
快速摘要: Ring-lite是基于Ling-lite模型的MoE架构推理模型,拥有16.8B总参数和2.75B激活参数,在AIME、LiveCodeBench、GPQA-Diamond上达到同规模模型的SOTA水平。论文提出C3PO(Constrained Contextual Computation Policy Optimization)算法,以token-level粒度对response进行截断,解决了GRPO算法中response长度波动导致的训练不稳定问题。论文还发现SFT训练更多epoch后RL训练更容易出现entropy崩塌,因此建议基于entropy损失而非验证指标选择蒸馏检查点。训练采用两阶段范式(先数学后代码),避免混合数据集训练时的领域冲突。
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
本文提出Ring-lite,一个MoE的大型语言模型,基于Ling-lite模型(16.8B参数、激活参数2.75B),在AIME、LiveCodeBench、GPQA-Diamond上,性能可以达到小模型的SOTA。本文C3PO(Constrained Contextual Computation Policy Optimization)算法,能够提高训练稳定性并提升计算吞吐量。其次,本文通过实验证明,在强化学习训练中基于熵损失而非验证指标选择蒸馏检查点,在后续的强化学习训练中能带来更优的性能-效率平衡。最后,本文使用两阶段的训练范式,以协调多领域数据的集成,避免使用混合数据集训练时出现不同领域的冲突。
Ring-lite在benchmark上的评估结果如下: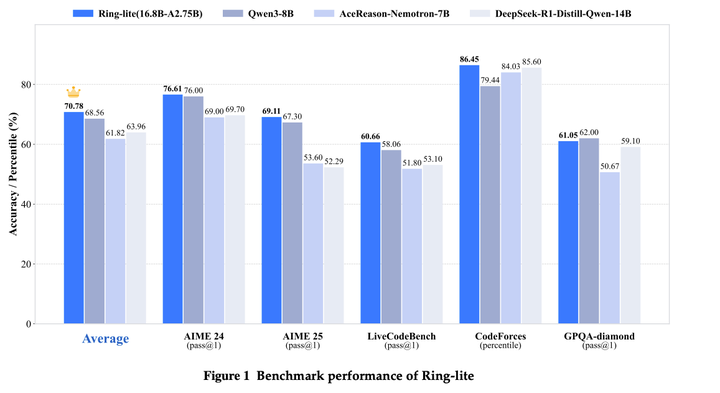
论文分别从数据收集过程,强化学习训练框架,和评估介绍Ring-lite模型。### 数据收集
训练数据集由两个部分组成:(1) 用于训练冷启动模型的Long CoT SFT数据;(2) RL数据。
Long CoT数据:使用LLM生成回复,然后检测并去除重复模式、语言混合和其他噪声。最终数据主要由三个领域构成:数学(64.5%),代码(25.5%)和科学(9.2%)
RL数据:同样包括数学,代码和科学数据。- 数学:包括开源数据集BigMath、DeepScaleR、DAPO、DeepMath-103K等。为了进一步扩展数据集,爬取了在线数学论坛并收集了真实的学校考试题目。从AoPS网站的竞赛板块提取了问题。此外,收集了高中和大学学校考试和数学竞赛中使用的人为编写的问题。然后,对数据进行严格的清理和过滤,以确保质量,最终产出73000个高质量数学问题。- 代码:包括开源数据CodeContest,TACO, APPS,另外还有一些来自QQJ在线评判平台的数据。为确保数据质量和训练适用性,实施了多阶段过滤。首先,删除了存在格式不一致(如错误的换行符或多余空格)以及带有用省略号标记的截断内容或不完整测试用例的数据。之后,所有Accepted的解决方案都在代码沙盒环境中经过了严格的验证。这一验证步骤会过滤掉存在未解决外部依赖项的数据,以及由于计算效率低下(例如,对于n > 10⁵的O(n²)算法)或内存溢出漏洞而未能通过扩展测试用例的数据。之后会通过规范空格约定和统一跨平台的浮点精度阈值来实施输出标准化,以减轻评估标准中的不一致性。为确保完整性,仅保留了至少有一个完全验证的AC解决方案且能够通过所有相关测试用例的问题。并且会应用语义去重来从代码benchmark中删除重叠问题,避免数据污染。最终整理的数据集包含14000个代码样本,每个样本都附有经过验证的可执行解决方案和严格验证的测试用例。- 科学:首先收集了如Nemotron-CrossThink,SCP-116K等开源数据集。并且采用了SHARP合成流程来生成更困难、可验证的问题。之后,从先进自然科学领域提取的专有高难度、人工标注的科学问题集合。来源包括奥林匹亚竞赛和研究生水平(硕士和博士)考试。然后,应用了严格的整理过程,包括质量过滤、答案验证和特定领域标记,最终得到了一套适用于强化学习的3833个高质量科学问题。
**数据清理:**严格地清理数据,避免数据污染。- 数据清理:排除具有无效字符、图像、多个子问题以及缺乏有效答案的问题。对数据集进行严格的基于字符和语义的去重和去污处理。还删除了无法唯一解决或容易被猜到的问题,例如多项选择题以及可以用"真/假","是/否"回答的问题。- 答案验证:为确保数据集中答案的正确性,使用了多种方法进行彻底验证。采用基于大语言模型的方法来评估每个答案的质量,利用不同规模的大语言模型为每个问题生成多个单独的解决方案,计算通过率。此外,也会请人类专家手动标注答案。未通过任何一种验证方法的问题都会从数据集中移除。- 数据标注:为优化数据选择策略,对每个问题进行细致标注。每个问题都标注有多维属性,如数据来源、教育水平、特定领域知识等。使用Mathematical Subject Classification(MSC)类别来评估数学问题的主题。此外,会计算模型的解决率来标注问题的难度。所有回复都正确的问题被认为对强化学习训练效率不高,会删除这些问题。同样,蒸馏模型和DeepSeek-R1都无法解决的问题也会被丢弃。### 训练策略
GRPO算法会有response长度偏差,进行长度归一化的时候会减弱较长序列的梯度。DAPO通过token-level loss解决了这一问题,但仍然无法避免response长度波动较大的问题。
本文提出C3PO算法,以token-level的粒度对response进行截断: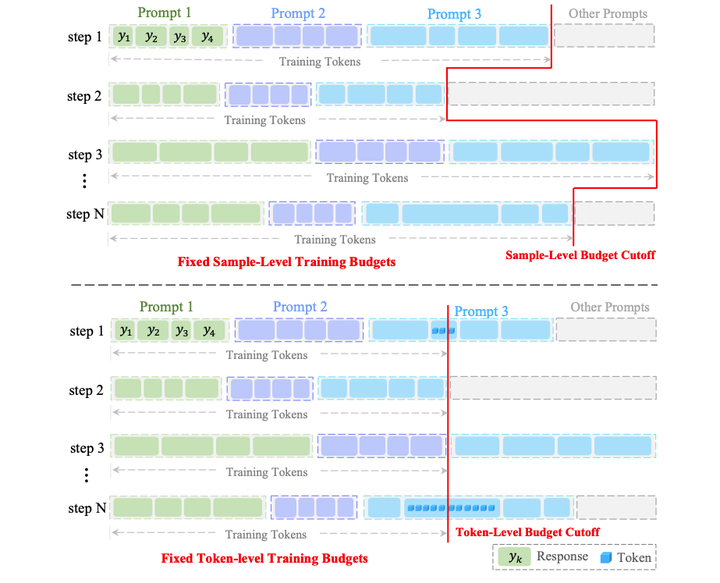
生成response之后,正常计算reward和advantage,但在计算loss时根据token的budget对数据进行截断,只优化固定token数的数据。
这样做的好处是可以使response的长度较为固定,避免数据的长短不齐的波动,同时达到了使用token-level loss的效果。
另外,Ring-lite也使用了entropy loss:
以及MOE的负载均衡loss和router z-loss:
最终loss为上述loss加权: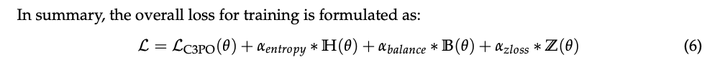
**奖励函数:**Math采用Math-Verify,Code用沙盒评估,都是0/1 reward。
**训练流程:**RL两阶段训练,先训练数据,再训练代码。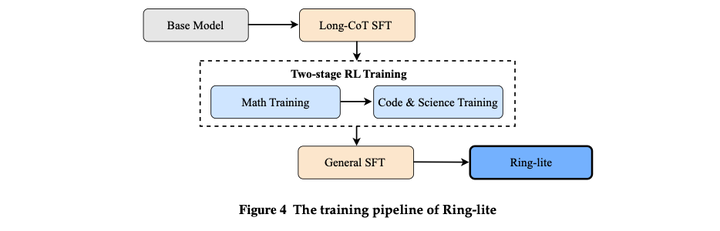
entropy loss系数可以提高最终表现:对Ling-Lite 1.5进行微调,SFT阶段batch size=256,训练3个epoch,32 K长度,RoPE设置为600000。RL训练,batchsize设置为512,每条数据采样16次,token-budget设置为409600,最大长度设置为24576,并且第二阶段调整为32768。
对比的baseline为Qwen3-8B-Thinking,Qwen3-8B-Thinking, R1-Distill-Qwen-7B, R1-Distill-Qwen-14B,AceReason-Nemotron-7B,Ring-lite-distill-preview。评估时 temperature =1.0, top-p=0.95,最大生成长度为32768。
评估结果如下: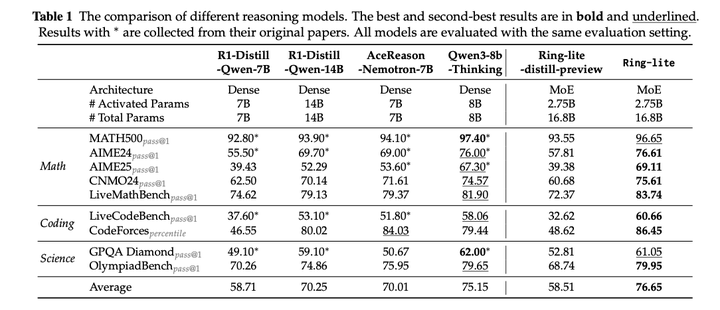
本文发现,在SFT训练更多epoch后,RL训练时更容易崩溃,entropy更低,更容易坍缩: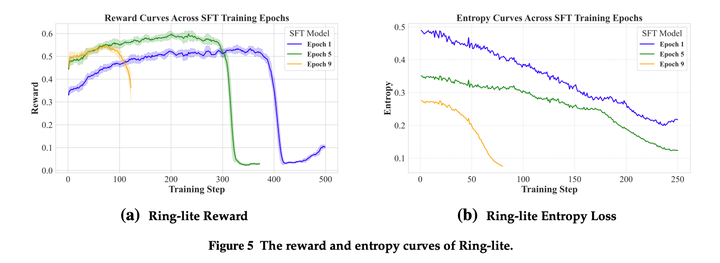
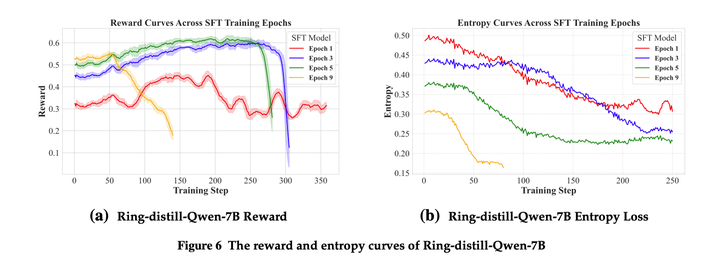
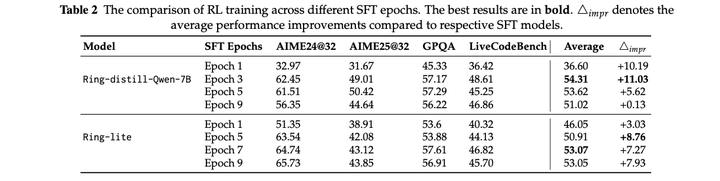
这表明SFT后模型entropy过低对应于后续强化学习阶段奖励崩溃的可能性更高。
Token efficiency(RL训练token量/SFT训练token量)对比: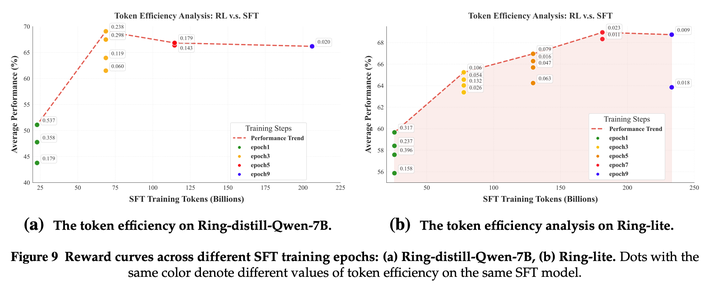
另外,C3PO可以排除response长度的波动带来的影响。GRPO的gradient norm显著更高,影响训练的稳定性。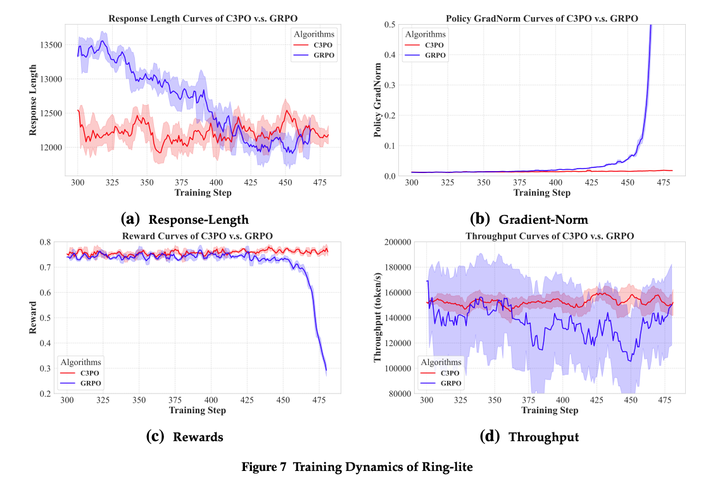
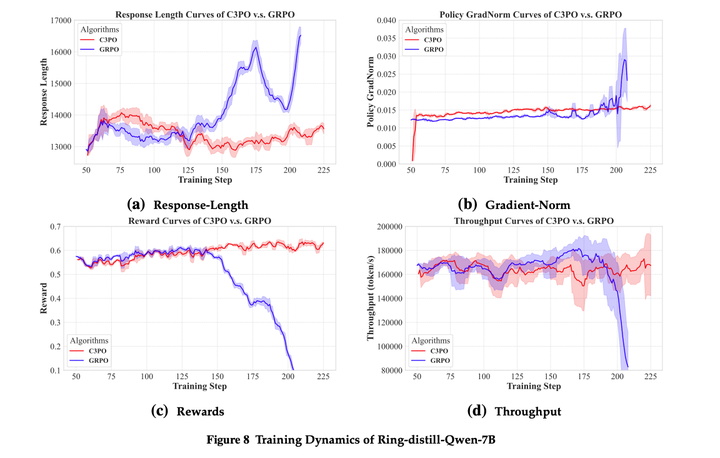
另外,在GRPO算法中较长的response序列需要更长的计算时间,而较短的response则未能充分利用计算资源,从而降低了吞吐量效率。C3PO的吞吐量会更稳定。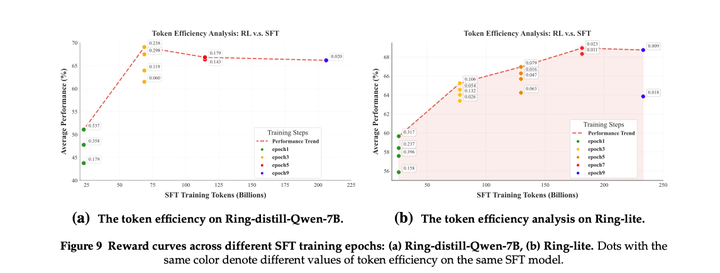
另外,本文还实验验证了,代码和数学混合训练会对数学产生干扰。训练数学则对训练代码则有促进作用: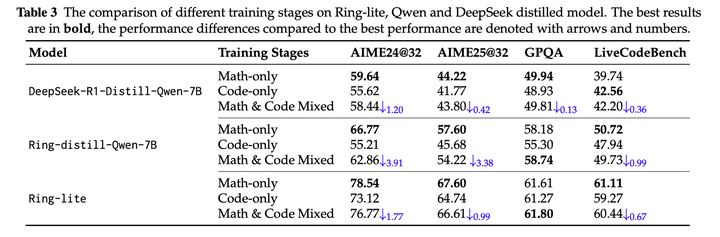
多阶段训练要优于直接混合训练: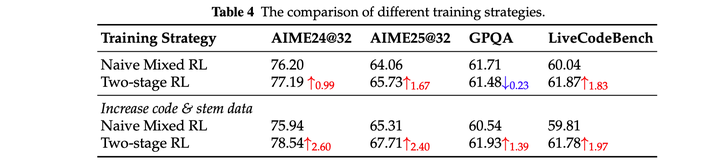
评论