予基础模型基本的长链推理能力。这一过程为后续的强化学习奠定基础,使其具备在复杂问题上维持连贯、多步骤思维过程的能力。
数据收集:构建了一个具有长思维链推理模式的综合高质量数据集,以有效激活base模型的推理能力。query来源于开源存储库、专家手动生成和基于LLM的合成。为确保所得数据集的质量,设计了一个严格的数据处理流程,包括四个顺序步骤:1)去重,采用精确匹配去除重复样本;2)有害内容过滤,识别并清除包含有毒或有害信息的数据样本;3)数据去污,利用哈希和精确字符串匹配技术检测并消除与现有benchmark重叠的任何样本;4)低质量样本过滤,去除包括不可见控制码和无关Unicode字符等各种噪声源。最终数据主要由四个领域组成:数学(46%)、STEM(26%)、代码(20%)和其他(8%)。
训练:对Ling-1T-base模型进行长思维链监督微调,以获得具有初步思维能力的模型。训练数据packing成长度为64k的序列。在此阶段,模型以2×10⁻⁴的学习率训练3个epoch。采用带有30个warm up step的cosine decay scheduler,并在整个过程中应用0.1的权重衰减。### Large Scaling RL
数据收集:数据涵盖五个核心领域:数学、代码、科学、逻辑和通用领域:- 数学:扩展了Ling-Team数据集,加入了来自权威人士的严谨数学问题。- 代码:除了Ling-Team使用的数据集外,还开发了一个多阶段工作流程,用于综合、验证、质量评分和选择额外的测试用例。此过程确保每个问题都配备足够数量的高质量测试用例。最终数据集包含具有经过验证的正确解决方案和经过仔细测试的案例的编程问题。- 科学:开发了一个涵盖物理、化学和生物学的高难度问题的众包科学数据集。为确保强化学习的复杂性,所有多项选择题被重新格式化为开放式格式。最后,应用通过率过滤策略,仅选择最高质量的题目。- 逻辑:逻辑推理数据集涵盖五个领域:visual pattern induction,grid puzzles,pathfinding (mazes), arithmetic reasoning (24 Game), 和propositional logic (Knights and Knaves)。会进行质量控制,确保每个任务在生成和后处理过程中都是可解且非平凡的。最终策划的集合在领域和复杂度上保持平衡,以用于强化学习。- 通用数据:整合了已有的通用数据集,包括Magpie、WMT、RLVR-IFEval和AutoIF。为增强实际对齐,进一步整合了真实用户偏好数据,如 arena-human-preference-100k和 arena-human-preference-140k 。此外,从知乎和StackOverflow等社交媒体平台获取了数据。
最后,采用了一个多阶段的流水线处理,包括解析、重新格式化和去重,并通过大语言模型的双重评分系统和基于规则的指标来保证质量。此外,会在每个样本上进行细粒度数据标注,来实现动态采样和跨领域的数据混合,来提高训练效率以及模型在复杂任务上的表现。
IcePoP:由于推理引擎和训练引擎的不一致,以及MoE模型动态路由的设计,MoE的RL会受到训推不一致的稳定性影响。本文提出IcePoP算法,用重要性采样的方式来修正训推的不一致性,并且用mask的方式来去除掉训推不一致的数据: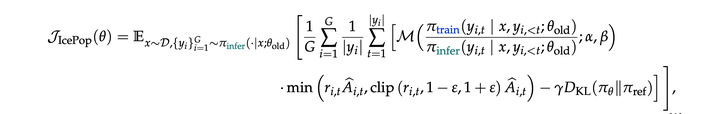

IcePoP以及类似的算法TIS可以参考blog https://ringtech.notion.site/icepop#271c8705a032809cb68eef1c9d2ba52d,https://yingru.notion.site/When-Speed-Kills-Stability-Demystifying-RL-Collapse-from-the-Training-Inference-Mismatch-271211a558b7808d8b12d403fd15edda
**C3PO:**本文提出C3PO++的训练方式,动态切分生成过程,以防止因个别长尾生成导致计算资源闲置。系统包含两个模块:一个是高吞吐量推理池,用于并行生成;另一个是训练池,用于收集完成的轨迹。通过token预算来控制生成,稳定训练更新并实现高效的推理过程。推理引擎通过并行生成来填充推理池,同时实时跟踪生成的token累计数。当生成到达终止状态时,数据会从推理池移至训练池,并计入训练token数,推理过程持续到达到token预算。此时,训练引擎利用训练池token预算数量已完成轨迹来更新参数。在每次迭代中,未完成的样本会继续推理,同时保留期会自动加 1。在每次迭代前,保留期超过阈值的数据会从推理池中清除。同时,会采样新的query来填充推理池,直到其达到容量。具体流程如下: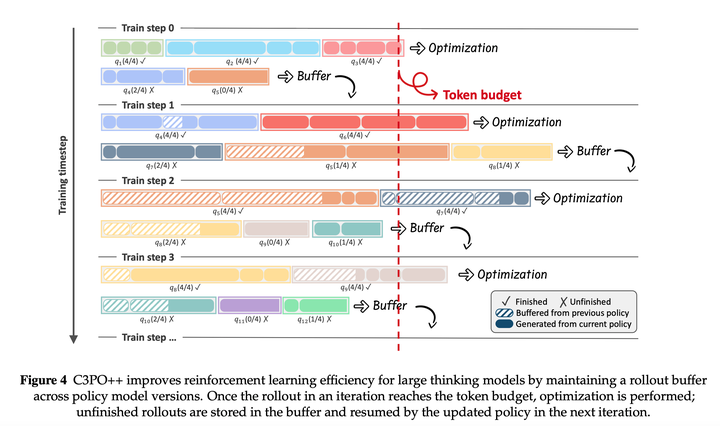
伪代码如下:
所有策略优化均通过ASystem框架执行,使用AdamW优化器,超参数为β1=0.9、β2=0.999,权重衰减为0.01,且MoE路由偏置保持固定。推理数据强化学习阶段,学习率为2×10−6,KL 系数为 0.0,采样温度为 1.0。每个训练step使用 480 个query,每个query采样 8 次,最大长度为 64k。在通用强化学习阶段,学习率为3×10−6,KL 系数为 0.0,采样温度为 1.0。该阶段的每个step包含 80 个query,每个query有 8 个回复,最大长度为 32k。
IcePoP的效果验证:比TIS,原始GRPO更稳定。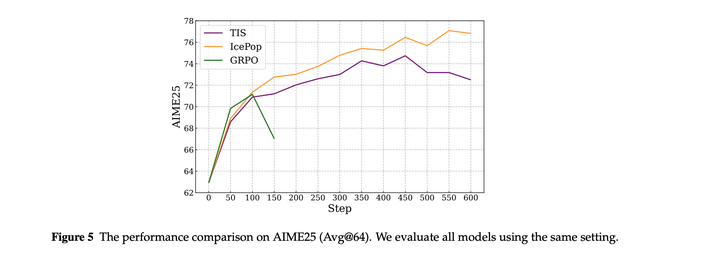
训练稳定性的相关指标,IcePoP会更好: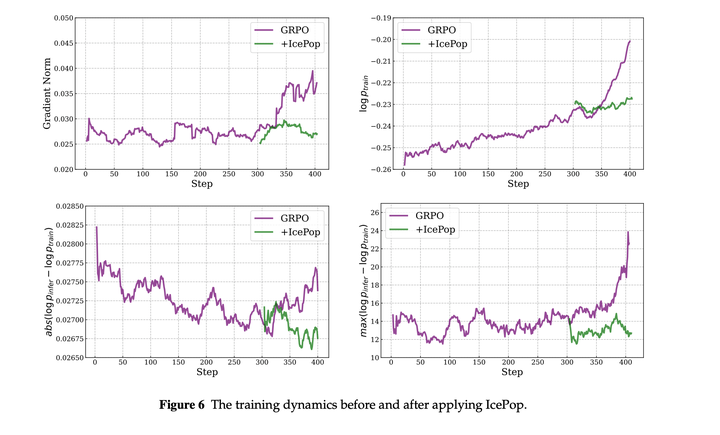
C3PO++的效果,可以大幅缩短训练时间: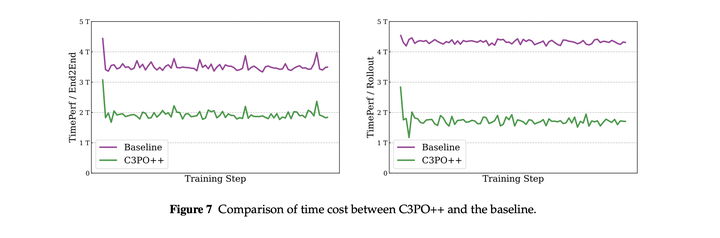
同时performance和非异步训练的表现接近: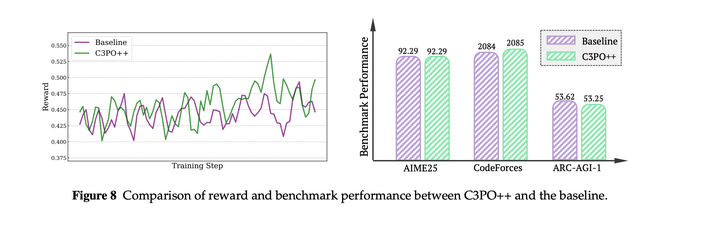
**ASystem训练架构:**本文提出Asystem训练框架,能够支持大规模的分布式强化学习训练。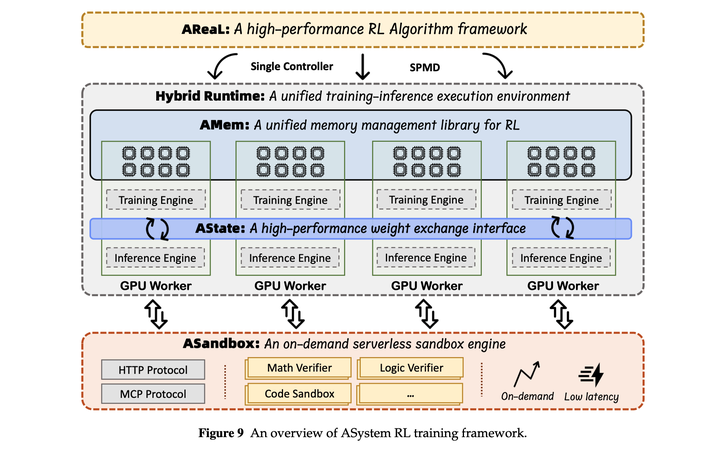
评估以下的benchmark:
评估结果如下,在开源模型领域处于领先地位: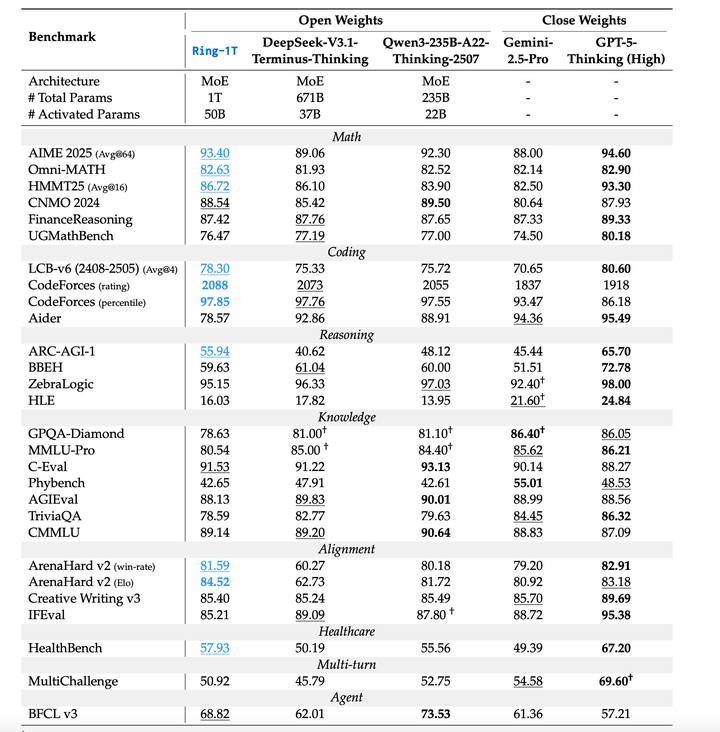
评论