
快速摘要: GLM-5是智谱推出的下一代基础模型(744B总参数、40B激活参数),采用DSA(Deep Sparse Attention)架构在保持长上下文保真度的同时显著降低训练与推理成本。模型提出Muon Split优化MLA训练、参数共享的MTP提升推测解码效率,并构建了全异步解耦RL框架支持大规模智能体强化学习。GLM-5在主流公开benchmark上取得SOTA性能,特别是在真实世界代码任务和端到端软件工程挑战中展现出前所未有的能力,同时完成了七大国产芯片平台的全栈适配。
论文GLM-5: from Vibe Coding to Agentic Engineering
本文提出GLM-5,将范式从vibe coding转向agentic engineering 的下一代基础模型。在其前代模型的智能体能力、推理能力与代码能力基础上,GLM-5采用了DSA架构,在保持长上下文保真度的同时,显著降低了训练与推理成本。为了提升模型的对齐水平与自主能力,构建了一套全新的异步强化学习基建,通过将生成过程与训练过程解耦,大幅提升了后训练阶段的效率。此外,本文还提出了异步智能体强化学习算法,进一步提升了强化学习的质量,使模型能够更有效地从复杂长文本的交互中学习。
通过这些创新,GLM-5在主流公开benchmark测试中取得了SOTA的性能。最为关键的是,GLM-5在真实世界代码任务中展现出了前所未有的能力,在处理端到端软件工程挑战方面超越了以往的baseline模型。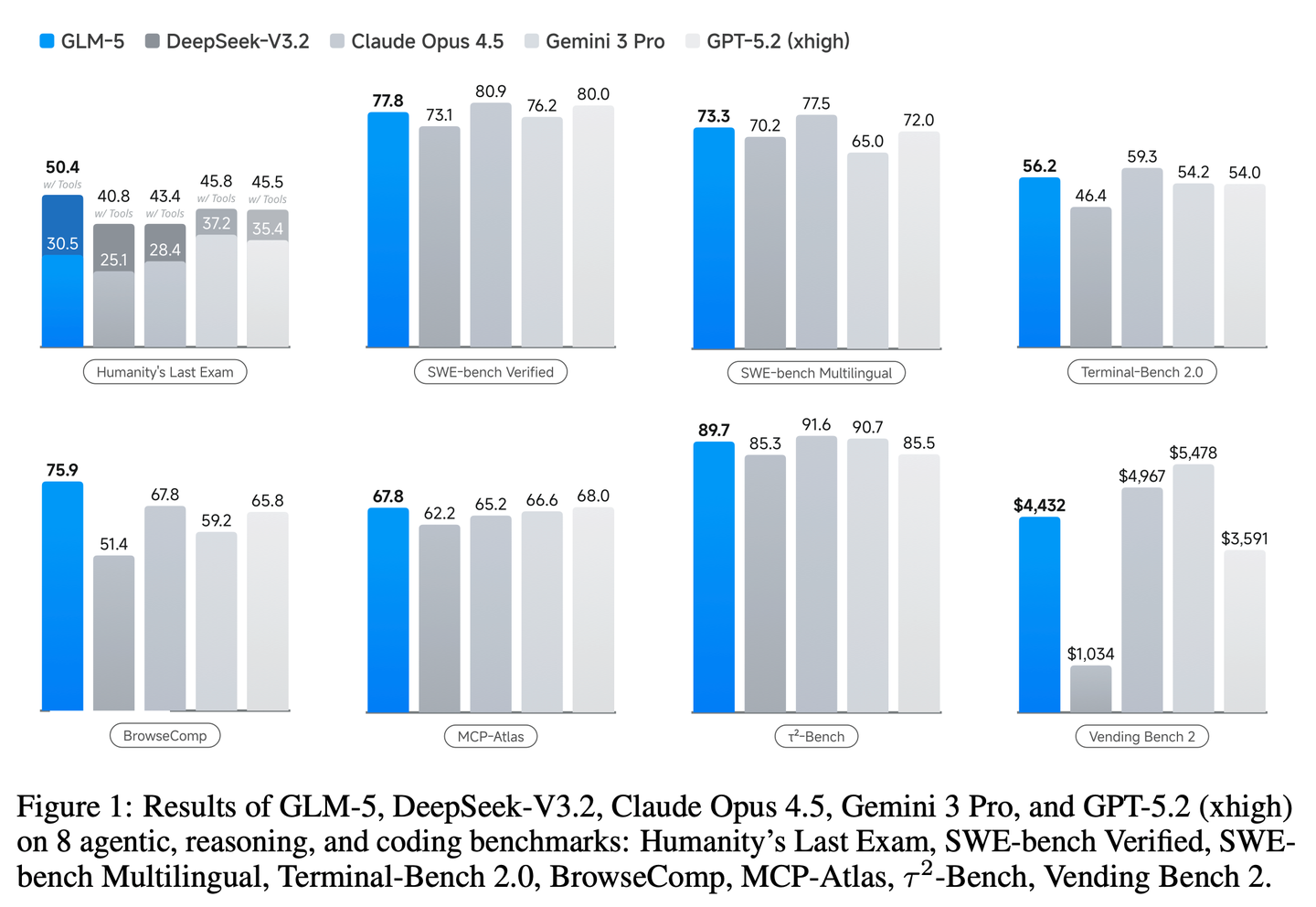
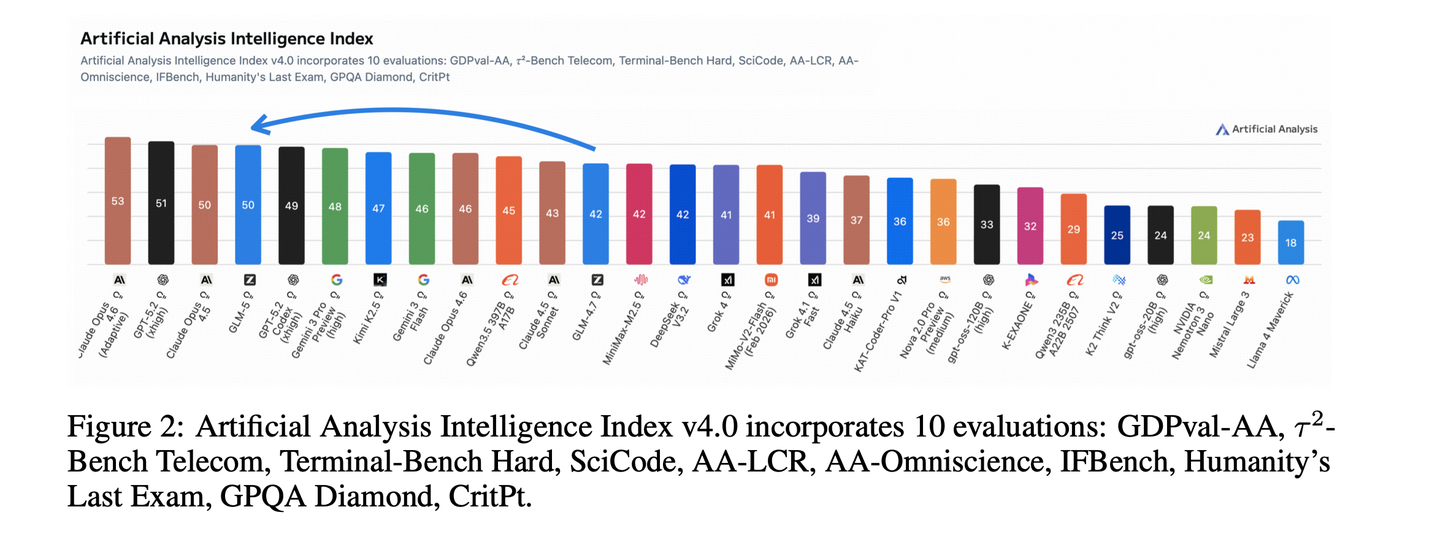

论文分别从pre-training,mid-training,post-training,agentic engineering, evaluation等方面介绍GLM-5模型。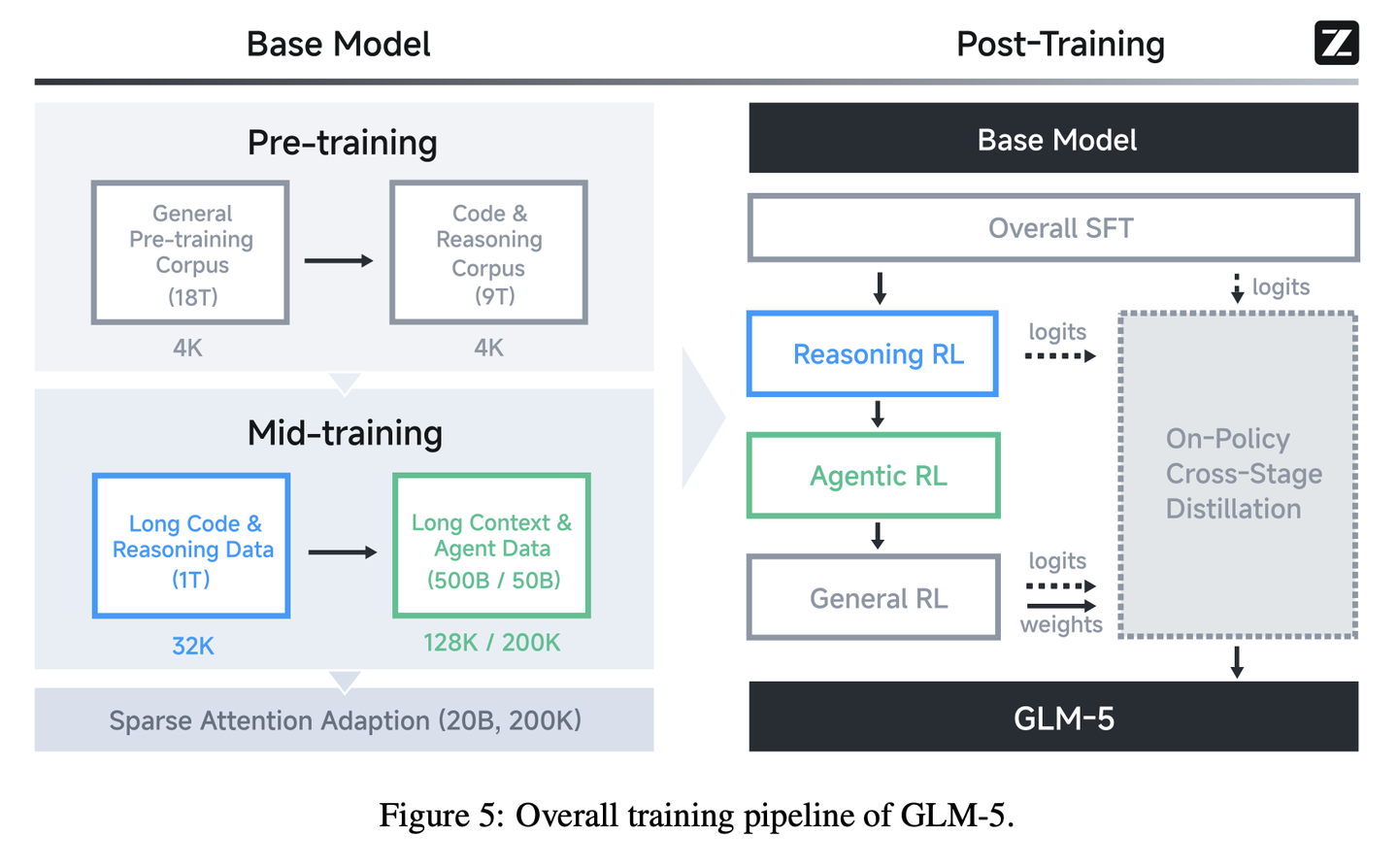
与GLM-4.5类似,GLM-5的base模型训练分为两个阶段:第一阶段为pre-training,用于构建通用语言与代码能力;第二阶段为mid-training,用于强化agent与长上下文能力。其base模型累计训练token量达28.5 T。### 模型架构
**模型规模scaling: **GLM-5将专家数量扩展至256个,同时将网络层数缩减至80层,以最大程度降低专家并行的通信开销。最终模型参数为744B(40B激活)。
**Multi-latent Attention:**通过采用降维的key和value,MLA可达到与GQA相当的效果,同时能节省显存,并且达到对长上下文序列更快的处理速度。但在使用Muon优化器的实验中发现,采用576维潜变量KV缓存的MLA,性能无法匹配8 query分组的 GQA。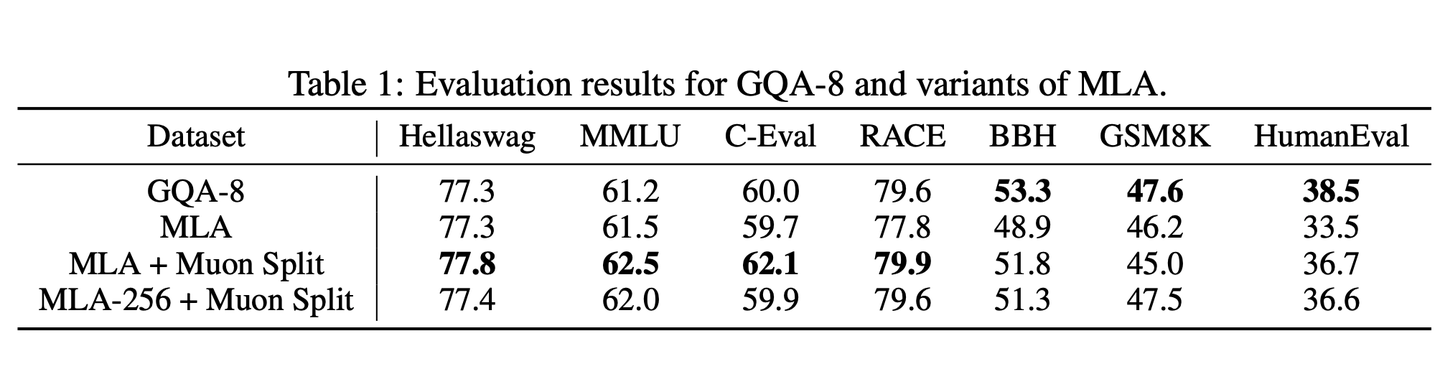
为弥补这一性能差距,针对GLM-4.5中Muon优化器的实现方案进行改进。原始方案对多头query、key、value的上投影矩阵WUQ、WUK、WUV执行矩阵正交化;**而在改进方案中,将这些矩阵拆分为对应不同注意力头的更小矩阵,并对这些独立矩阵分别执行矩阵正交化。该方法被命名为Muon Split,它能让不同注意力头的投影权重以不同尺度更新。**如表所示,该方法有效提升了MLA 的性能,使其表现与GQA-8持平。实践中还发现,搭配Muon Split 后,GLM-5的注意力logits尺度在预训练过程中始终保持稳定,无需任何裁剪策略。
MLA的另一个缺陷是解码阶段的计算成本过高。在解码过程中,MLA需要执行576维的点积运算,远高于GQA的128维计算量。**GLM-5将head维度从192提升至256,同时将注意力头的数量减少1/3。这一调整在保持训练计算量与参数量不变的前提下,降低了解码阶段的计算开销。**该变体被命名为MLA-256,其性能与采用Muon Split的MLA相当。
参数共享的MTP: Multi-token Prediction (MTP)能够提升基础模型的性能,同时可作为推测解码的草稿模型。但在训练阶段,要预测后续n个token,就需要n个MTP层,这导致MTP的参数与KV缓存显存占用会随推测步数线性增长。DeepSeek-V3在训练时仅使用单层 MTP,推理时预测后续2个token。训练与推理的不一致性会降低第二token的接受率。为此,GLM-5在训练时共享3个MTP层的参数,这使得草稿模型的显存占用与 DeepSeek-V3 保持一致,同时提升了接受率。如表所示,在私有prompt集上,当推测步数相同时,GLM-5的接受长度比DeepSeek-V3.2更长。
基于DSA的持续预训练:与滑动窗口等固定模式不同,DSA 会自主判断哪些token具备重要性。DSA 最具吸引力的一点可以基于已有的基础模型,进行持续预训练,避免了从零开始训练的巨额成本。DSA训练从mid-training结束后的base模型启动。预热阶段共1000步,每步在14个202752 token的序列上训练,最高学习率设为5e-3。随后的稀疏适配阶段,沿用mid-training的训练数据与超参数,完成20B token的训练。
为进一步验证DSA训练的有效性,分别用相同的后续数据,对 DSA 和 MLA 模型进行了微调,结果显示两个模型在训练损失与评估benchmark上的表现一致。
**高效注意力变体的消融实验:**除了DSA,还基于GLM-9B,探索了多种高效注意力机制。基线模型在全部40层中采用GQA,且已在128K上下文窗口下完成微调。评估了以下几种方案:- Sliding Window Attention模式:在整个网络中,采用全注意力层与窗口注意力层交替的固定模式。- Gated DeltaNet:一种线性注意力变体,通过门控线性循环替换了基于softmax的二次注意力计算,将序列长度相关的计算成本从二次级降至线性级。
在这些baseline的基础上,进一步提出了两项改进:- 基于搜索的SWA模式:提出了一种基于搜索的适配方法,该方法能在保留其余层全注意力的前提下,识别出SWA转换层的最优子集。采用beam search策略,确定能在下游任务中最大化性能的配置。为控制计算成本,仅在16K上下文长度下执行搜索,并将得到的模式泛化到其他输入长度。具体而言,使用8的波束大小,每步优化两层;对于40层的GLM-9B,该过程在约10步内收敛。每一步,都会在16K上下文长度的 RULERbenchmark上评估候选模式。最终得到的最优模式是SFSFSFFSSFFFFFSSFSFFFFFSFSFFSFSFFSFFSSSS,其中S和F分别代表 SWA与全注意力层。尽管这种基于搜索的配置仅在 16K 长度下完成优化,但它展现出了极强的长度泛化能力,在所有测试的上下文长度下都能保持高效。- SimpleGDN:一种极简的线性化策略,专为最大化预训练权重的复用设计,在持续训练适配场景下对GDN做了优化。完全移除了Conv1d与显式门控模块,改为直接将预训练的QKV投影权重映射到线性循环公式中。**在四项长上下文benchmark上对所有方法进行了评估:RULER、MRCR、HELMET-ICL,以及RepoQA: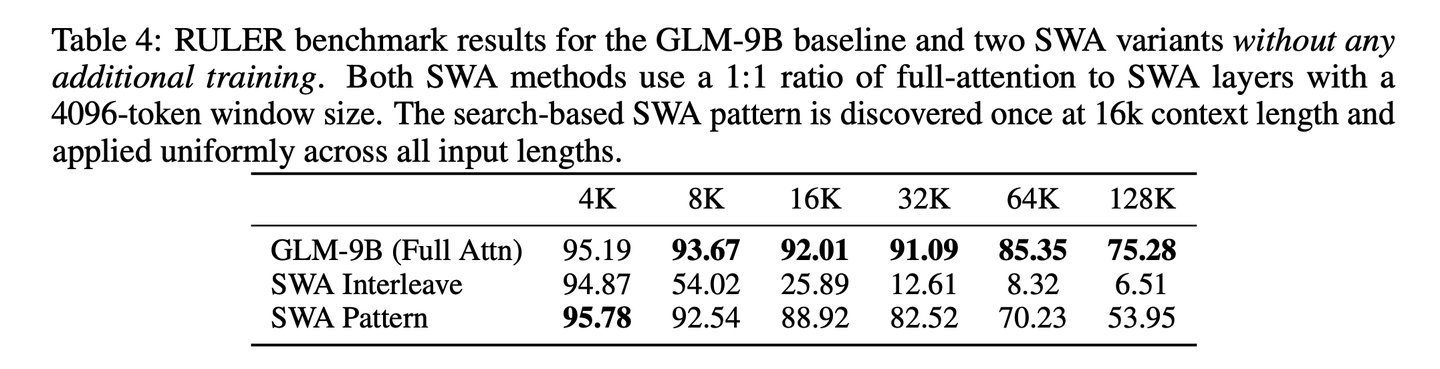
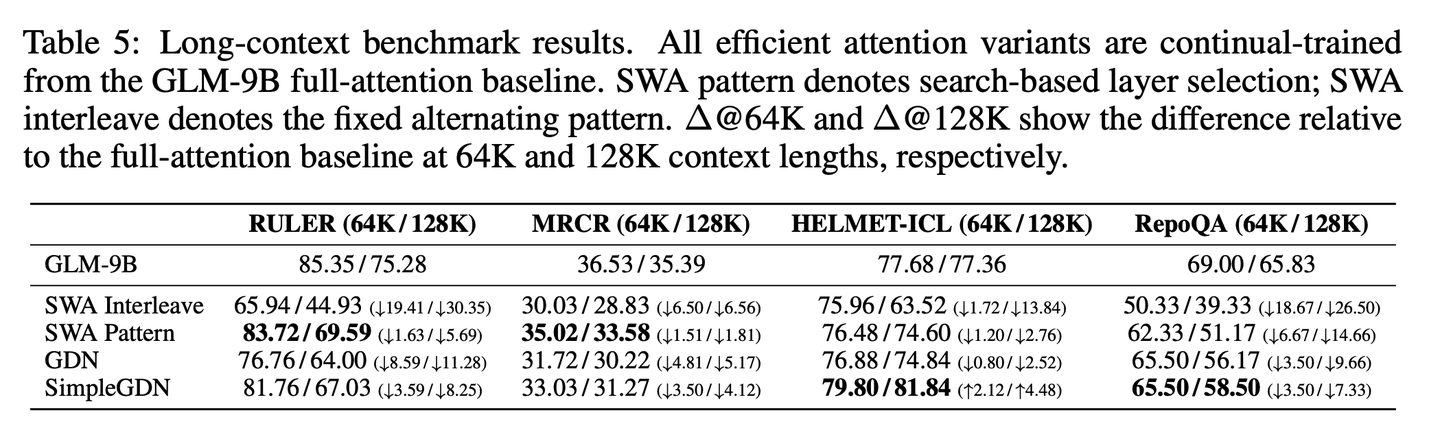
简单SWA交错模式,会在长上下文任务上出现灾难性的性能下降;而基于搜索的层选择方案能大幅缩小这一差距,在最关键的位置保留全注意力token,但代价是需要引入额外的参数。
GDN等线性注意力变体能够进一步提升质量,同时复用预训练权重。SimpleGDN则在两者间实现了最佳平衡,最大化了预训练权重的复用。但所有这些方法,在细粒度检索任务上都存在固有的精度缺口,在 128K 长度的 RULER benchmark上最多下降 5.69,128K长度的 RepoQA benchmark上最多下降 7.33。这是因为在持续训练适配过程中,即便一半的层仍保留全注意力,高效注意力机制也会不可避免地带来信息损失。
相比之下,DSA在构建过程中不存在精度损失,它的轻量级索引器实现了token级的稀疏化,同时不会丢弃任何长距离依赖,能够应用于所有层,且不会造成质量下降。为验证这一点,在搭载MLA的GLM-4.7-Flash上,开展了小范围的DSA实验。遵循标准的DSA流程:- 预热阶段,仅训练索引器 1000 步(batch大小 16),同时冻结基础模型的所有权重;- 联合训练阶段,在 150B token 上同时训练模型与索引器。
DSA的效果良好: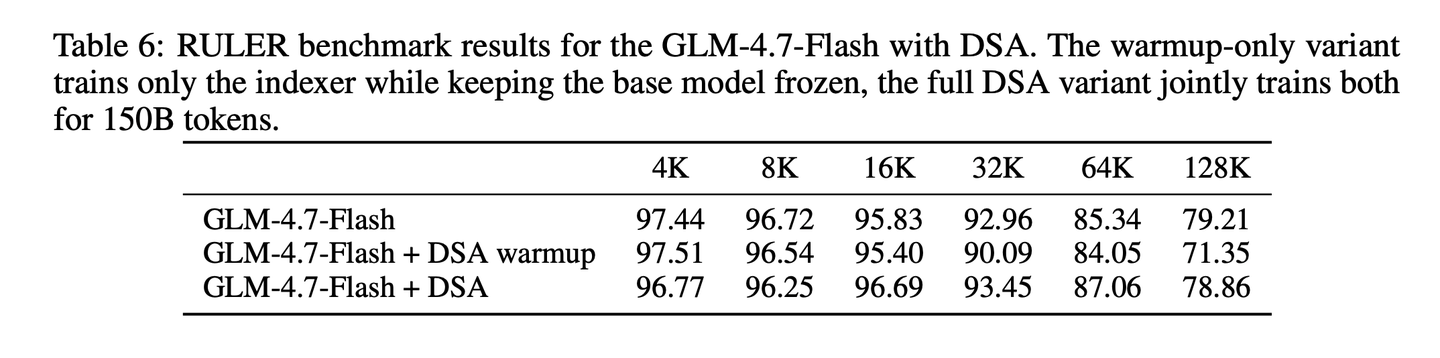
网页数据**:在GLM-4.5数据流水线的基础上,优化了海量网页数据集的筛选标准。引入了基于句子嵌入的DCLM分类器,以识别并聚合标准分类器之外的额外高质量数据。为应对长尾部知识的挑战,采用了针对维基百科条目和大模型标注数据优化的世界知识蒸馏方案,从原本中低质量的数据中提取有价值的信息。
代码数据:扩充了预训练语料库,新增了主流代码托管平台的刷新快照,以及更多包含代码的网页,最终去重后的模糊代码语料规模提升了28%。为提升代码语料的完整性、降低噪声,修复了GLM-4.5中软件遗产代码文件的元数据对齐问题,并采用了精度更高的语言分类流水线。沿用了GLM-4.5中针对源代码和代码相关网页的质量感知采样策略。此外还为低资源编程语言(如Scala、Swift、Lua等)训练了专用分类器,提升了这些语言的采样比例。
**数学与科学数据:**从网页、书籍和论文中收集了高质量的数学与科学数据,以进一步提升模型的推理能力。优化了网页、书籍和PDF的内容提取流水线,提升了数据质量。采用大语言模型对候选文档打分,仅保留教育性最强的内容。针对长上下文模型,开发了分块聚合打分算法,提升了评分精度。过滤流水线经过严格设计,坚决杜绝使用合成的、AI生成的、或基于模板生成的数据。### Mid-training
扩展上下文与训练规模:分三个阶段逐步扩展上下文窗口:32K(1 T token)、128K(500 B token)、200K(50 B token)。与 GLM-4.5的128K最大上下文相比,新增的 200K 阶段大幅提升了模型处理超长文档与复杂多文件代码库的能力。在训练后期,对长文档与合成智能体轨迹数据做了对应的上采样处理。
软件工程数据:沿用了将仓库级代码文件、提交差异(commit diffs)、GitHub issues、拉取请求(PR)与相关源文件拼接为统一训练序列的范式。在GLM-5中,放宽了仓库级的过滤标准,扩大了符合要求的仓库池,最终得到约1000万组issue-PR配对数据;同时强化了单条issue级别的质量过滤,以降低噪声。还为每组issue-PR配对检索了更多相关文件,构建了更丰富的开发上下文,覆盖了更广泛的真实软件工程场景。经过过滤后,该数据集的issue-PR部分包含约160 B个唯一token。
**长上下文数据:**长上下文训练集包含自然数据与合成数据两类。自然数据来自书籍、学术论文、通用预训练语料中的文档,通过多阶段过滤(困惑度 PPL、去重、长度筛选),并对知识密集型领域数据做了上采样。在合成数据构建中,受NextLong与EntropyLong启发,采用多种技术构建长程依赖关系。将高度相似的文本通过交错打包的方式聚合为序列,缓解中间文本信息丢失现象,提升模型在各类长上下文任务上的表现。在200K训练阶段,额外加入了少量 MRCR 类数据,其中包含多组遵循OpenAI原始范式设计的变体,以强化模型在扩展多轮对话中的召回能力。实验结果表明,增加数据多样性能够逐步提升模型的长上下文表现;在初始128K训练阶段后追加的200K中期训练阶段,即使在 128K 上下文窗口内,也能进一步提升模型的性能。### 训练基础设施
灵活的MTP模块部署:在交错流水线并行模式下,模型组件会被灵活分配到不同的流水线阶段。MTP 模块横跨嵌入层、Transformer层与输出组件,其显存占用远高于其他模块,会导致流水线阶段级别的负载失衡。将MTP的输出层与主模型输出层共同部署在流水线的最后一个阶段,以实现参数共享;同时将其嵌入层与Transformer组件部署在前序阶段。这一设计降低了最后一个阶段的显存压力,提升了各流水线阶段的显存负载均衡性。
流水线ZeRO2梯度分片:每个流水线秩会维护多个流水线阶段,朴素的实现中,每个阶段都需要完整的梯度缓冲区用于梯度累积与优化器更新。受ZeRO2启发,在数据并行的各秩之间对梯度做分片存储,每个秩仅存储完整梯度的1/dp。此外,同一时间仅为两个阶段保留完整的累积缓冲区,并通过双缓冲机制实现复用。当一个阶段在连续的mini-batch上累积梯度时,前一个缓冲区的梯度同步操作可并行执行。这一设计将持久化的梯度显存占用降至"各阶段分片缓冲区 + 仅两个完整缓冲区用于滚动累积",且在实践中不会带来额外的同步开销。
Muon分布式优化器的零冗余通信:朴素的Muon实现中,每个数据并行秩都需要执行全模型参数的all-gather操作,这会导致瞬时显存尖峰与冗余通信。将all-gather操作限制在每个秩所拥有的参数分片内,并将本地计算与分片通信做重叠优化。这一设计消除了冗余通信,显著降低了优化器相关的峰值显存开销。
流水线激活值卸载:在流水线预热阶段,前向执行会先于反向传播推进,延长了中间激活值的生命周期。将前向执行后的激活值卸载到主机内存中,在反向执行前重新加载回显存。以层为粒度执行卸载,进一步降低峰值显存占用。结合细粒度的重计算策略,该设计基本消除了在GPU显存中常驻激活值的需求。卸载与重加载的调度会和计算过程做重叠优化,同时避免与点对点通信、MoE的token路由(分发与合并)产生资源竞争。这一设计在几乎无额外开销的前提下,大幅降低了激活值的显存占用。
用于降低峰值显存的序列分块输出投影:输出投影层与交叉熵损失,会因存储反向传播所需的激活值产生瞬时显存开销,同时会推高损失计算过程中的临时精度需求。为降低这一开销,将输入序列切分为更小的块,在每个块上独立计算投影与损失,完成前向与反向传播后,释放对应的激活值再进入下一个块。最终,峰值显存占用会随分块数量的增加而降低。在分块数量合理的前提下,该方法能够缓解输出层的显存压力,同时保持与未分块执行相当的模型性能。
高效的权重梯度延迟计算:为减少流水线气泡,将关键路径上的部分权重梯度计算做延迟处理。通过细粒度的延迟调度,结合优化的存储与通信重叠策略,在控制显存开销的同时,提升了训练吞吐量。
高效长序列训练:更长的序列会加剧数据并行组与流水线并行组之间的负载不均衡问题。通过感知工作负载的序列重排序、注意力计算的动态重分布,以及将数据并行秩灵活划分为不同规模的上下文并行组。还通过层级化的all-to-all操作,将节点内与节点间的QKV 张量通信做重叠优化,降低了通信延迟。
**INT4量化感知训练:**为在低精度下为用户提供更优的准确率,在有SFT阶段应用了INT4 量化感知训练(QAT)。此外,为进一步缓解训练时的时间开销,开发了一套可同时用于训练与离线权重量化的量化内核,确保了训练与推理过程中的行为逐bit一致。### Post-training
采用渐进式对齐策略:首先通过SFT引入复杂的交错思考模式,随后针对推理与智能体任务开展专项RL阶段,最终通过通用强化学习阶段完成拟人化对齐。以on-policy跨阶段蒸馏作为最终优化环节,让GLM-5 在充分吸收各训练阶段性能收益的同时,缓解能力退化问题。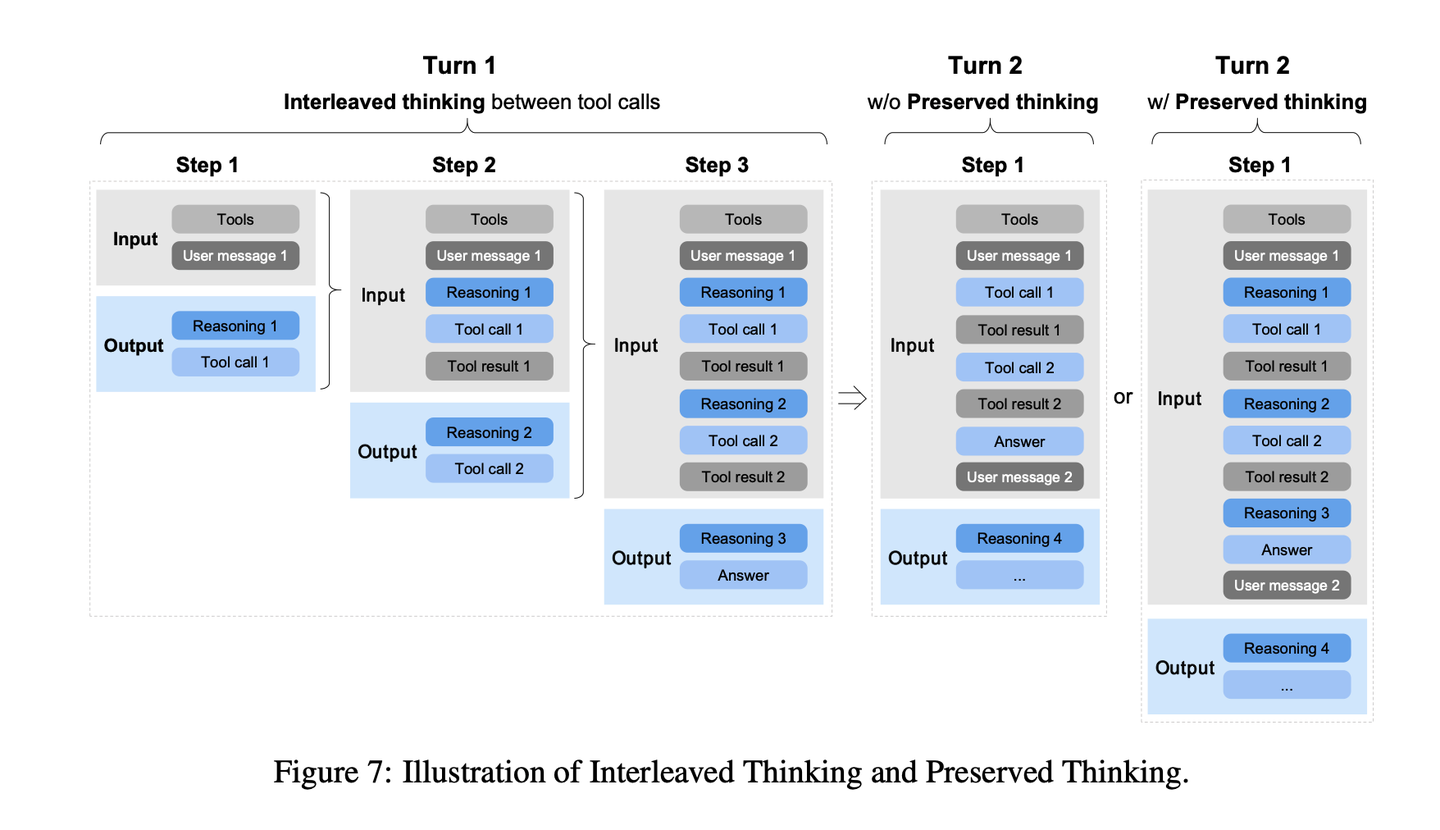
与GLM-4.5相比,GLM-5在SFT阶段大幅扩充了智能体与代码数据的规模。GLM-5的SFT 语料主要覆盖三大类别:- 通用对话:问答、写作、角色扮演、翻译、多轮对话与长上下文交互;- 推理:数学、编程与科学推理;- 代码与智能体:前后端工程代码、工具调用、代码智能体、搜索智能体与通用智能体。
此外,GLM-5在SFT阶段将最大上下文长度扩展至202752个token。配合更新后的对话模板,模型支持三种截然不同的思考模式,包括:- 交错思考:模型在每一次回复与工具调用前都会先进行思考,提升了指令遵循能力与生成质量;- 保留思考:在代码智能体场景中,模型会在多轮对话中自动保留所有思考模块,复用已完成的推理结果,无需从零重新推导。这一设计减少了信息丢失与逻辑不一致问题,非常适配长周期、复杂任务;- 轮次级思考:模型支持在单轮会话中对推理过程进行逐轮控制,针对轻量级请求禁用思考以降低延迟/成本,针对复杂任务启用思考以提升准确率与稳定性。
通过在动作之间插入思考,并保持跨轮次的逻辑一致性,GLM-5在复杂任务上实现了更稳定、可控的行为表现。
对于通用对话,相比GLM-4.5优化了回复风格,使其更具逻辑性与简洁性。针对角色扮演任务,收集并构建了覆盖多语言、多角色配置的更广泛数据集。特别定义了多项评估维度,包括指令遵循能力、语言表现力、创造力、逻辑连贯性与长对话一致性,并通过自动与人工过滤相结合的方式,对数据进行筛选与优化。
对于推理任务,进一步深化了模型的推理深度。具体而言,针对逻辑推理,构建了可验证的问题,并通过拒绝采样合成高质量数据;针对数学与科学问题,应用了基于难度的过滤流程,仅保留对GLM-4.7模型具有挑战性的问题。
对于代码与智能体任务, GLM-5构建了大量执行环境以获取高质量轨迹数据,尤其侧重真实场景与长周期任务。通过专家强化学习与拒绝采样进一步优化了SFT数据,轨迹中的错误片段会被保留,但在损失函数中被掩码屏蔽,让模型能够学习纠错行为,同时不会强化错误动作。### Reasoning RL
基于GRPO构建,并融合了IcePop技术,缓解训推不一致的问题:
抑制不一致比率偏离过大的样本:
训练全程采用on-policy策略模式,batchsize为 32,groupsize为32。
**DSA强化学习:**在基于DSA架构的模型上开展了多项大规模RL训练实验。与MLA相比,DSA引入了额外的索引器,用于检索前k个最相关的key-value条目,并在检索到的 token子集上进行稀疏注意力计算。检索得到的前k个结果对RL的稳定性至关重要,这与MoE模型通过路由重放保留激活的前k个专家、确保训练推理一致性的逻辑类似。
但在每个token位置存储索引器的前k个索引显然不具备可行性,因为DSA中使用的k=2048远大于MoE中常用的k值,存储所有索引会带来极高的存储成本,以及训练引擎与推理引擎之间巨大的通信开销。
本文发现,采用确定性的top-k算子能够有效解决这一问题。与SGLang的DSA索引器中使用的、基于CUDA的非确定性top-k实现相比,直接使用原生torch.topk的速度略慢,但具备确定性,它能生成更一致的输出,并带来显著的RL性能提升。相比之下,其他非确定性top-k算子(如CUDA或TileLang实现)会在RL训练仅几步后就出现性能急剧下降,同时伴随熵值的骤降。
因此,在整个RL阶段,在训练引擎的DSA索引器中,将torch.topk作为默认的top-k算子。同时,在RL训练过程中默认冻结索引器的参数,以加速训练,避免索引器带来的训练不稳定问题。
混合领域推理强化学习:在推理RL阶段,在四大领域开展混合RL训练:数学、科学、代码,以及工具集成推理(TIR)。
对于数学与科学领域,数据既来自开源数据集,也来自与外部标注供应商合作开发的数据集。进一步应用了难度过滤,聚焦于GLM-4.7模型极少能正确解答、或持续答错,而更强的教师模型(如 GPT-5.2 xhigh、Gemini 3 Pro Preview)能够解决的问题。对于代码领域,同时覆盖了竞技编程风格任务与科学计算任务:前者主要来自 Codeforces,以及TACO、SYNTHETIC-2-RL等代表性数据集;后者则通过将问题拆解为正确解法所需的最小代码实现,从内部问题库构建而来。对于TIR,复用了数学与科学 RL 数据中更具挑战性的子集,并额外构建了由标注供应商提供的STEM问题,这些问题被明确设计为需要通过外部工具解答。
在RL训练过程中,为不同领域、不同数据源分配专属的评判模型或评估系统,以生成二分类的结果奖励。在四个领域中保持整体混合比例大致均衡,在混合RL设置下,各领域均持续获得稳定且显著的性能提升。### Agentic RL
为提升GLM-5的智能体性能,开发了一套全异步、解耦的RL框架,并针对代码与搜索智能体任务对GLM-5 进行优化。朴素的同步RL在长周期智能体轨迹采样过程中,会出现严重的GPU空闲问题。通过中心多任务轨迹采样编排器,将推理引擎与训练引擎解耦,实现了跨各类智能体工作负载的高吞吐量联合训练。
为在异步off-policy条件下保持训练稳定性,引入了两项核心机制:- Token-in-Token-out,通过保留token级的精确对应关系,消除了重分词不匹配问题;- 采用了直接双边重要性采样,对轨迹采样的对数概率应用了token 级的裁剪机制,在无需追踪历史策略checkpoint的前提下,高效控制了off-policy偏差。
还采用了感知数据并行的路由策略,在大规模MoE模型的长上下文推理过程中,最大化 KV 缓存的复用率,实现加速。为适配规模化的智能体环境,在三大领域构建了可验证的训练环境:超10万条真实软件工程任务、终端任务,以及高难度多跳搜索任务。### General RL
**多维度优化目标:**将通用 RL 的优化目标拆解为三个互补的维度:基础正确性、情商表达,以及任务专属质量。
基础正确性维度是回复质量的基石,它针对所有会损害模型输出可用性的各类错误,包括指令遵循失败、逻辑不一致、事实偏差、知识幻觉、语言不通顺等。该维度的目标是将错误率降至最低,让回复达到可用的基线水平。将其视为所有后续优化的前提:无论回复的措辞多么精致,只要包含事实错误或对用户意图的错误解读,就可能对用户造成主动误导。
情商表达维度在核心正确性之外,针对用户体验进行优化。它旨在生成富有共情力、有见地、风格贴近自然人类交流的回复,让用户与模型的交互更自然、更有吸引力。
任务专属质量维度针对各类特定任务进行细粒度优化。它在基础正确性构建的可用性之上,将每个任务类别下的回复从 "仅正确" 提升至 "真正高质量"。该维度覆盖的任务范围极广,包括写作、文本处理、主客观问答、角色扮演与翻译等。每个任务领域都需要专属的奖励信号,因此需要一套混合奖励系统。
**混合奖励系统:**为对上述多样化目标进行监督,构建了一套混合奖励系统,整合了三类互补的奖励信号:基于规则的奖励函数、结果奖励模型(ORMs),以及生成式奖励模型(GRMs)。三类信号各有优劣,它们的组合是实现稳定、高效、可扩展的通用RL训练流程的核心。基于规则的奖励能够提供精确、可解释的信号,但仅适用于可通过确定性规则描述的维度。结果奖励模型能提供低方差的信号,训练效率高,但更容易被reward hacking,即策略会利用表面模式,而非真正提升核心能力来获取奖励。生成式奖励模型借助大语言模型生成标量或结构化的评估结果,对这类破解行为的鲁棒性更强,但通常方差更高。通过融合这三类信号,得到了一套兼顾精度、效率与鲁棒性的奖励系统,缓解了单一组件的固有缺陷。
**人类风格对齐:**通用RL流水线的一个显著特点,是明确融入了高质量的人工撰写回复。没有完全依赖模型生成的回复进行优化,而是引入了专家级人工回复,作为风格与定性层面的锚点。这一设计的动机是观察到:纯模型生成的优化,往往会收敛到可识别的模型模式,通常冗长、公式化,或缺乏专业人工写作的细腻度。通过让模型接触人工撰写的范例,引导它采用更自然、更符合人类对齐的回复模式。### On-policy蒸馏
在多阶段 RL 流水线中,针对不同目标的序列优化,可能会导致此前习得的能力出现累积退化。为缓解这一问题,将On-policy跨阶段蒸馏作为最终训练阶段,采用On-policy蒸馏算法,快速恢复此前SFT与RL阶段(推理RL、通用RL)习得的能力。
具体而言,将前序训练阶段的最终检查点作为教师模型,训练提示词从对应教师的RL训练集中采样,并按适当比例混合。训练损失可通过将RL中的优势项替换为以下公式得到: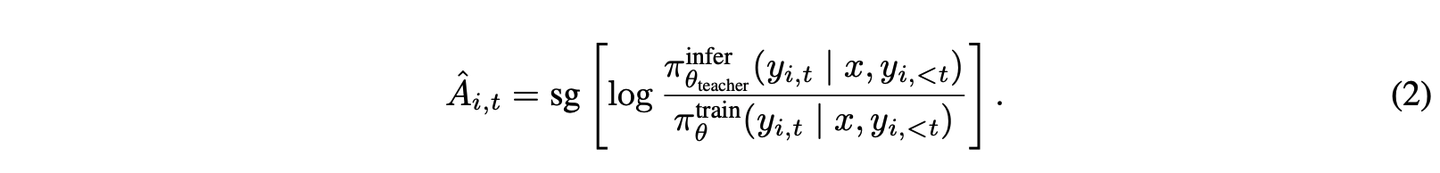
目前使用推理引擎来获取教师模型的logits。未来计划将推理后端迁移至训练引擎,并统一采用MLA的MQA模式进行推理。训练过程中,GRPO算法的分组大小设置为 1,以提升数据吞吐量,批次大小设置为1024(无需为每个提示词维护大量样本组来估计优势值,优势值可直接通过与教师模型的差距计算得到)。### RL训练基础设施:slime 框架
继续使用slime作为GLM-5的统一后训练基础设施,实现端到端的规模化强化学习。GLM-5没有引入新的系统组件,而是充分利用了slime的现有能力:- 通过自由形式(free-form)的rollout定制以及基于服务器的执行模型,扩展任务覆盖范围- 通过混合精度训练/rollout,并结合MTP与Prefill-Decode解耦**,显著提高吞吐量,特别适用于多轮RL工作负载- 通过基于心跳机制的rollout故障容错以及路由级服务器生命周期管理,**提升系统鲁棒性
**规模化scaling:**通过高度可定制的轨迹采样实现灵活训练。GLM-5的后训练覆盖了极为多样化的优化目标。为在无需为任务单独维护分支的前提下支持这种多样性,GLM-5 充分利用了slime高度可定制的轨迹采样接口,以及其基于服务的执行模式。
高度可定制的轨迹采样:slime提供了灵活的接口,用于实现任务专属的轨迹采样逻辑,包括多轮交互循环、工具调用、环境反馈处理,以及基于验证器的分支逻辑,且无需修改底层基础设施。GLM-5利用这一能力,在统一的训练栈中,支持了广泛的领域与训练范式,包括但不限于推理RL、通用RL、智能体RL与on-policy蒸馏。
基于HTTP API的服务化轨迹采样:slime 通过标准 HTTP API 暴露其轨迹采样服务与推理路由,让用户能够以与传统推理引擎完全一致的方式,与slime的服务层交互。这一设计将推理逻辑与训练进程边界解耦:外部智能体框架与环境可以直接调用服务/路由端点,而优化后端对于短周期单轮训练与长周期多轮轨迹,均能保持不变。
**RL轨迹采样的长尾延迟优化:**对于RL轨迹采样,优化目标并非聚合吞吐量,而是端到端延迟,其瓶颈由每一步中最慢的(长尾)样本决定。在实践中,单个掉队的轨迹就可能造成同步点停滞(例如批次完成、缓冲区就绪、权重更新),并直接决定整体的耗时进度。因此,GLM-5 充分利用了slime面向延迟的服务与调度机制,最小化中位数延迟,更重要的是,最小化长尾延迟。
基于MLA DP注意力的多节点推理无队列服务:为避免排队延迟,即使在流量突发的场景下,也需要及时响应轨迹采样请求,而这需要大量KV缓存容量。GLM-5采用了多节点推理部署架构,在8个节点上部署了EP64与DP64,以提供充足的分布式 KV 缓存。DP 注意力的引入,主要是为了避免在不同rank之间复制 KV 数据。
通过FP8轨迹采样与MTP降低长尾延迟:GLM-5采用FP8精度进行轨迹采样推理,以降低每个token的延迟,缩短长轨迹的完成时间。此外,GLM-5充分利用了对MTP的支持,这一特性在 RL 轨迹采样典型的小batch解码场景下效果尤为显著。由于长尾延迟通常由掉队样本(例如罕见的长上下文、复杂多轮推理、重度工具调用的轨迹)驱动,MTP 能为长尾场景带来巨大收益,提升最慢样本的完成速度,从而降低步级停滞时间。
PD解耦:在多轮场景中,长前缀prefix非常常见(对话历史、工具轨迹、代码上下文)。在DP注意力模式下,在同一服务资源上混合执行预填充与解码,会产生严重的干扰:繁重的prefix可能会抢占或中断服务器上正在进行的decoding任务,阻碍其他样本的持续推进,急剧恶化长尾延迟。因此,GLM-5 利用了slime的PD解耦能力。通过在专属资源上分别运行预填充与解码任务,解码过程能够保持稳定、不被中断,让长周期样本能够持续推进,显著改善了多轮智能体RL中的长尾表现。
**轨迹采样鲁棒性:心跳驱动的容错机制:**在规模化场景中,瞬时故障(例如单台服务器崩溃、网络问题、性能降级)是不可避免的。GLM-5 利用slime的心跳驱动容错机制,确保在这类事件发生时训练的连续性:轨迹采样服务器会定期发送心跳,由编排层监控;不健康的服务器会被主动终止,并从推理路由中注销。最终,重试请求会被自动从故障或降级的服务器,路由至健康的服务器,避免单台服务器的故障中断轨迹采样流程,保障RL训练端到端的不间断执行。### Agentic Engineering
在智能体工程模式中,AI智能体可自主完成代码编写,独立执行规划、实现与迭代全流程。为支撑这类长周期任务,GLM-5采用了一套全异步、解耦的 RL 框架,通过减少智能体轨迹采样过程中的GPU空闲时间,显著提升了GPU利用率。为实现智能体环境的规模化扩展,开发了环境构建流水线:针对编码任务,构建了超10000个可验证的训练场景,搭建了真实软件工程问题与终端任务环境;针对搜索智能体,开发了一套自动化、可扩展的复杂多步推理数据合成流水线,用于构建智能体训练数据。
**智能体任务的异步强化学习:**为实现智能体任务的强化学习,设计了一套全异步、解耦的 RL 基础设施,它能高效处理长周期的智能体轨迹采样,同时支持跨多样智能体框架的灵活多任务RL 训练。
采用如下训练目标:
**智能体训练的异步RL设计:**由于轨迹采样过程具有长尾特性,朴素的同步RL训练在轨迹采样阶段会产生大量流水线气泡。这是因为智能体任务的生成时长严重不均衡,会导致 GPU出现大量空闲时间。为提升训练吞吐量,为智能体 RL 设计了全异步的训练范式,以提升GPU利用率与训练效率。具体而言,将训练引擎与推理引擎解耦,部署在不同的 GPU 设备上。推理引擎持续生成轨迹,当生成的轨迹数量达到预设阈值时,批次数据会被发送至训练引擎以更新模型。为降低策略滞后、保证训练近似同策略,轨迹采样引擎使用的模型权重会与训练引擎定期同步。训练引擎每完成K次梯度更新,就会更新模型参数,并将新权重推送回推理引擎。
尽管异步模式能显著提升整体训练效率,但这也意味着不同轨迹可能由不同版本的模型生成,进而引入严重的off-policy问题。由于轨迹采样策略的变化,权重更新会对应不同的优化目标,因此也会在每次向推理引擎推送权重更新后,重置优化器。
基于服务的多任务训练设计:为解决多任务RL中轨迹生成的异构性问题(不同任务通常依赖专属的工具集与任务特定的轨迹采样逻辑),引入了基于服务的多任务轨迹采样编排器,用于多任务RL训练。该组件旨在通过一个支持多任务注册服务的中心编排器,实现 slime RL训练框架与各类下游任务的无缝兼容。
**具体而言,每个任务都以独立微服务的形式,实现专属的轨迹采样与奖励逻辑,并注册到中心编排器进行管理与调度。在轨迹采样阶段,中心编排器会控制每个任务的轨迹采样比例与生成速度,实现跨任务的均衡数据采集。**至关重要的是,将所有智能体任务的轨迹标准化为统一的消息表示格式,既能对复杂智能体框架(如软件工程任务)进行联合训练,同时也支持集中式的后处理与异构工作负载的日志记录。
该设计将任务特定逻辑与核心训练循环完全解耦,实现了与多任务 RL 训练的无缝集成。作为GLM-5训练基础设施的核心,该编排器支持超1k路并发轨迹采样,可实现任务采样比例的自动化动态调整,以及任务进度的细粒度监控。
**Token-in-Token-out(TITO):**在RL轨迹采样场景中,TITO指训练流水线直接使用推理引擎生成的、精确的分词与解码token流来构建训练用轨迹。与之相反,文本入文本出模式将推理引擎视为一个仅返回最终文本的黑盒,训练器会对文本重新分词(并经常重新推导边界与截断处理),再计算轨迹损失。这个看似微小的选择会带来决定性的影响:重新分词会在token边界、空格/规范化处理、截断,以及特殊token的位置上引入细微的不匹配,进而破坏动作、奖励/优势之间的对齐关系,尤其是当轨迹采样是流式、截断的,或是跨多个actor交错进行时。TITO 模式对于异步RL训练至关重要,因为它保留了采样内容与优化目标之间token-level的精确对应关系,同时让actor能够发送轨迹片段(包含token ID与元数据),无需在学习端进行有损的重分词。
在实践中,实现了一个TITO网关,它会拦截所有来自轨迹采样引擎的生成请求,记录每条轨迹的token ID与元数据。该设计将繁琐的token ID处理与下游的智能体轨迹采样逻辑隔离开,同时避免了RL训练过程中的重分词不匹配问题。
用于token裁剪的双边重要性采样:在异步场景中,轨迹采样引擎在单条轨迹生成过程中可能会经历多次模型更新,无法追踪精确的行为概率πold。为解决这一问题,采用了一种简化的token级重要性采样机制:
丢弃异策略与含噪声样本:在异步RL中,过长的轨迹会呈现极强的异策略特性,可能导致训练失稳。为过滤这类严重偏离当前策略的样本,记录了生成每条回复时,轨迹采样引擎使用的模型策略版本序列,然后丢弃过于滞后于当前策略的样本。
此外,代码智能体沙箱本身存在固有不稳定性,可能因与模型能力无关的原因发生故障(如环境崩溃)。这类故障会引入含噪声的训练信号,因为它们反映的是环境的不稳定性,而非模型的能力。为缓解该问题,会**记录每个样本的故障原因,并排除因环境崩溃导致失败的样本。**对于 GRPO 这类基于分组的采样方法,丢弃失败样本可能会导致分组不完整:**针对这种情况,当有效样本数量超过分组的一半时,会对分组进行补全;否则会丢弃整个分组。**该流程减少了虚假的奖励信号,提升了训练稳定性。
感知数据并行(DP)的路由加速:提出了一套感知 DP 的路由机制,用于大规模MoE推理的数据并行场景下保留KV缓存的局部性。在多轮智能体工作负载中,来自同一次采样的连续请求共享完全相同的前缀,为最大化 KV 复用,需要强制执行轨迹采样级的亲和性:**属于同一个智能体实例的所有请求,都会被路由到同一个DP rank。**具体而言,引入了一个路由层,它会将每个轨迹采样ID通过一致性哈希映射到固定的 DP rank。该映射在多轮对话中保持稳定,消除了跨rank的缓存未命中。为防止长期的哈希不均衡,结合轻量级动态负载均衡,对哈希空间进行重平衡。该设计避免了冗余的预填充计算,且无需在DP rank之间同步KV数据。随着轨迹采样长度的增加,预填充成本仅与增量token成正比,而非总上下文长度。### 智能体环境的scaling
为支持跨多样智能体任务的强化学习,构建了可验证、可执行的环境,为以代码为核心和以内容生成为核心的工作流提供落地反馈。针对智能体编码任务,开发了两套环境构建流水线,用于构建可验证的可执行环境:一套基于真实软件工程问题搭建的环境搭建流水线,另一套用于终端智能体环境的合成流水线。除编码场景外,还引入了幻灯片生成环境,智能体可在其中操作结构化 HTML,完成可执行的渲染与布局验证。
**软件工程(SWE)环境:**在构建可执行环境之前,收集了大规模的真实Issue-PR配对语料,并应用严格的基于规则与大模型的过滤,确保获取真实、高质量的 issue 描述。将这些实例划分为不同的任务类型,包括漏洞修复、功能实现、代码重构等,同时包含完整的任务要求,以确保模型的实现与测试补丁一致。
基于RepoLaunch框架搭建了环境构建流水线,实现了真实SWE issue可执行环境的规模化构建。该流水线会自动分析代码仓库的安装与依赖配置,构建可执行环境并生成测试命令,同时利用大模型生成具备语言感知能力的日志解析函数,实现F2P与P2P测试用例的提取。借助该流水线,在覆盖 9 种编程语言(包括 Python、Java、Go、C、CPP、JavaScript、TypeScript、PHP 与 Ruby)的数千个代码仓库中,构建了超 10000 个可验证环境。
**终端环境:**为规模化构建可验证的终端智能体环境,设计了一套智能体数据合成流水线,包含三个阶段:任务草稿生成、具体任务实现,以及迭代式任务优化。从收集的真实软件工程场景与基于终端的计算机使用场景种子任务出发,利用大模型生成大量可验证的终端任务草稿。随后,这些草稿会被实例化为Harbor格式的具体任务,包括结构化的任务描述、Docker化的执行环境,以及对应的测试脚本。接下来,会根据人工定义的评分规则,对生成的任务进行多轮检查与迭代优化,确保Docker镜像可稳定构建、测试用例与任务规范一致,同时环境能够抵御潜在的捷径攻击。整体来看,该流水线生成了数千个多样化、可验证的终端智能体环境,Docker 构建准确率超过 90%。
另外,开发了一套可扩展的自动化流水线,基于网页语料构建经大模型验证的终端编码任务,采用闭环设计,负责构建任务的智能体同时也是首轮验证者。首先,收集了大规模的代码相关网页语料,应用数据质量分类器,仅保留高质量代码内容,丢弃以非技术内容为主、缺乏实质性代码的页面。从过滤后的子集中,进一步识别出适合转化为终端风格任务的网页,再按主题类别与难度层级进行分层采样,确保最终任务库的分布均衡与多样性。其次,提示编码智能体,结合选中的源网页内容,生成完整的终端任务构建规范,包括任务模式、格式要求、示例任务。要求智能体:(i) 基于网页内容合成完整的终端任务规范;(ii) 针对自身的输出,执行Harbor验证脚本。若验证失败,智能体需要迭代诊断并修改任务,直至通过所有自动化检查。只有成功完成自验证闭环的任务,才会被纳入最终数据集。
**搜索任务:**针对深度搜索信息查询任务,构建了一套数据合成流水线,用于生成高难度的多跳问答配对数据。每个问题都需要基于多个网页来源的证据,完成多步推理才能解答。
网络知识图谱构建与问题生成:从早期搜索智能体的轨迹中,收集并去重了所有遇到的 URL,保留了跨多个领域的超200万个高信息密度网页。大模型会对这些网页进行语义解析,完成实体识别、噪声过滤,以及结构化信息提取。会持续用新页面更新WKG,并通过下游验证信号优化 WKG,包括实体对齐、属性规范化、关系合并,以及语义一致性修正。
基于WKG,对低频-中频实体作为种子节点进行采样,扩展其多跳邻域形成完整子图,同时控制图的扩展范围以减少重叠。通过面向高难度、多领域、多步推理的提示词,将每个子图转化为隐式编码了多实体关系链的问题。
高难度问题过滤与验证:采用三阶段流水线,平衡问题的难度与正确性:移除无工具推理模型在8次独立尝试中至少能正确回答一次的问题;过滤掉早期智能体仅需几步基础搜索、浏览与计算就能解决的问题;
应用验证智能体进行双向验证:收集第2阶段中搜索轨迹的候选答案,再独立验证候选答案与标注真值的问答一致性,同时验证两个候选答案与标注真值的一致性,剔除答案不唯一、证据不一致、标签错误的样本。最终得到了高质量、高难度、可靠的多跳问答配对数据。
**搜索智能体的上下文管理推理:**发现模型在BrowseCompbenchmark上的表现,对评判提示词与评判模型都高度敏感,开源评判器可能会引入系统性偏差。为确保一致性与可复现性,使用 OpenAI 官方的评估提示词与专属的 o3-mini 模型作为所有基于评判的组件的标准。
Discard-all策略会在重置上下文时,清除工具调用的全部历史。进一步发现,在极长上下文(如超过 10 万 token)下,模型的准确率会显著下降。受此启发,采用了一种简单的保留最近 k 轮策略:当交互历史超过阈值k轮时,早于最近k轮的内容会被折叠,以控制上下文长度。
基于该策略,将保留最近 k 轮与全丢弃策略结合,形成了混合的分层上下文管理策略。在推理过程中,当上下文长度超过阈值T时,会丢弃全部工具调用历史,以全新的上下文重启,同时持续应用保留最近 k 轮策略。通过参数搜索,选定T=32k。
如图所示,在不同的计算预算下,该策略能有效释放上下文空间,让模型能够执行更多步骤,持续提升性能。与单独使用全丢弃策略相比,结合保留最近 k 轮策略后,模型在所有预算下都获得了稳定的性能提升,最终得分达到 75.9,超过了所有配备上下文管理的开源模型。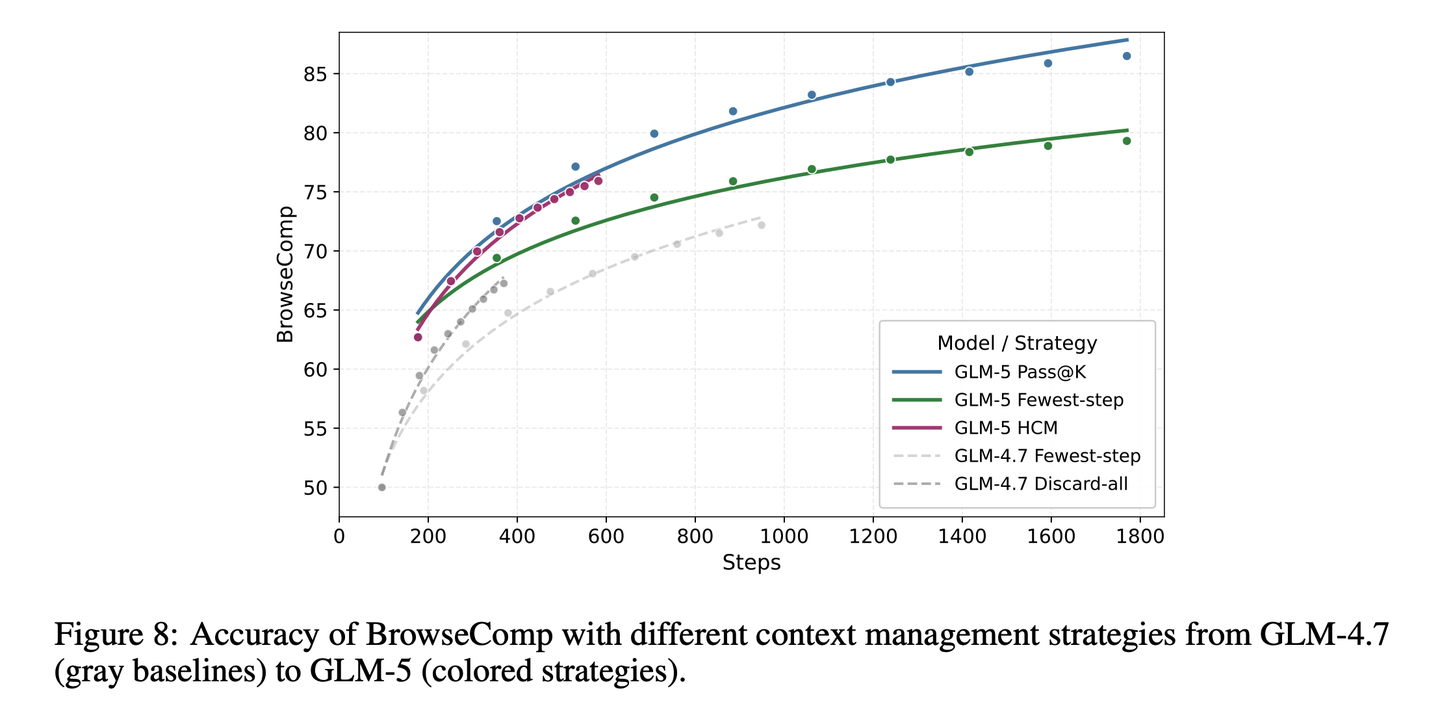
**幻灯片生成:**采用了一套自优化的流水线,旨在通过强化学习与拒绝采样微调,系统性地提升幻灯片生成性能。首先通过SFT初始化模型,使其具备基础的幻灯片生成能力,随后基于演示幻灯片的通用美学与结构特性,设计了多层级奖励公式,开展强化学习。该阶段让生成质量获得了大幅提升。进一步执行拒绝采样微调,让强化学习中习得的知识能够注入训练语料中。该流程以协同迭代的方式,同步提升了数据质量与模型能力。
提出了多层级奖励公式,将基于 HTML 的幻灯片生成过程中的奖励信号划分为三个层级:- 层级 1:静态标记属性。该层级聚焦于生成的 HTML 中的声明式属性,包括位置、间距、颜色、排版、饱和度,以及其他风格属性。基于专业的设计原则,设计了一套规则,约束模型生成这类声明时的行为。这些规则既保证了生成 HTML 的语法可解析性,同时在标记层将设计空间约束在一个优化的子空间内,兼顾表现力、结构清晰度、视觉和谐度与可读性。此外,引入了幻觉图像检测与重复图像检测机制,抑制幻觉或冗余的图片生成。- **层级 2:运行时渲染属性。**与静态属性不同,该层级会评估渲染过程中 DOM 节点的运行时属性,比如元素的宽高、边界框,以及其他几何布局指标。通过约束这些属性,引导生成的幻灯片在空间布局上更贴合人类的美学偏好。开发了一套分布式渲染服务,能够高吞吐量地执行渲染任务,同时提取所需的运行时属性。在训练过程中,发现了多种奖励破解行为,比如硬截断超长内容、过度调整间距。为缓解这类问题,优化了渲染器的实现,消除了可被利用的漏洞,确保奖励信号能够真正激励美学协调的布局,而非表面上的规则合规。- 层级 3:视觉感知特征。除运行时渲染约束外,还对渲染后的幻灯片加入了感知层级的评估。例如,将异常的空白布局模式作为辅助信号,进一步优化整体的构图平衡与视觉美学。
训练策略:在RL阶段对这些信号进行联合优化,以提升生成 HTML 的结构有效性、优化布局组织,同时提升整体的视觉美学质量。除奖励设计外,通过动态采样调整训练数据分布:具体而言,会按概率丢弃结构简单的样本,让优化聚焦于更具挑战性的页面,提升模型在复杂构图场景下的鲁棒性。还采用了token级的策略梯度损失,以稳定优化过程。此外,引入了一套均衡策略,将同一样本的不同轨迹采样结果分配到多个训练批次中,降低优化偏差,提升训练稳定性。
拒绝采样:在拒绝采样阶段,将RL中使用的奖励函数迁移到数据过滤流水线中,构建高质量的训练子集。在页面层级,过滤标准包括代码有效性与编译可行性;在轨迹层级,进一步强制执行工具执行正确性与全局内容多样性约束,确保结构一致性。采用best-of-n的选择策略,从多个独立生成的候选样本中保留质量最高的样本。该机制能有效将数据分布向高质量样本倾斜,提升样本效率,增强训练稳定性。
基于掩码的优化:尽管拒绝采样能过滤掉大部分低质量输出,但部分轨迹的缺陷仅集中在少数页面中。丢弃这类样本会降低有效数据利用率,提升生成成本。为解决该问题,引入了一套基于掩码的修正机制:**自动识别缺陷页面,对其应用mask,同时保留同一条轨迹中的高质量内容。**这种选择性优化保留了有价值的监督信号,提升了有效数据效率,同时减少了冗余的重新生成开销,进而提升了整体训练效率。
实验效果:严格符合 16:9 宽高比的生成页面占比从 40% 提升至 92%,同时页面溢出的情况大幅减少。人工评估结果进一步显示,与GLM-4.5相比,GLM-5 在内容质量上的胜率为 60%,布局合理性胜率为 57.5%,视觉美学胜率为 65%,综合胜率达 67.5%。
GLM-5通过与华为昇腾、摩尔线程、海光、寒武纪、昆仑芯、MetaX、燧原这七大主流国产芯片平台的深度合作,成功实现了全栈适配,适配了两大主流推理引擎vLLM-Ascend与 SGLang。### 评估
ARC评估 / 推理 / 智能体评估:****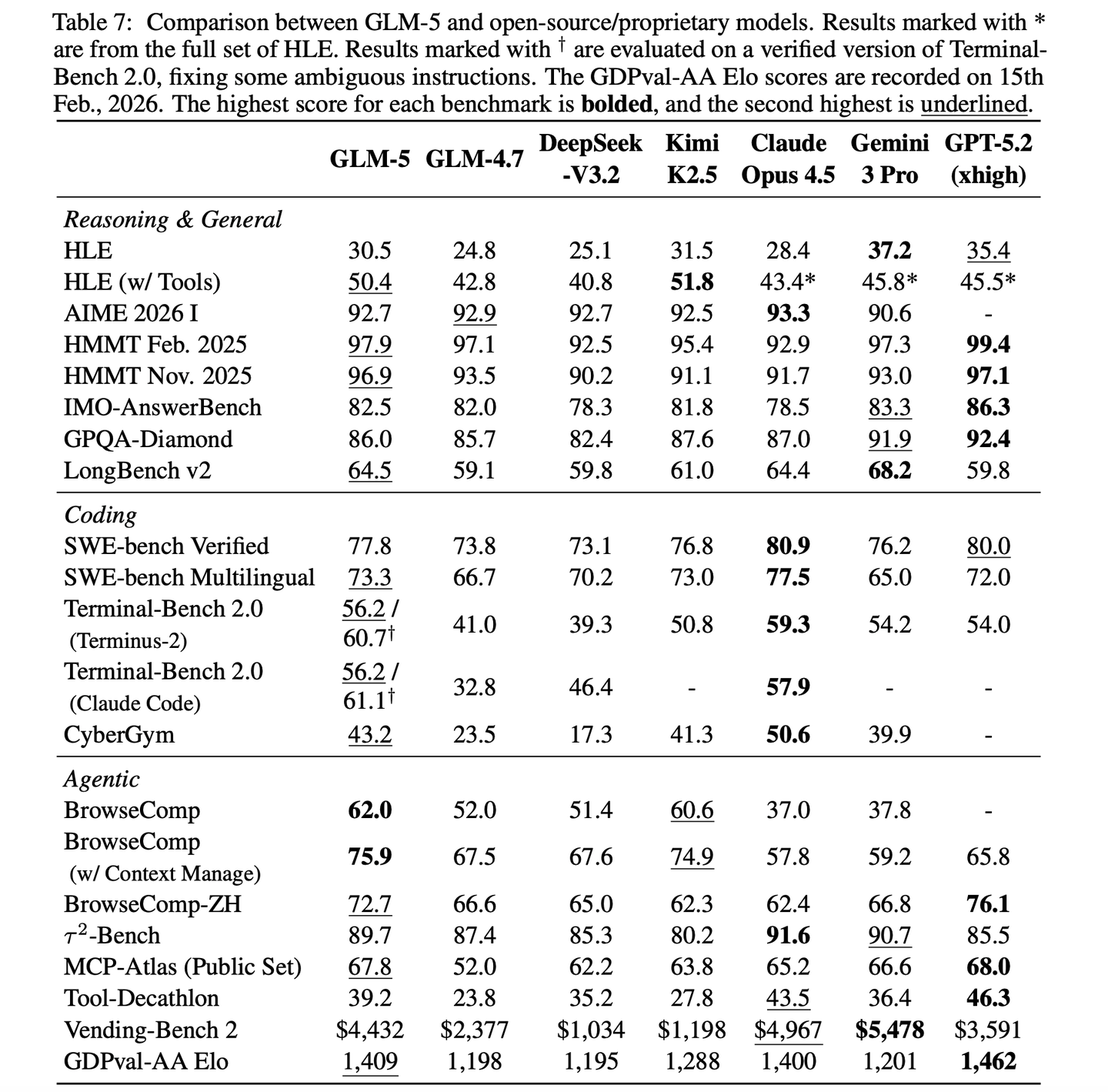
真实世界智能体工程体验评估
CC-Bench-V2用于评估模型能否在真实的智能体工程环境中,正确完成端到端任务,覆盖前端、后端与长周期任务。CC-Bench-V2完全移除了人工标注环节,通过单元测试与智能体评判(Agent-as-a-Judge)技术实现全自动化评估。
前端:通过流水线先构建智能体生成的前端项目,检查语法、依赖与兼容性错误。随后,使用智能体评判机制,通过搭载 Playwright与bash工具的GUI智能体模拟用户交互,验证端到端的正确性。
后端:任务来自真实世界的开源项目,覆盖 C++、Rust、Go、Java、TypeScript与Python,包括功能实现、漏洞修复、回归修复与性能优化。每一项修改都必须在真实的工程约束下,通过完整的单元测试。
长周期:首先评估模型在大型代码库中的信息检索能力,随后,通过挖掘合并历史丰富的拉取请求、将提交聚类为连贯的任务链,构建了多步链式任务,评估端到端的正确性。智能体需要按顺序执行这些任务链,测试其在不同阶段保持上下文、解决依赖的能力。评估结合了单元测试与智能体评判,同时验证功能正确性与语义一致性。
前端评估:
静态验证:首先验证生成的代码能否成功构建与运行。对于能正确执行的代码,使用 GUI 智能体模拟人类测试行为,交互式验证每个检查项,并根据需求的完成情况分配分数。
定义了以下指标:- 构建成功率(BSR):衡量成功初始化并运行的项目比例;- 实例成功率(ISR):衡量通过所有相关规范检查的项目比例;- 检查项通过率(CSR):衡量所有检查项的细粒度完成率。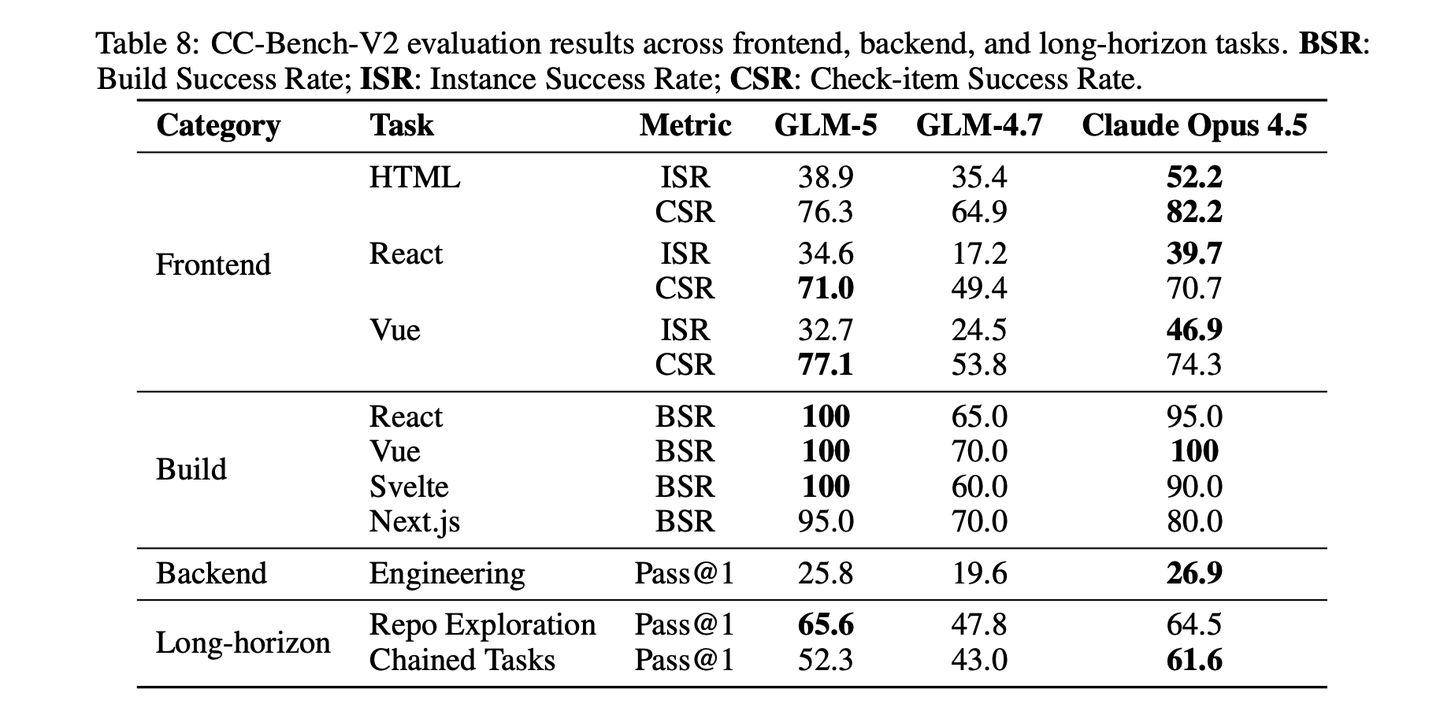
智能体评判机制:前端的正确性本质上是视觉化、交互式的,bug往往只会在用户点击按钮、调整窗口大小时才会暴露,这使得静态分析与固定测试套件存在局限性。因此,引入了智能体评判机制:每个生成的项目都会被部署到Docker容器中并完成构建,以验证静态正确性。成功构建的实例会被交给一个自主的评判智能体(搭载 Claude Code with Claude Sonnet 4.5,配备 Playwright MCP工具),它以闭环循环的方式运行:针对每个检查项,智能体读取源代码、与实时 UI 交互(点击、按键、截图)、检查终端输出,最终给出通过/失败的判定。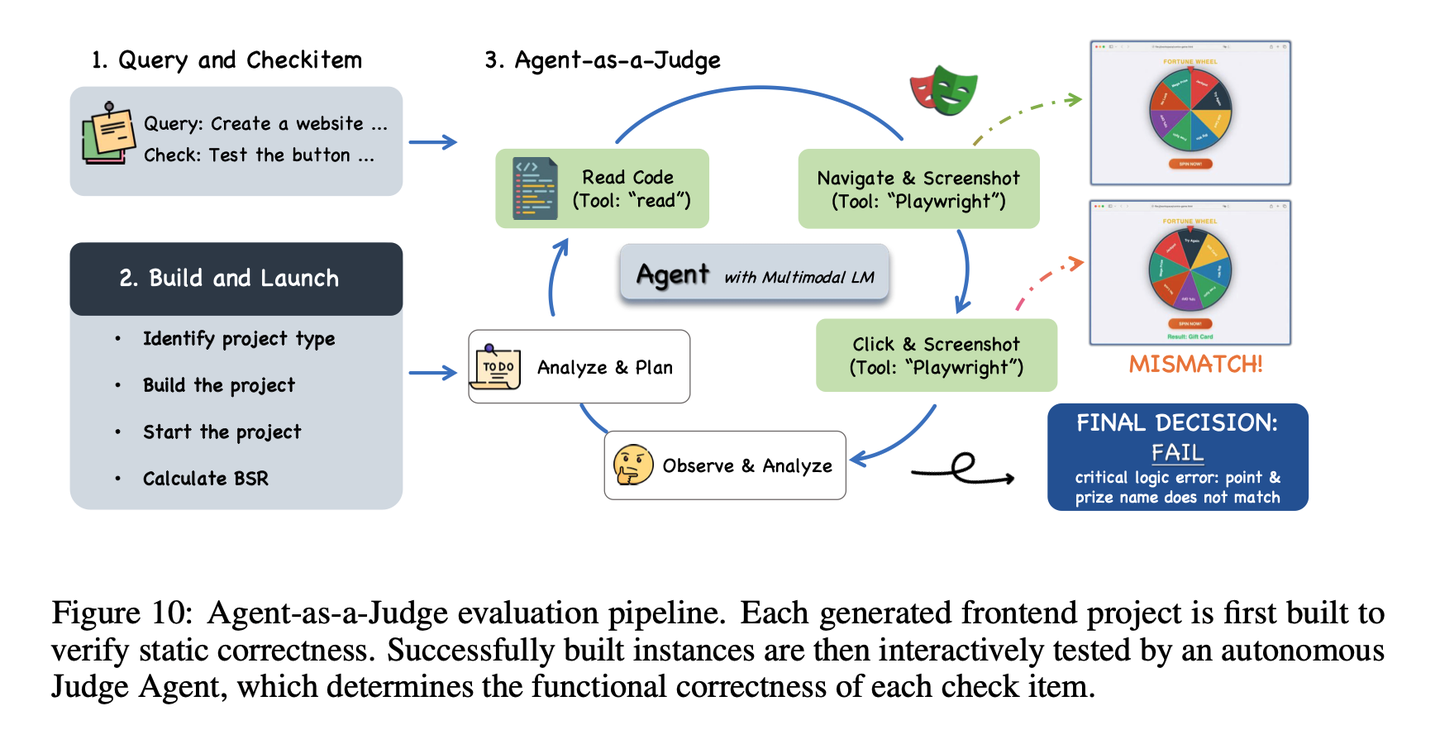
为验证可靠性,将智能体评判的结果与独立的人类专家判定进行了两个维度的对比。在逐点一致性方面,采样了130个检查项,由人类专家独立打分,并与智能体的判定结果对比:两者在 94% 的条目上达成一致,分歧主要集中在主观视觉质量标准,而非功能规范。在排名一致性方面,使用自动化框架与人类专家,对 8 个前沿模型(Claude Sonnet 4.5、Claude Opus 4.5、Gemini 3 Pro、GLM-4.7、DeepSeek-V3.2 等)进行了评估,最终模型排名的斯皮尔曼相关系数达到 85.7%,证明了强正相关。
**后端评估:**后端评估衡量编码智能体能否在真实的工程约束下,对真实世界的服务端代码库做出正确的、可通过测试的修改。整理了85项任务,覆盖6种编程语言(Python、Go、C++、Rust、Java、TypeScript),领域包括搜索引擎、数据库引擎、web 框架、AI 推理服务、知识管理系统,以及独立的算法与系统编程挑战。任务类型包括功能实现、漏洞修复、回归修复与性能优化,反映了日常后端开发的多样性。为实现全自动化评估,每个任务都配备了人工编写的单元测试(每个任务 5-10 个),同时验证功能正确性与边界场景处理能力。任务以 Terminal-bench 风格打包,运行在 Docker 容器中,容器内已初始化好项目的实际构建环境:智能体接收自然语言问题描述,说明需要完成的修改。只有当所有相关单元测试全部通过时,才认为任务被解决。
**长周期评估:**长周期评估针对的,是区分生产级智能体工程与单轮直觉式编码的核心能力:在海量代码库中导航、执行多步开发任务,且每一步操作都会改变后续步骤的上下文。将其拆解为两个互补的任务。
大型代码库探索:任何非trivial编码任务的前提,都是在大型、不熟悉的代码库中定位正确源文件的能力。在包含数万个文件的真实高星 GitHub 仓库上,构建了一套自动化benchmark。每个问题都以自然的、面向用户的语言描述,粒度为业务语义级别,严格避免提及文件名、类名或函数名。此外,大多数问题都需要从用户描述到实际实现,进行一到两跳的逻辑推理。
多步链式任务:SWE-bench 等主流编码benchmark,将评估简化为单次提交、孤立的代码修改,因此无法评估智能体执行增量开发的能力,在这类场景中,每一步操作都会改变代码库状态,影响后续步骤。为解决这一问题,通过挖掘高质量代码仓库中已合并的拉取请求,构建了一套长周期benchmark,并通过以下流水线组装任务链:- 拉取请求过滤:仅保留包含测试用例、含3-15次提交、且遵循线性(无合并)提交历史的已合并拉取请求。- 语义分组:由大语言模型对相邻提交的两两语义相关性进行打分;通过动态规划,将提交最优划分为连贯的任务组,在保留提交顺序的同时,最大化组内语义一致性。- 补丁分类:将每个任务的累计差异拆分为三类:黄金补丁(智能体必须生成的核心代码)、测试补丁(验证用测试用例)、自动应用补丁(自动生效的配置与固定代码)。- 问题描述生成:由大语言模型根据每个任务的补丁与提交信息,生成自然语言的问题描述。- 任务分类:自动对任务进行分类(功能开发 / 漏洞修复 / 代码重构 / 测试 / 配置),并从三个维度进行评估:错误消除能力、关键路径准确率、测试通过率。- 环境验证:构建Docker环境,并应用黄金补丁,验证整个任务链无回归问题。
对于包含K个任务的链条,智能体从基础提交开始,按顺序执行:完成任务k后,提交其修改,并应用任务k+1的自动应用补丁,代码库状态随之累计演进。评估会依次检查每一次提交,在运行完整测试套件前,累计应用任务1到k的测试补丁,同时捕获当前任务的执行失败,以及对早期任务的回归问题。这种链式、状态递归的设计,直接评估了单次提交benchmark无法覆盖的长程上下文追踪、规划与增量开发能力。
动态演进的SWE任务评估:选择在SWE-rebench上进行评估,原因是SWE-bench Verified 是一套静态、公开、经人工验证的测试集,已发布超过2年。与之相反,SWE-rebench 基于自动化流水线构建,持续挖掘新鲜、真实的 GitHub 问题修复任务,能够实现无数据污染、时间鲁棒的评估,更好地衡量模型对全新软件工程问题的泛化能力,而非在静态benchmark上的表现。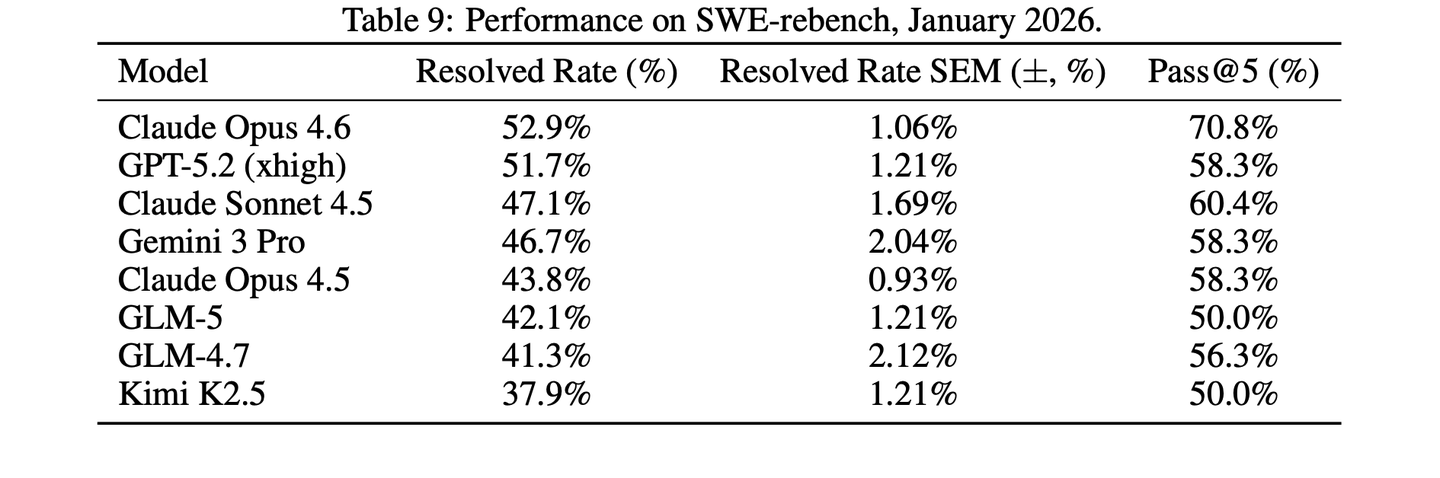
尽管标准化的学术benchmark能提供有效的参考信号,但它们无法完全还原模型在实际场景中的使用方式。为弥补这一差距,基于部署环境中观察到的高频用户交互模式,在一系列真实世界通用能力上对 GLM-5 进行了评估,这些能力包括机器翻译、多语言对话、指令遵循、世界知识与工具调用。与传统的以benchmark为核心的评估不同,目标是衡量能直接转化为用户可感知的质量提升的改进。针对每项能力,结合了内部人工评估、内部自动化评估、外部人工评估与外部自动化benchmark,同时保证评估的诊断粒度与跨模型可比性。在使用外部benchmark时,优先选择能反映真实交互模式的数据集,而非窄范围构建的测试分布。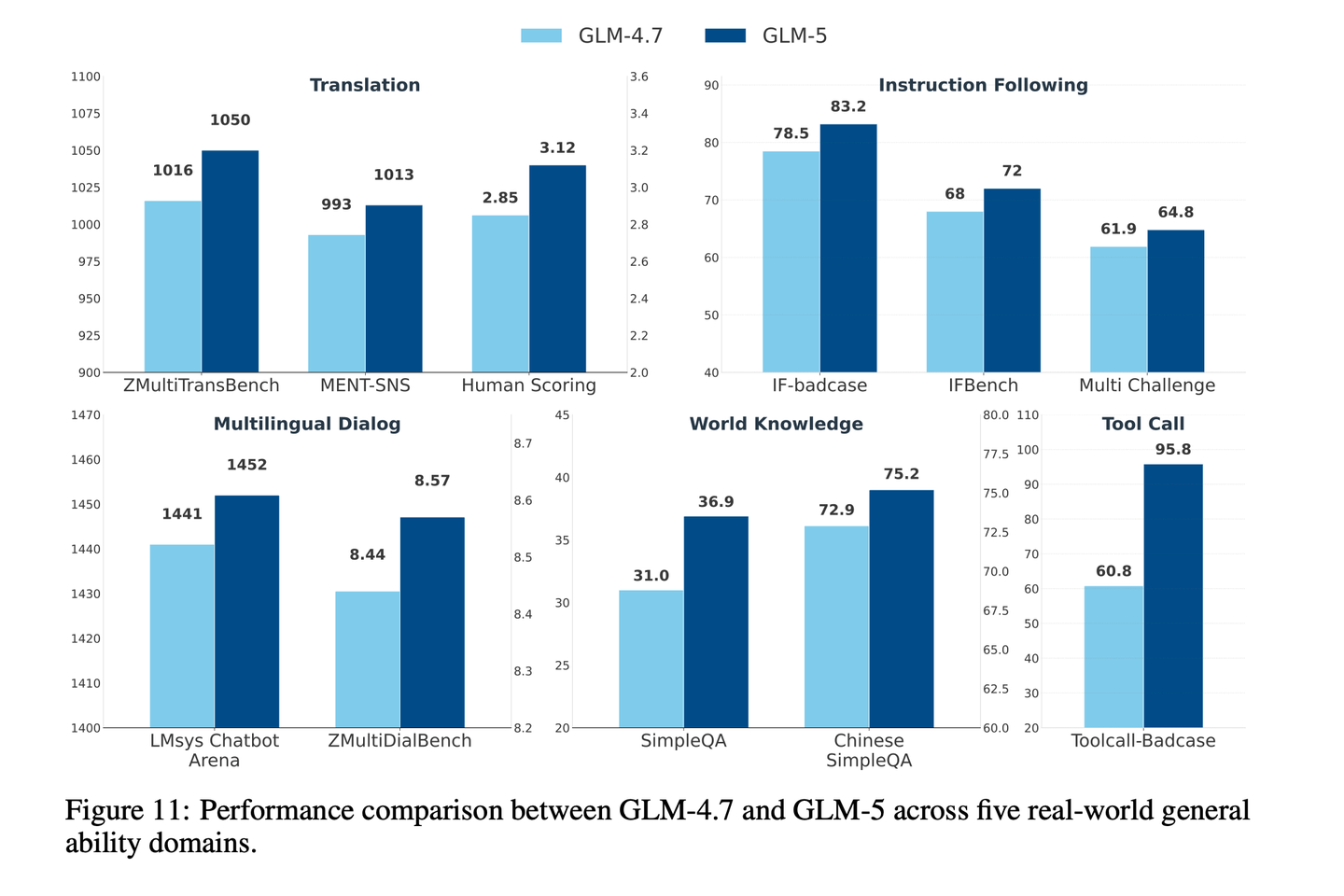
评论