
快速摘要: Skywork-OR1是基于DeepSeek-R1-Distill模型系列进行强化学习优化的推理模型,在AIME24和AIME25基准上超越了DeepSeek-R1和Qwen-32B。论文提出MAGIC(Multi-stage Adaptive entropy scheduling for GRPO In Convergence)训练方法,从数据收集、训练策略和损失函数三个方面改进GRPO算法。核心贡献包括多阶段训练、自适应entropy控制、高温采样等策略,以及深入分析了entropy崩塌现象。论文通过详尽的消融实验证明,避免过早的entropy崩塌对提升模型性能至关重要。
Skywork Open Reasoner 1 Technical Report
本文提出了Skywork-OR1,基于DeepSeek-R1-Distill模型系列,进行了显著的性能提升,在AIME24和AIME25基准测试中超过了DeepSeek-R1和Qwen-32B,同时在LiveCodeBench上取得了很好的效果。本文对训练流程的核心部分进行了全面的消融研究,以验证其有效性,此外还深入研究了熵崩塌现象,确定了影响熵变化的关键因素,并表明避免过早的熵崩塌对于提升模型性能至关重要。
Skywork-OR1在AIME 24和AIME 25上的效果如下: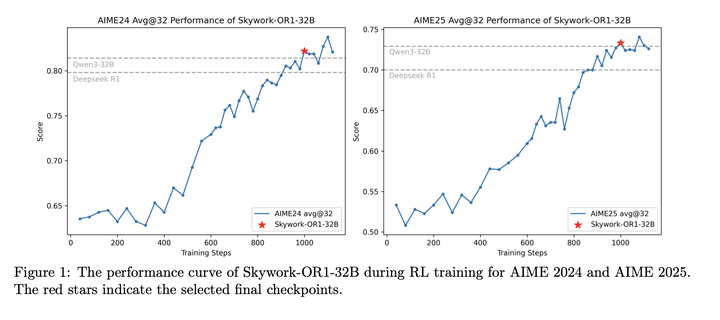
对比DeepSeek-R1和QwQ: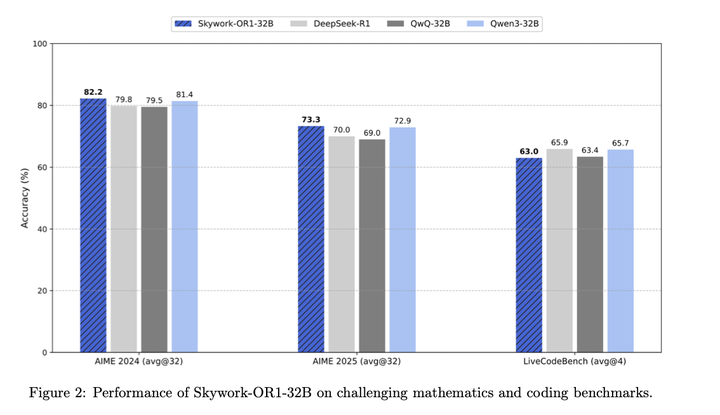
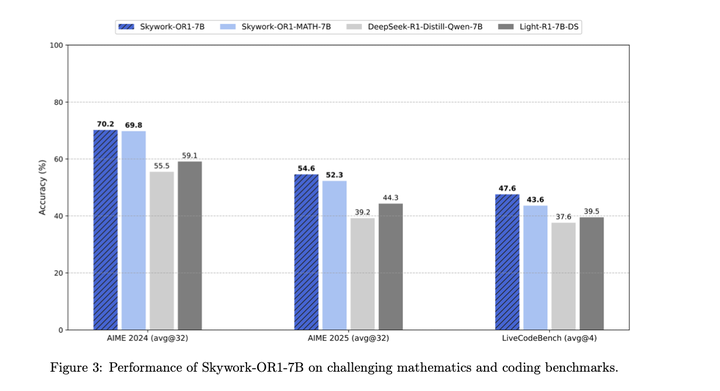
本文介绍了Skywork Open Reasoner 1(Skywork-OR1),一种针对长思维链模型的高效且可扩展的强化学习方案。本文进行了详尽的消融实验,以验证训练流程中各个部分的有效性,确定了影响熵变化的关键因素,并给出如下实验结论:
数据收集:- 为确保训练的稳定性和有效性,加入来自不同来源的数据至关重要。- 对训练数据进行严格过滤和质量控制可以加速学习过程。
训练策略:- 多阶段训练在训练初始阶段显著提高了训练效率,同时保留了训练后期的可扩展性。- 第一阶段训练时对截断轨迹进行mask,并不会在更大的上下文长度下带来更好的扩展性。- 高temperature采样在训练早期阶段会导致较低的测试准确率,但最终带来更大的性能提升。- on-policy训练会减轻熵崩塌,并带来更高的测试性能。
损失函数:- 自适应熵可以有效地保持模型的探索能力,让模型的测试性能稳步提升。- KL惩罚阻碍了多阶段训练中测试性能的进一步提升。
熵崩塌消融实验结论:- 更快的熵崩塌通常与较差的测试性能相关。适当的熵控制可以减轻过早收敛,从而改善测试结果。- 通过扩大bsz和group大小来增加rollout多样性,对熵的变化仅有微小影响,而较高的采样temperature显著影响初始熵和训练。- off-policy训练——通过增加mini-batch或数据重用来实现——会加速了崩塌,并,通常导致与on-policy更新相比测试性能下降。- entropy loss对训练数据和系数都表现出高敏感性。通过自适应调整熵损失系数或应用带有适当截断比的截断技巧,熵变化得更慢且更稳定,从而可以提高测试性能。然而,熵的收敛速度仍比on-policy训练要快。
Skywork- OR1采用了一种多阶段的自适应熵训练方式(Multi-stage Adaptive entropy scheduling for GRPO In Convergence, MAGIC),分别在从数据收集、训练策略和损失函数三个方面进行了改进。### 数据收集
离线和在线过滤:在训练前,会移除base模型正确率为1(完全正确)或0(完全错误)的prompt。在训练过程中,在每个阶段的开始,也会丢弃actor在上一个阶段达到正确率为1的训练prompt。
拒绝采样:由于GRPO算法中adv为0的数据对policy loss没有梯度,反而可能影响KL loss或entropy loss,从而导致训练过程更加不稳定,为了缓解这个问题,训练数据只包括adv非0的数据:
对GRPO进行如下改进:- 多阶段训练:逐步增加上下文长度,将训练过程分为多个阶段。多阶段训练在保持可扩展性的同时显著降低了计算成本。- 截断response的mask:实验表明,对截断response进行训练并不会阻碍效果,反而提高了token利用率效率。因此不采用任何截断数据mask策略。- 高温采样:当使用较小的采样温度时,采样策略在使用数学数据的情况下会立即进入低熵状态。因此采用temperature=1进行训练。- on-policy训练:on-policy更新会显著减缓熵的下降,并带来更高的测试性能。### 损失函数
采用如下loss:
主要改进如下:- 自适应熵控制。entropy loss对系数和训练数据都高度敏感。为了解决这个问题,引入了一个额外的超参数来表示目标熵。并根据当前熵与目标熵之间的差异动态调整entropy loss的系数。- 无KL损失。实验发现,使用kl loss会阻碍性能提升,特别是在多阶段训练的后期阶段。因此省略了KL loss。### 各模块分析
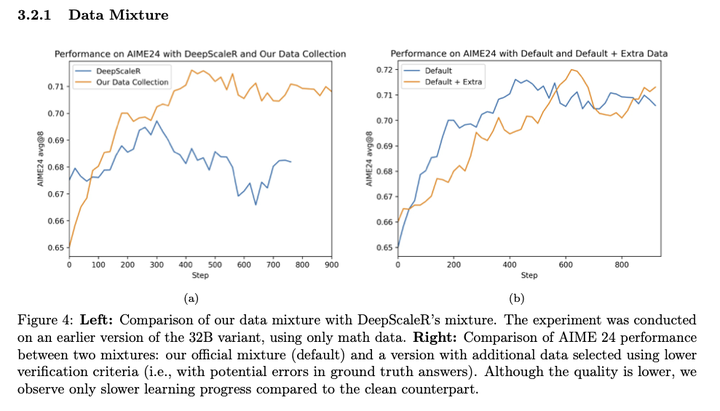
数据混合策略:混入更diversity的数据可以有效提升模型效果:
**多阶段训练:**在优化具有强化学习的长CoT思考模型时,由于输出较长,可能导致收敛缓慢和训练方差较高。因此采用多阶段训练以提高训练效率,逐渐放开最大生成长度:
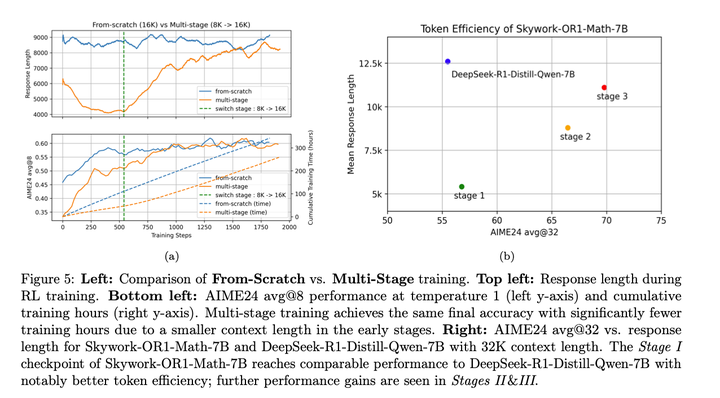
和不采用多阶段训练相比,最终性能很接近,但训练时间大幅减少。
**训练截断数据:**将截断数据加入训练不会影响效果,反而会增加样本利用率: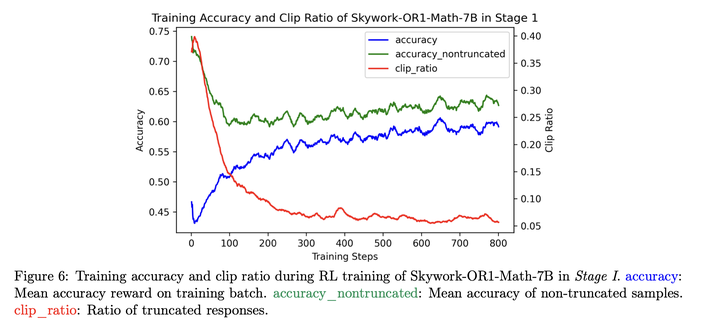
训练有截断的数据后会降低截断率,提高整体的准确率。
对比不训练截断数据的两种方式,完全过滤掉,和不更新梯度只用来计算mean/std:
训练这些数据的效果最好: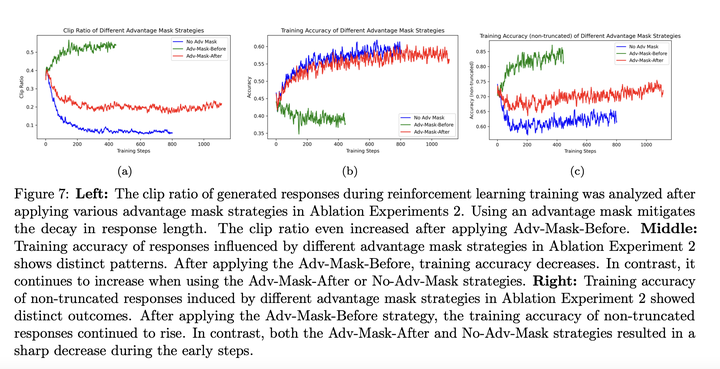
放开到32k长度推理的效果对比: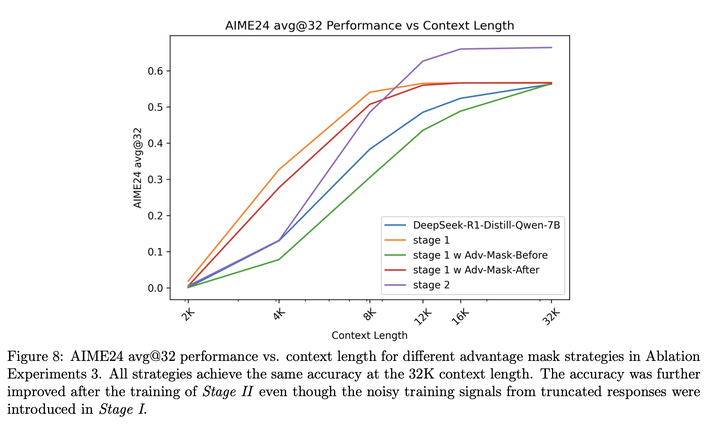
**高温采样:**高温采样的起始值会更低,但最终结果会更高:
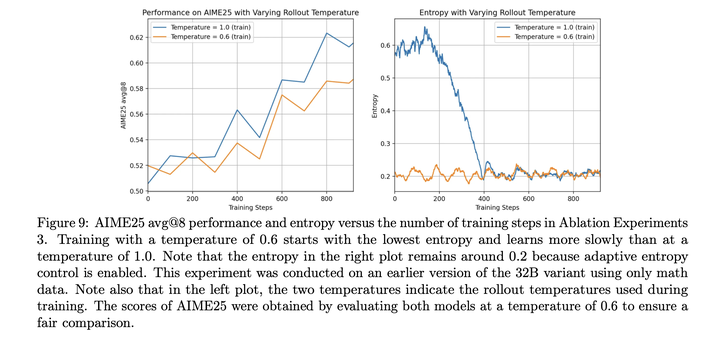
**自适应熵控制:**采用如下方式进行自适应熵控制:
自适应熵控制的效果: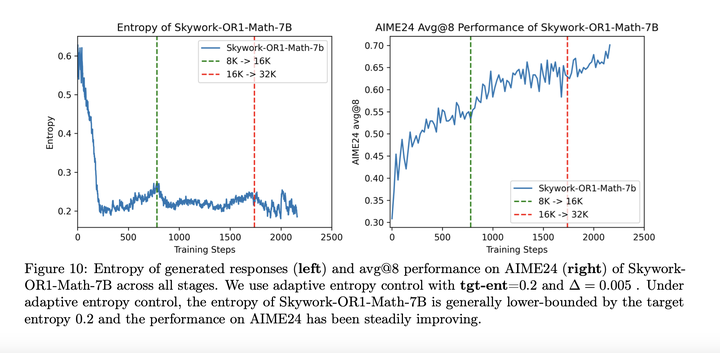
无kl **loss:**多阶段训练,不加入kl loss的效果会更好:
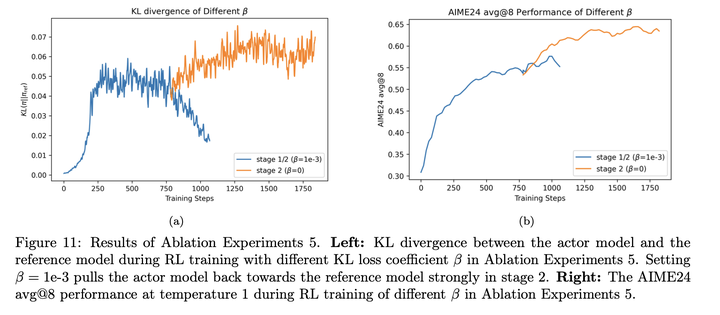
**entropy崩塌的影响:**entropy崩塌通常会对应模型能力变差: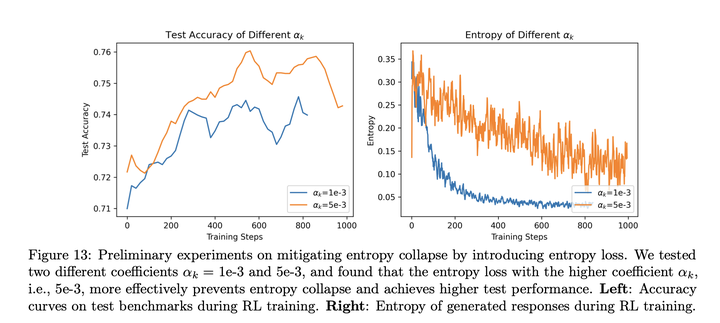
rollout **bsz和entropy的关系:**不同的rollout bsz和group size没有显著影响entropy的变化: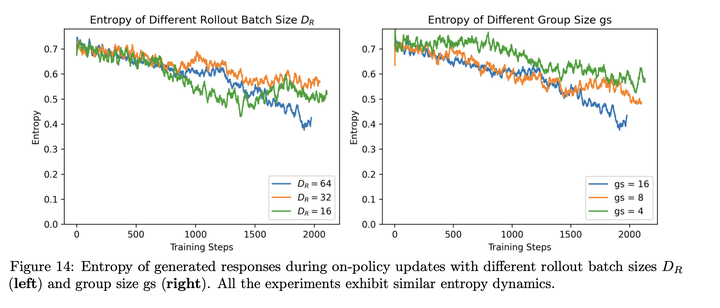
**on-policy和entropy的关系:**on-policy训练会减缓entropy崩塌: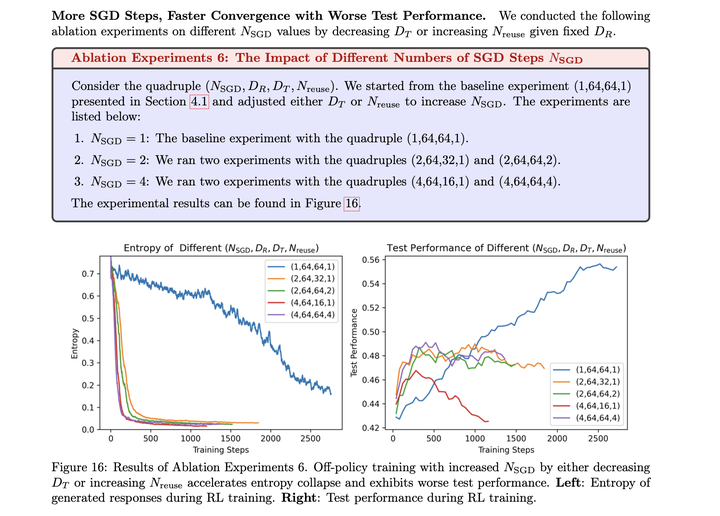
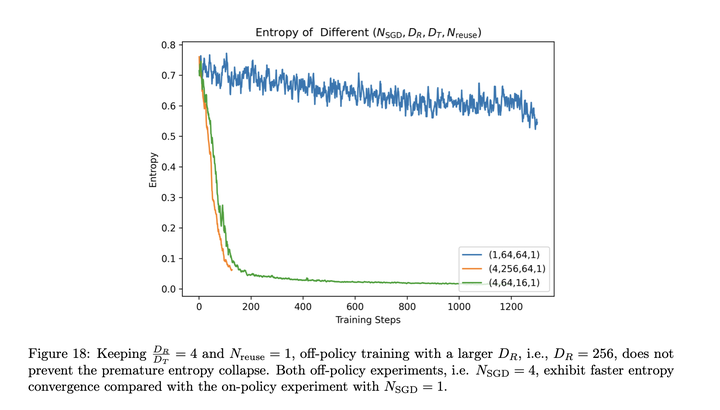
off-policy的数据会影响性能: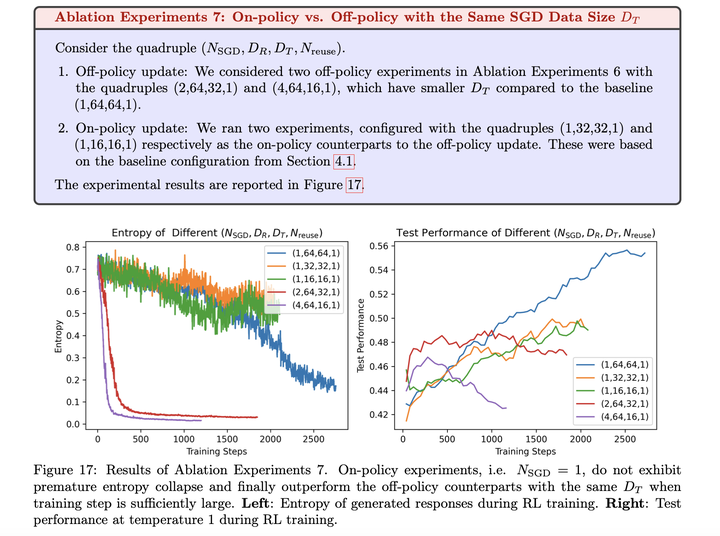
entropy **loss对entropy的影响:**entropy loss对系数和数据比较敏感,合适的entropy loss系数可以提高最终表现: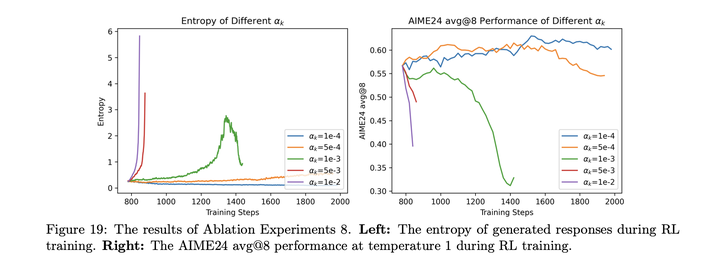
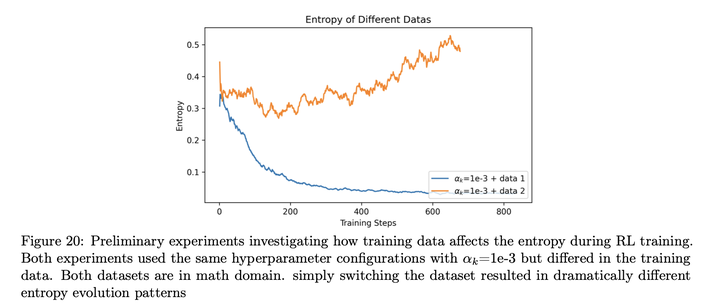
**自适应entropy系数:**可以减缓entropy崩塌,提升最终效果: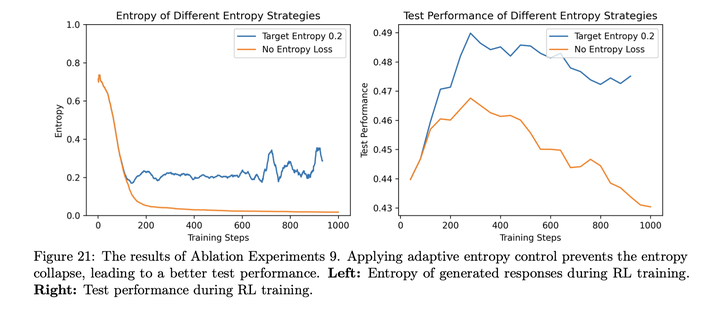
clip **high:**合适的clip high可以减缓entropy崩塌,过高的clip high会使训练崩溃: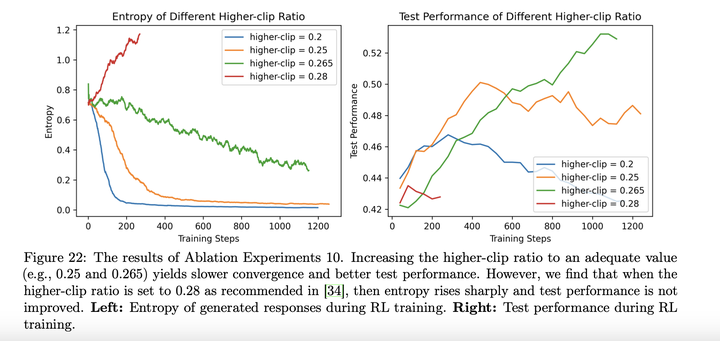
收集开源的数学和代码数据,进行预处理,对于所有收集的数学问题:- 使用Math-Verify从提供的文本解决方案中重新提取答案,并仅保留提取的答案与数据集中的相应答案匹配的问题。- 删除所有包含外部URL或问题陈述中有潜在数字的实例。- 执行跨数据集去重,以消除来自相似来源的潜在重复问题,并根据AIME24和AIME25问题进行去污染,遵循DeepScaleR的去重方案。
对于代码问题:- 丢弃原始单元测试用例为空、不完整或损坏的样本。- 使用提供的原始解决方案验证所有测试用例。只有当解决方案完美通过所有相应测试用例时,样本才被标记为有效。- 根据收集的编码问题之间的嵌入相似性进行去重。
再排除掉所有全做对,全做错的数据: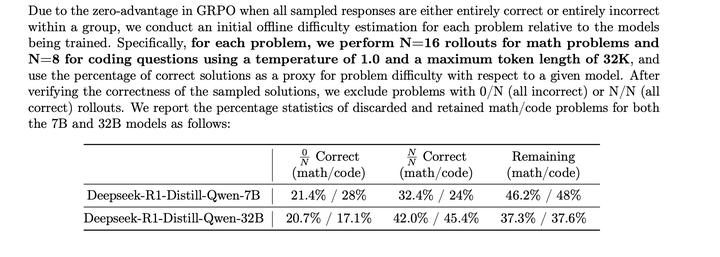
Skywork-OR1采用如下的多阶段训练设置: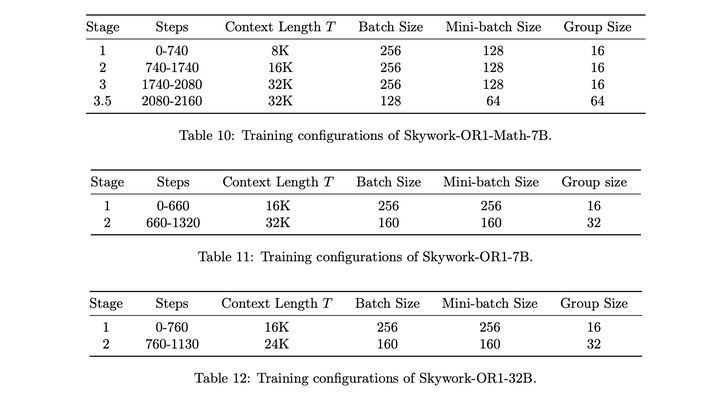
最终表现如下: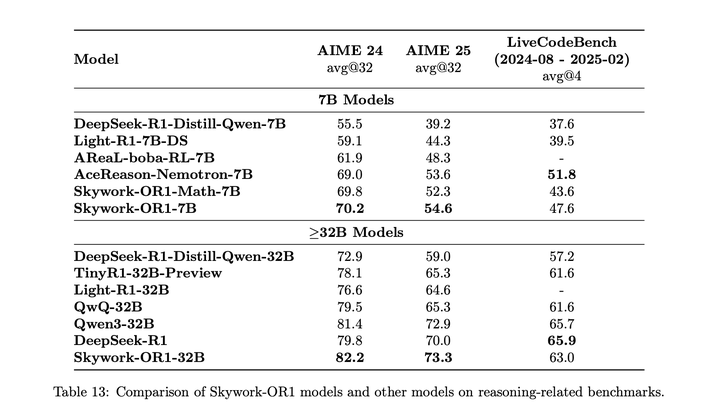
评论