

快速摘要: Composer 2是Cursor推出的专门面向agentic软件工程的模型,基于Kimi K2.5(1.04T总参数、32B激活参数的MoE模型)进行持续预训练和大规模异步强化学习。该模型提出Self-Summarization技术以处理长时程任务,并通过非线性长度惩罚激励模型在简单任务上快速响应、复杂任务上深度思考。文章还提出了CursorBench真实世界评估基准,揭示了公开benchmark与真实开发者使用场景之间的结构性错位,并详细介绍了涵盖MoE并行化、NVFP4低精度训练、Anyrun计算平台等在内的完整训练基础设施。
论文Composer 2 Technical Report
Composer 2是一个专门面向agentic软件工程的模型。该模型在保持能够高效解决交互式使用场景中问题的同时,展现出很强的长期规划能力和编码智能。在CursorBench上表现突出。同时,该模型在公开软件工程基准上也达到前沿水平。
该模型分两个阶段训练:首先,通过持续预训练来提升模型的知识和潜在编码能力;随后,通过大规模强化学习来提升端到端编码性能,使模型在长期、真实的编码问题上具备更强的推理能力、更准确的多步执行能力以及更好的连贯性。
Composer训练的一个核心原则,是尽可能贴近真实世界中的用户挑战,以最小化训练和测试之间的不匹配。开发了一套基础设施,使训练能够在与部署模型相同的 Cursor harness 中进行,并具备等价的工具和结构;同时使用尽可能贴近真实问题的环境。为了衡量模型在越来越困难任务上的能力,引入了一个来源于大型代码库中的真实软件工程问题的benchmark测试集。在CursorBench评测中,相比之前的Composer模型,该模型的准确率取得了显著提升。在公开测试中,Terminal-Bench 得分为 61.7,SWE-bench Multilingual 得分为 73.7,与当前最先进水平相当。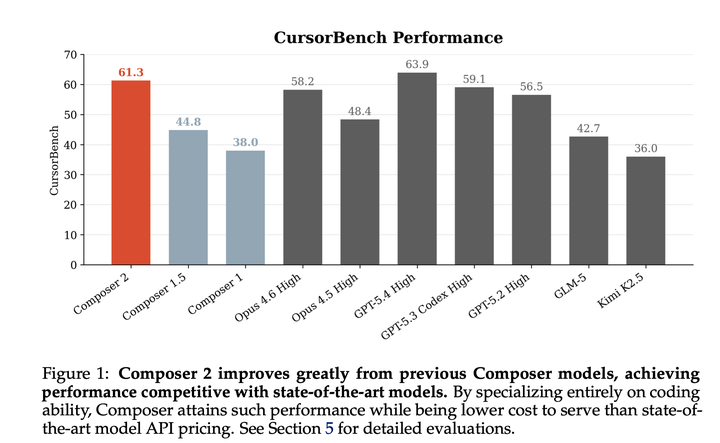
与竞赛编程这类更受约束的场景不同,一个强大的软件工程智能体必须能够进行探索,编写自己的测试,并构造出解决任务提示所需的最小修改。
Composer 2可以访问一小组通用工具,能够读取和编辑文件、运行shell命令、使用grep或语义搜索来搜索代码库,以及搜索网页。prompt包括系统消息、工具调用格式规范、最近的文件信息、过去的用户消息,以及当前任务。这个过程最常见的最终结果,是对代码库环境中的文件进行一组修改。不过也有许多其他常见用途,例如回答问题、编写计划、解决版本控制问题,或监控长时间运行的任务。
Composer 2d的训练分为两个阶段:持续预训练,以及异步强化学习。### Continued Pretraining
持续预训练阶段旨在提升语言模型的基础知识,尤其是在编码领域的知识。实验表明,额外的监督学习能够稳定提升知识类基准测试表现,并带来最终编码智能体性能的提升,所以选择了经过后训练的模型作为base模型。
使用内部评测和推理性能方面的考虑来选择基础模型。评测指标包括内部代码库困惑度、编码知识以及状态跟踪能力。使用Kimi K2.5作为Composer 2的base模型。Kimi K2.5 是一个混合专家模型,拥有1.04T 总参数量和32B激活参数量。
训练:在一个大规模、以代码为主的混合数据集上,对Kimi K2.5进行了持续预训练。该阶段的目的是通过让模型专门学习编码知识和能力,为后续的Agentic RL训练提供一个基础模型。将该阶段划分为三个阶段。**大部分计算量用于32k token序列长度的训练;随后进行一个较短的长上下文扩展阶段,将序列长度扩展到256k;最后,在目标编码任务上进行一个较短的SFT 阶段。**训练在 NVIDIA B300 上使用 MXFP8 进行,并采用AdamW优化器。在训练过程中,测量模型在内部代码库上的evaluation loss,观察到,在整个训练过程中,该loss呈对数线性下降。
持续预训练最终服务于提升下游强化学习性能。通过将持续预训练方案应用到Qwen3-Coder-30B-A3B上,研究代码库困惑度与强化学习性能之间的关系。持续预训练在三个按对数间隔划分的计算规模上进行:小、中、大。随后,每个checkpoint都会在一个小数据集上进行 SFT,然后再进行相同设置的强化学习训练。下图展示了SFT后最终损失与固定步数后强化学习奖励之间的关系,说明交叉熵损失确实能够预测下游强化学习性能。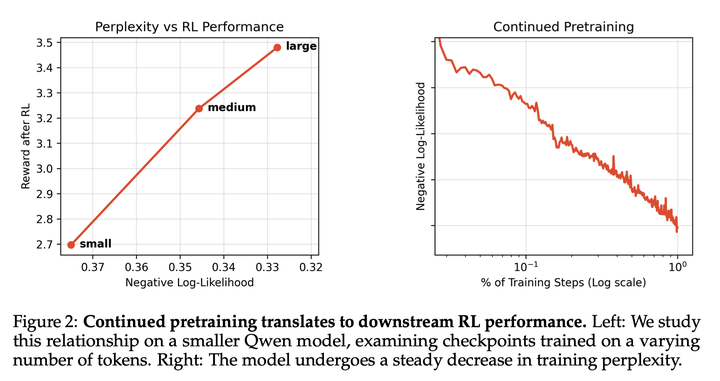
**Multi-Token Prediction:**为了让模型在生产环境中服务得更快,额外训练了MTP层,用于推测解码。从零开始初始化MTP层,并在相同的数据混合集上训练它们。为了加快收敛,使用自蒸馏训练MTP层,让模型在每个位置预测主语言模型头的精确logits分布。为了确保这一过程能够泛化,MTP 层是在持续预训练中途截取的checkpoint之上训练的。在最后两个阶段,即长上下文阶段和 SFT 阶段,MTP层会被纳入模型,并与模型其余部分联合训练。### 强化学习
Composer 2 通过在大量编码任务上进行强化学习来训练。这些任务运行在尽可能贴近真实Cursor 会话的环境中。构建了一个能够反映最常见使用场景的问题分布:
在训练后期,使用一些简单启发式规则,例如rollou的轮数和thinking token数量,对越来越困难的数据点进行上采样。
**异步RL训练:**强化学习流水线围绕大规模策略梯度学习构建,同时保持训练稳定性。每个prompt 采样多个样本,并采用固定的组大小。单epoch设置,同一个prompt不会被训练两次。使用 Adam 作为底层优化器,并更新完整参数集。强化学习训练运行在高度异步的模式下,其中训练 worker和rollout生成worker相互独立。
与Dr. GRPO类似,本文发现,尽量减少由advantage变换带来的梯度偏差非常关键。沿用该工作的方法,移除了GRPO中的长度标准化项,也不按照标准差对组内 advantage 进行归一化。
在小规模实验中没有观察到过长masking的收益,因此选择不对超过最大序列长度的 rollout进行mask。
由于智能体 rollout 可能非常长,尤其是在追求长时程连贯性时,因此系统在高度异步模式下保持稳定非常重要。主要策略是尽量减少样本变off-policy的程度。在基础设施层面,通过快速权重同步和运行中的权重更新来降低这种偏移,类似于PipelineRL。推理 worker能够在rollout中途更新权重,这意味着rollout后面的token往往更不容易 off-policy。为了进一步减少采样策略和训练策略之间的偏差,会重放MoE路由。
与先前工作类似,使用KL散度进行正则化。由于在off-policy设置下k3的方差更高,所以使用标准的KL进行正则: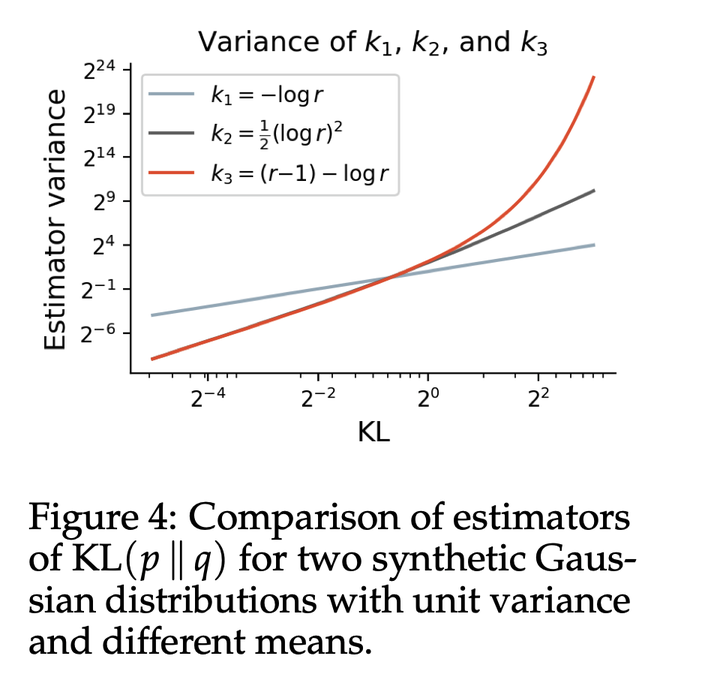
下图是在保留评估集和CursorBench任务上的结果。性能在整个强化学习训练过程中持续提升,而且没有观察到best-of-K性能下降。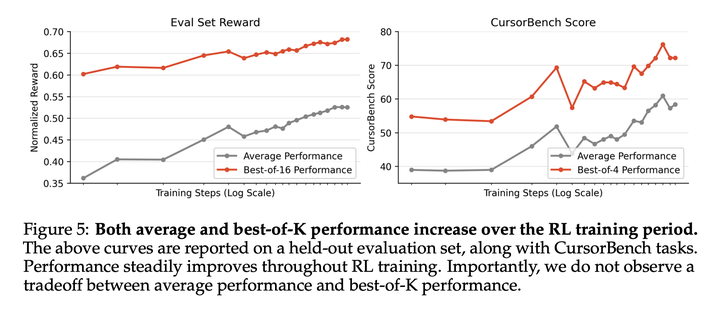
Self-Summarization:为了让Composer 2能够处理长时程任务,使用了Composer 1.5中引入的自总结技术。**每个训练 rollout可以包含多个multiple generations chained的总结,而不是单个prompt-response对。对链条中模型产生的所有token使用最终奖励。这会同时提升优秀轨迹中的agent回答,以及使这些轨迹成功的自总结内容的权重。与此同时,那些丢失关键信息的糟糕总结会被降权。**随着Composer的训练,它会学会使用自总结在有限上下文窗口内处理更多信息。对于困难样例,它通常会进行多次自总结。实验表明,与使用独立的基于prompt的压缩方法相比,自总结能够稳定降低错误,同时显著减少token 使用量,并复用KV cache。
智能体: 应用了一系列辅助reward,以确保模型能够提供给开发者良好的体验。**这些奖励包括针对编码风格、沟通方式的奖励,以及针对不良工具调用的特定惩罚,例如创建待办事项后却不完成它们。**在强化学习训练过程中,会监控模型出现的新兴行为,并在需要时偶尔引入额外的行为奖励。例如,观察到模型有时会开始在注释中留下很长的思维链,或者退化为只使用终端工具。
为了激励模型在简单请求上快速生成解决方案,同时允许它在困难请求上思考更久,在奖励中加入了一个单调递增、向下凹的非线性长度惩罚: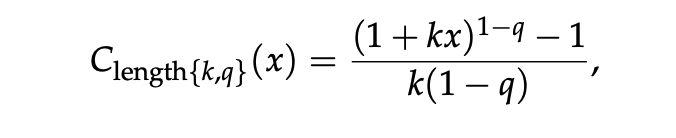
其中,k和q是定义惩罚曲率的超参数,输入x是一个加权组合,**包括thinking token、工具调用token、工具输出token、最终消息 token、工具调用次数,以及一次 rollout 的轮数。**这里的非线性反映了这样一个事实:在简单任务中,通常只需少量工具调用即可完成,因此每额外增加一点工作量都会更明显;而在长时程任务中,智能体可能会迭代数百次工具调用,因此额外工作量的边际影响相对更小。
下图示了由该公式产生的一些非线性曲线示例。发现使用这类长度惩罚能够让模型学会特别高效的行为,例如并行发起多个工具调用。****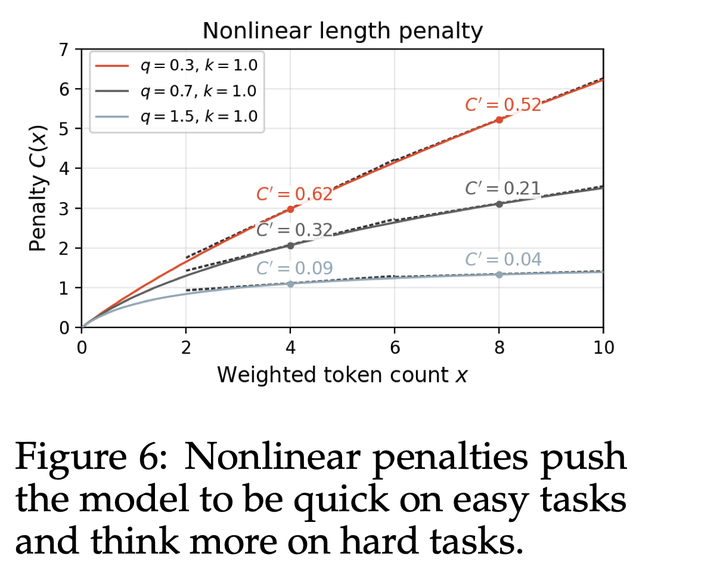
在Cursor中观察到,公开评估benchmark上的表现通常与这些模型在真实世界中的实用性关联较弱。将这种错位归因于四个主要因素:- **领域错配:**随着编码智能体能力的扩展,静态benchmark往往无法覆盖开发者工作流的完整范围。例如,SWE-bench及其变体主要关注孤立的bug fix。Terminal-Bench 覆盖了更广泛的任务类型,但其中许多任务,例如计算国际象棋走法,更像是抽象puzzle,而不是典型的软件工程操作。- **提示过度明确:**公开benchmark通常高度明确,默认存在一个较窄范围内的正确解。相比之下,真实开发者请求往往是不完全明确的,并且允许多种有效的架构方案。因此,公开benchmark要么会惩罚正确的替代解决方案,要么依赖过于显式的提示,从而绕过了解读模糊意图这一挑战。- **数据污染和过拟合:**由于公开benchmark是从开源代码仓库的历史抓取数据中构建的,经常泄漏进模型训练混合数据中,从而人为抬高分数。除了数据污染之外,这些benchmark固定且狭窄的性质也会压缩性能差异。- **评估范围狭窄:**现有编码评估主要衡量功能正确性。而在实践中,开发者还非常重视代码质量、可读性、延迟、成本,以及智能体在整个会话中的交互行为质量。
为了解决这些限制,本文提出CursorBench,这是一个内部评估,包含来自工程团队真实编码会话的任务。因为这些任务来源于真实智能体会话,而不是经过筛选整理的公开代码仓库,所以CursorBench更好地反映了软件工程任务的真实分布,同时完全避免了训练集污染。此外,不只是依赖功能正确性,而是使用专门的指标来评估代码质量、执行效率,以及真实场景中的交互式智能体行为。
下图突出了CursorBench和公开评估集之间的结构性差异。CursorBench任务需要显著更大规模的代码修改,其中代码修改行数的中位数为181行,而SWE-bench Verified 和 SWE-bench Multilingual仅为7到10行。与此同时,CursorBench的提示也更加不完整,其中问题描述长度的中位数只有390个字符,而公开benchmark为1185到3055个字符,这种评估范围更广和意图更模糊的组合,准确反映了真实世界软件工程的内在难度。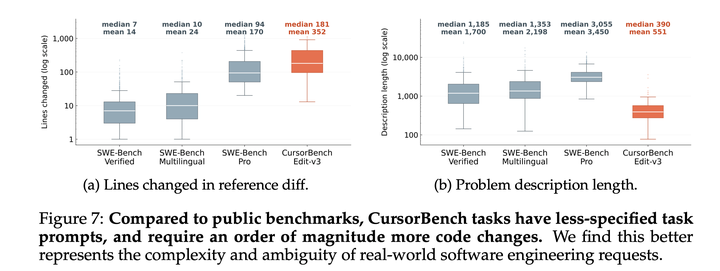
下图展示了代表性示例,开发者经常必须从生产日志、稀疏的用户bug报告,以及大型既有代码库中综合上下文,才能推导出解决方案:
新的CursorBench版本将持续开发。随着用户工作流演化、智能体能力提升,会定期更新评估集,使其始终与开发者实际使用产品的方式保持一致。
下图展示了该基准在不同迭代版本中复杂度如何增长:与早期版本的CursorBench相比,CursorBench-3 中的任务平均需要修改超过两倍数量的文件和代码行。除了问题规模增大之外,任务类型分布也发生了变化,因为开发者越来越多地将长时间运行的命令执行、实验监控和数据分析委托给智能体。这种持续刷新确保评估始终与真实世界难度的变化前沿保持一致,而不会饱和。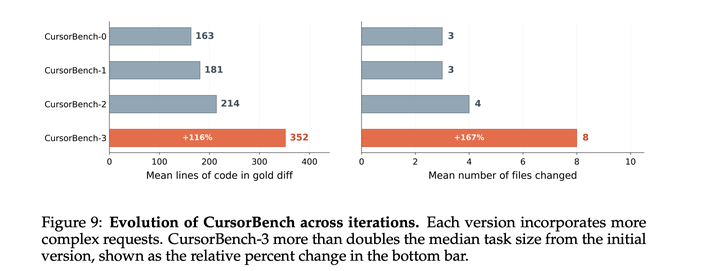
最后,还用一组有针对性的评估来补充主要的CursorBench评估,覆盖编码智能体质量和行为的其他方面。这些评估包括:**意图评估,用于评估模型如何处理模糊提示;指令遵循评估,用于衡量模型遵循系统提示、用户提示、规则和技能的能力;积极编辑评估,用于测试模型在应该避免编辑代码时如何回复问题;代码质量评估,用于判断代码和注释的质量;以及中断评估,用于量化模型如何处理中途 rollout 中断和用户反馈。**通过识别智能体行为的重要维度、选择能够激发这些行为的数据点,并编写评分标准来衡量性能,从而构建这些评估。### 训练基建
并行化: 之前的Composer训练栈结合了完全分片数据并行(FSDP),专家并行(EP)和张量并行(TP)[55]。在最初的MoE设计中,EP复用了与TP相同的rank组,因此EP并不是一个独立的扩展维度。这种耦合使实现保持简单,但限制了对更大 MoE 配置的支持,并且即使激活内存压力不大,也会在持续预训练阶段不必要地启用激活分片。
Composer 2 转而使用上下文并行(CP)作为主要的长上下文扩展维度。相比TP,CP需要更少的通信,并且通过在各种投影中保留完整 hidden dimension 来提升计算效率;相反,TP会产生效率较低的"瘦长型"本地矩阵乘法。为了在MLA架构中高效实现CP,先计算本地KV latent vectors,在CP ranks之间all-gather这些latent vectors,然后再计算KV projections。虽然这会在所有CP ranks上重复执行 projection,但projection很小,并且能够减少CP通信,可以将CP通信与Q projection的计算完全重叠。此外,朴素CP会导致负载不均衡,因为靠后的token需要attend更多 token。因此将序列划分为2×CP个chunk,第i个rank处理chunk i和2×CP−1−i,从而让所有ranks在因果注意力中的工作量大致相等。最后,上下文并行维度会折叠进FSDP维度,使能够利用CP ranks来降低每张 GPU 的参数和状态内存使用量。
Composer 2还通过将EP与TP解耦,引入了更灵活的专家并行设计。这需要使用不同的 mesh来分别分片稠密层和专家权重。EP由DP和CP的容量共同形成,从而支持更大的专家并行度,并在更大的rank token batch下让按专家分组的GEMM更高效。在持续预训练阶段使用EP=8、CP=2,在RL阶段使用EP=8、CP=8。使用DeepEP来实现高吞吐量的token dispatch/combine。DeepEP的通信buffer开销相对较低,并且DeepEP的kernel默认使用20个SM,从而为并发计算留下空间。还会在dispatch之前将token量化为 MXFP8,以提高通信效率;这不会影响精度,因为专家计算本身已经在MXFP8中执行。为了提高精度,保持combine阶段使用 BF16。为了最大化计算与通信重叠,token会被划分为 micro-batch,并在独立的通信流和计算流之间流水线执行。
最后发现,不同DP ranks具有相近的计算量对于实现高利用率至关重要。在持续预训练中,由于序列长度固定,DP 负载均衡很容易实现。而在RL中,不同prompt的不同 rollout可能产生差异非常大的序列长度,因此在每个训练 step 之前,会运行一个全局序列打包阶段,以确保DP计算负载均衡。该打包算法会考虑更长序列带来的额外注意力成本。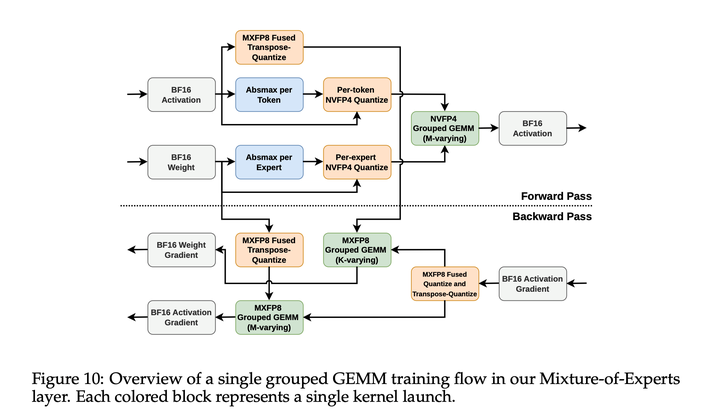
**Kernels:**Composer 2训练使用内部编写的 CUDA、PTX 以及 ThunderKittens / ParallelKittens kernel。这些 kernel主要优化MoE层的低精度训练。训练方案同时使用MXFP8和 NVFP4精度格式。专门面向 NVIDIA Blackwell GPU 进行 block-scaled tensor-core 矩阵乘法优化,也就是在systolic-array矩阵乘法过程中由硬件进行反量化。如图展示了MoE层中一次grouped GEMM 训练流程。
对于MoE前向传播,使用了一种新的 NVFP4 变体:数值从 BF16 量化为 FP4E2M1,使用 FP8E4M3的 per-block scale,block size 为 16,同时使用FP32的 per-token scale。发现原始 NVFP4 格式使用 FP32的per-tensor scale,存在两个脆弱点。第一,per-tensor scaling 会使训练batch 相关,导致数值精度塌缩,并使 RL 训练发散。第二,token间的scale值会把未来token信息泄漏到过去token中,造成有偏梯度。尽管per-token scaling 会给量化和 GEMM epilogue 增加延迟,但它最终被证明是更有效的方案。
对于MoE反向传播,使用标准MXFP8格式,即每32个元素的block使用FP8E4M3数值和 FP8E8M0 scale。这是因为RL训练中存在不对称性:在前向传播中,为了数值稳定性,trainer 必须与推理过程匹配;因此使用较窄的 NVFP4 来支持快速推理。然而,反向传播只在训练集群上运行,不是系统级RL效率的瓶颈,因此可以使用更高精度来提升训练稳定性。
最后,硬件层面的数学精度选择非常重要。对于NVFP4量化,发现使用符合IEEE标准的浮点算术至关重要;使用快速近似替代方案会导致训练在大约一百个RL step 后发散。相反,对于MXFP8量化,使用快速近似路径从Composer 1 的初始训练以来没有造成任何发散,因此为了获得最佳性能选择了它。
RL infra: RL基础设施由四个解耦服务组成:训练、环境、推理和评估。解耦的服务栈支持更大规模的全局训练、高可用性,以及独立扩展和分片。Composer 2的生产训练任务横跨3个GPU计算区域和4个CPU计算区域。
**训练:**使用基于Ray和PyTorch构建的完全异步、高吞吐训练栈。中心化的reconciler 负责基于slot的样本生命周期状态管理,通过一条由分布式executor组成的流水线移动样本,并实现调度策略,在策略新鲜度和样本生成吞吐量之间取得平衡。围绕futures的概念设计trainer内部的所有服务,使得当上游依赖就绪时,计算可以被立即执行。利用 Ray object store 保存已经准备好被训练 worker 消费的样本;当节点 CPU 内存不足时,也可以自然地溢写到本地NVMe存储。
为了支持大规模后训练,trainer内部所有组件都在进程或进程组级别具备容错能力。训练期间,在所有节点上运行被动和主动健康检查;一旦检测到硬件故障,会将该节点标记为不健康,不再调度新任务,但会继续在其上以 warm standby 模式训练。训练、推理和环境基础设施的解耦,也天然使训练对这些服务中的故障更具韧性;在训练过程中,看到过这些服务发生部分或完全宕机,但训练任务没有失败。为了尽量减少训练任务重启次数,使用响应式配置系统,并支持按进程级别进行在线代码更新;当新代码部署时,现有 actor会先清空正在处理的请求,然后被透明替换。
重放长时间运行的编码rollout代价很高。为了减轻任务级故障带来的昂贵失败,除了传统的按step保存模型权重checkpoint 之外,还在rollout级别和group级别执行策略感知checkpointing。对于rollout checkpoint,依赖代码库环境状态的内存快照,这样恢复后就可以直接进入重建出的代码库环境进行验证。对于group checkpoint,会把带有 advantage且标注策略版本的序列写入 NFS;任务重启时,调度器会在决定是分发新任务还是直接加载已就绪 group 时考虑这些信息。
**环境与Anyrun:**环境运行在Anyrun 之上,Anyrun 是一个内部计算平台,用于大规模运行不受信任的代码。这也是 Cursor 产品中 Cloud Agents 和 Automations 背后的同一个计算平台。来自trainer的所有环境创建请求都会发送到一个全局服务,该服务会将请求路由到某个底层Anyrun集群。训练负载会在多 Anyrun集群之间分片,以同时保证实例可用性和容错性。在一个集群内部,一组分布式 Anyrun managers 会调度 pod,扩展跨多个区域配置的云计算资源,并执行状态协调,以管理每个集群中数十万个 pod。每个 pod 都是一个专用的 Firecracker VM,能够运行完整开发环境,包括浏览器和用于计算机使用的 GUI。为了最大化实例可用性,会在多种机器类型和架构上运行 pod,包括 x86 和 ARM。
调度吞吐量对RL工作负载的突发性尤其重要。每个Anyrun集群都能够在维持所需要求的同时,每秒调度超过500个pod。朴素打包策略的一个挑战是,pod的稳态资源使用量可能显著低于其启动峰值,并且也可能因为 overcommit 而呈现突发性。为了解决这一点,会在更传统的调度启发式之外,监控并基于实时硬件压力读数进行调度,包括 CPU、内存和磁盘。
Anyrun支持在文件系统和内存层面对完整编码环境进行 fork 和 snapshot。这在 RL 中解锁了有用能力,例如中途 rollout checkpointing,以及rollout后状态捕获以供未来自省。当请求pod fork时,会首先尝试将fork调度到同一节点;如果由于空间限制不可行,就会将pod状态实时迁移到有容量的节点上。
环境中的出口流量会被严格控制,以限制任何外部影响。pod对互联网的任何访问都必须经过 Anygress,这是Anyrun内部的一个服务,负责代理流量、执行细粒度请求策略,并丢弃敏感 header。为了更好地复现真实世界环境,Anygress以透明方式运行,而不是依赖代理环境变量:它会在pod启动时注入可信 root CA,并在TCP层重定向pod流量。
使用的训练工具代表了Cursor客户端中的 harness。每个代码库环境启动时都会带有一个共享工具库,可以通过RPC调用。某些工具,例如语义搜索,具有外部依赖,会在环境外部处理。为了支持Cursor客户端中的完整工具集,维护了一个 Cursor 后端的 shadow deployment,用于数据集准备和rollout。以这种方式共享生产实现能够安全地扩展实验和训练,同时保持Composer 2最终部署到的harness。
有些情况下,希望训练环境和生产环境中的工具行为有所不同。具体例子包括:执行更严格的工具参数检查,以鼓励模型行为更加精确;以及移除某些工具,以提升模型可控性。为此,每个环境中可用工具集合以及每个工具期望的行为,都会被动态确定。
**推理与权重同步:**与 Fireworks AI 合作运行 RL 推理。由于 Kimi K2.5 是一个混合专家模型,数值差异可能会导致推理引擎前向传播和trainer 前向传播选择不同专家。如果 trainer和推理引擎在每个token的专家路由上不一致,那么训练期间计算得到的 log-probability可能无法匹配token采样时所来自的分布,从而给策略梯度引入噪声。为了解决这一问题,采用router replay:在推理过程中,引擎会返回每个MoE层中每个 token 所选择的专家索引;在训练前向传播过程中,router的专家分配会被覆盖为与其匹配。router仍然会计算gating score,因此梯度仍会流经它。扩展了基本的replay方案:**过滤掉那些gate score低于基于router自身 top-k 选择所得到的合理性阈值的 replay专家,并用router的候选专家替换它们;**发现这可以降低推理和训练前向传播之间p99数值不匹配。
每个训练 step,都会通过上传到共享S3 bucket的方式,将更新后的权重同步到推理引擎。为了最小化传输大小,使用 delta compression:每个rank会缓存自己上一次上传的内容,并只传输相对于新权重的 diff。由于 RL 更新很小,即使是全参数训练,对于 1T 参数模型,这些 diff 也能压缩到几个 GB。上传在所有训练 ranks 之间完全分片,因此可以充分利用训练集群的出口带宽;类似地,Fireworks 侧的下载也会在推理副本之间分片。压缩、上传和 hotload 信号都会在后台 worker 中完全流水线执行,因此训练永远不会被阻塞。在 Composer 2 训练过程中,在美国和欧洲的地理分布式集群上运行推理。每个集群都会从共享 delta chain 中独立下载并重建权重,不需要与训练集群直接连接,从而基于通用云存储实现世界规模的分布式 RL 推理。
**在线评估:**为了在训练期间对模型进行评估,会为每个评估任务运行一个固定版本的生产后端和Cursor客户端,评估期间的模型行为能够精确复现终端用户看到的行为,同时也允许使用相同基础设施迭代 Cursor harness 和模型system prompt。对于每个想要评估的训练 step,会为一个评估部署申请租约,自动将 GPU 移动到该部署中,并将对应评估 checkpoint 从它所在的训练集群跨区域同步到推理部署。### 评估
CursorBench和公开benchmark上的评估结果如下: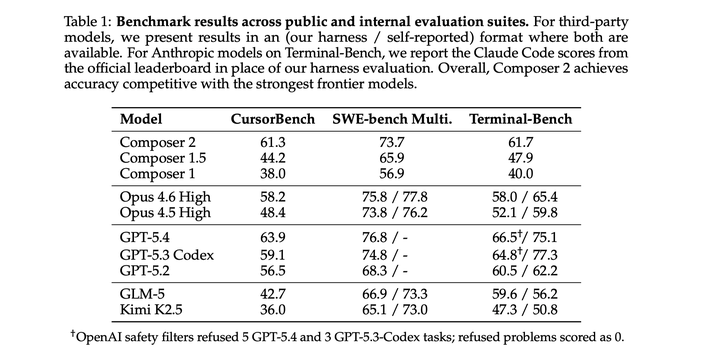
评论