
快速摘要: MiMo-7B是小米推出的推理模型,通过三阶段预训练数据混合策略和强化学习后训练实现了卓越的推理能力。预训练阶段采用25T token,结合MTP(多token预测)提升性能与推理速度;后训练阶段使用13万可验证的数学和编程问题进行强化学习,并创新性地引入test-difficulty-driven代码奖励机制缓解奖励稀疏问题。MiMo-7B-Base在推理能力上已超越32B等更大规模模型,最终模型MiMo-7B-RL在数学、代码和通用推理任务上超越了OpenAI o1-mini。此外,本文还开发了Seamless Rollout Engine,实现了异步奖励计算和动态数据填充,显著提升了RL训练效率。
MiMo: Unlocking the Reasoning Potential of Language Model–From Pretraining to Posttraining
本文介绍了推理模型MiMo-7B。在预训练期间,MiMo采用了三阶段数据混合策略,以增强基础模型的推理能力。MiMo-7B-Base在25T个token上进行了预训练,并采用了MTP来提高性能并加速推理速度。在后训练期间,MiMo使用一个包含13万个可验证的数学和编程问题的数据集,用于强化学习,并整合了test-difficulty–driven 代码奖励机制,以缓解奖励稀疏问题,并采用数据重采样来稳定训练。评估表明,MiMo-7B-Base具有出色的推理能力,甚至超越了规模大得多的32B模型。经过强化学习微调的最终模型MiMo-7B-RL在数学、代码和通用推理任务上表现优异,超越了OpenAI的o1-mini的性能。
MiMo 在LCB和AIME上的效果如下: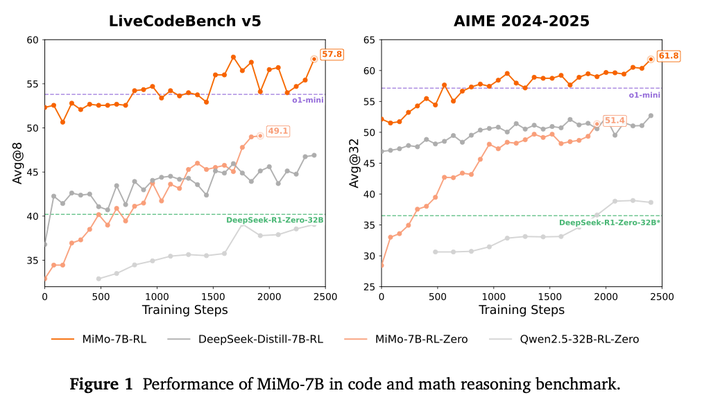
本文主要分为预训练,后训练,RL训练框架三个部分介绍MiMo的训练。### 预训练
**预训练数据:**MiMo-7B的预训练语料库整合了多种来源的数据,包括网页、学术论文、书籍、编程代码和合成数据。本文认为,在预训练阶段纳入更多具有高质量推理模式的数据,可以提升所得语言模型的推理潜力。因此,MiMo优化了自然文本预处理流程,**提高数据质量,提高推理数据密度,并利用先进的推理模型合成了大量的推理数据。**然后,MiMo实施了三阶段数据混合策略,以最大化模型在各种任务和领域中的推理潜力。
更好的推理数据提取:很多网页包含具有高密度推理模式的内容,例如编码教程和数学博客。常用的提取器往往无法保留网页中嵌入的数学方程式和代码片段。为了解决这一局限性,本文开发了一种专门针对数学、代码块和论坛网站进行优化的新型HTML提取工具。对于论文和书籍,本文增强了PDF解析工具,以更好地处理STEM和代码内容。借助这些优化后的提取工具,成功保留了大量推理模式的数据,以供后续处理阶段使用。
快速全局去重:数据去重在提高训练效率和减少过拟合方面起着重要作用。本文在所有网页转储中采用URL去重和MinHash去重。
**多维数据过滤:**富含推理模式的高质量预训练数据对于开发具有强大推理能力的模型至关重要。常用的基于启发式规则的过滤器会错误地过滤掉包含大量数学和代码内容的高质量网页。为了解决这一限制,本文微调小型的LLM,使其充当数据质量标记器,进行领域分类和多维质量评估。
**合成推理数据:**推理模式数据的另一个关键来源是由先进推理模型生成的合成数据。本文采用多种策略来生成多样化的合成推理response。首先,选择标注有高推理深度的STEM内容,并提示模型基于原始内容进行深入的分析思考。其次,收集数学和代码问题,并提示推理模型解决这些问题。此外还融入了一般领域query,特别是创意写作任务。值得注意的是,本文的初步实验表明,与非推理数据不同,合成推理数据可以在极多的训练轮次下进行训练,而不会出现过拟合风险。
**三阶段训练:**MiMo的预训练分为3个阶段:- 第一阶段:使用除合成推理数据之外的所有数据源。对过度的数据(如广告、新闻、职位发布以及知识密度和推理深度不足的材料)进行降采样。同时,对来自专业领域的高质量数据进行上采样。- 第二阶段:在第一阶段的基础上,将数学和代码相关数据大幅增加至混合数据的约70%。这种方法有望在不损害通用语言能力的情况下增强专业技能。前两个阶段使用8192个token的上下文长度进行训练。- 第三阶段:为了提升解决复杂任务的能力,进一步纳入了约10%的数学、代码和创意写作query的合成response。同时,在最终阶段将上下文长度从8192扩展至32768。
最终,构建出一个由约25T个token组成的高质量预训练数据集。
模型结构:MiMo使用GQA,pre-RMSNorm,SwiGLU激活,RoPE位置编码。使用MTP的结构,推理时投机解码来加快推理速度。模型结构图如下: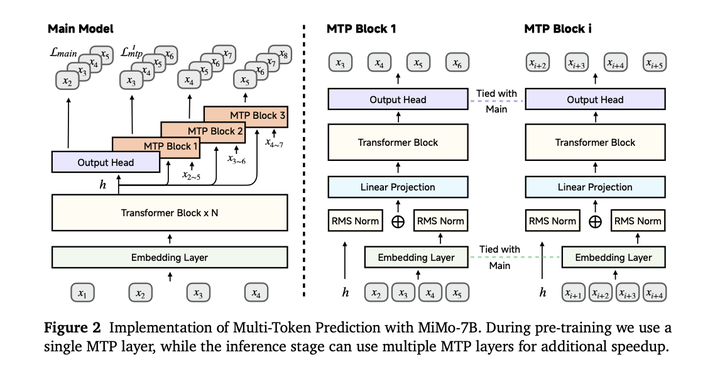
在预训练期间仅使用单个MTP层。在预训练之后,将预训练的单个MTP层复制出两个相同的副本,然后,在冻结主模型和第一个MTP层的情况下,对两个新的MTP层进行微调以提升推理速度。结合投机解码策略,MTP可以显著提升推理速度。
**预训练超参数:**预训练模型超参数设置如下:
**预训练评估:**pass@k曲线图对比如下,随着k的增加,MiMo-7B-Base与其他基础模型之间的性能差距逐渐扩大,说明MiMo模型拥有更大的训练潜力。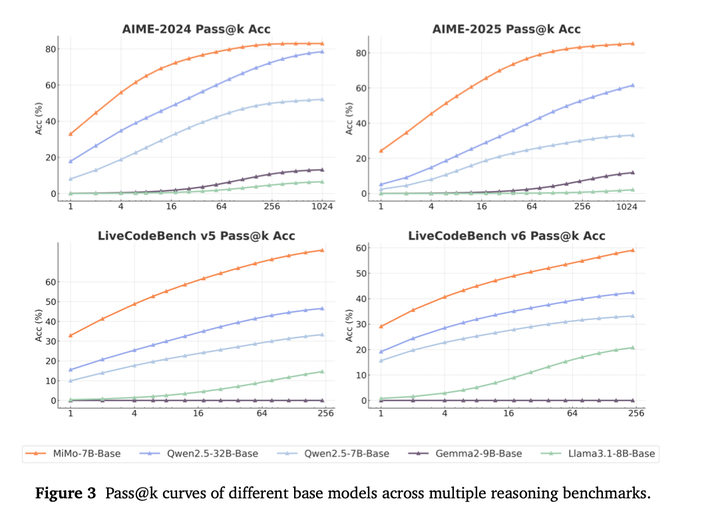
对比其他小模型的评估结果: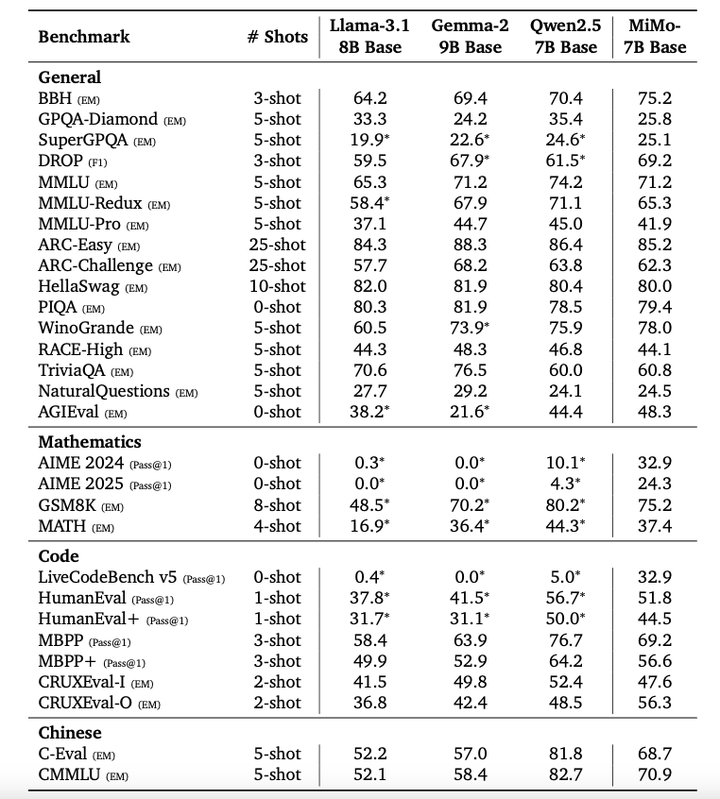
长文的评估结果: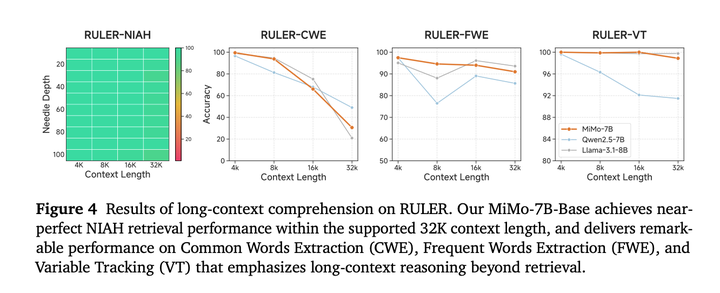
**SFT训练:**SFT数据由开源数据和蒸馏数据构成。首先,排除所有与评估基准有16-gram重叠的训练query,以防止数据泄露。然后,排除语言混合以及response不完整的样本。最后,将每个query的response数量限制为8个,在保持多样性和防止冗余之间取得平衡。最终的SFT数据集包含约50万个样本。SFT使用3×10⁻⁵的恒定学习率对MiMo-7B-Base模型进行微调。在训练期间,样本被填充至最长32768个token。
**强化学习数据:**利用两类可验证的问题,数学和代码问题,来构建强化学习训练数据。
数学数据:数学问题集来源包括开源数据集和收集的竞赛级题目。为了降低reward hacking的风险,使用大语言模型来筛选基于证明和选择题的问题。与最近通过修改问题以确保整数答案来防止奖励作弊的方法不同,本文保留原始问题以尽量减少reward hacking。此外,会进行全局n-gram去重,并使用评估基准仔细清理我们的问题集。
本文会筛选掉高级推理模型无法解决的问题,识别出那些太难或包含不正确答案的问题。对于剩余的问题,对MiMo-7B SFT模型rollout 16次,剔除通过率超过90%的问题。这一过程从原始问题集中移除了约50%的简单问题。数据清理后,建立了一个包含10万个问题的数学训练集。
代码数据:对于代码问题,策划了一个高质量的训练集,包括开源数据集和新收集的问题集。会移除没有测试用例的问题。对于有标准答案的问题,排除那些标准答案未能通过所有测试用例的问题。对于没有标准答案的问题,丢弃在16次高级推理模型运行中无法解决任何测试用例的问题。与数学数据类似,使用MiMo-7B的SFT版本来筛选掉在所有16次运行中都能完美解决的简单问题。最后保留有3万个代码问题。
**奖励函数:**在训练过程中仅使用基于规则的准确性奖励。对于数学数据,我们使用基于规则的Math-Verify库来评估response的正确性。
**RL算法:**使用GRPO算法训练。
另外,还加入了移除kl约束,加入动态采样,clip high等常见的Reasoning RL的策略。
基于测试用例难度的奖励机制: 现有的做法是只有当生成的代码通过了某一问题的所有测试用例,才会被给予奖励。然而,对于难度较高的算法问题,模型可能永远无法获得奖励,从而阻碍其从这些挑战性样本中学习,并降低动态采样过程中的训练效率。
为了解决上述限制,本文提出了一种新的奖励机制:测试用例难度驱动的奖励**。对于困难问题,模型即使未能完全解决,也能通过完成部分子任务获得部分奖励,从而能在训练中更好地利用这些难问题。本文将测试用例根据其通过率进行分组**,使用多个模型对每个问题进行多次rollout,并统计每个测试用例的整体通过率。随后,将测试用例根据通过率分类为多个不同的难度等级,通过率越低则难度越高。
在将测试用例划分为不同难度等级后,本文设计了两种奖励机制:- 严格奖励:模型必须通过某一难度组的所有测试用例,并且也要通过所有更低难度组中的测试用例,才能获得该难度组对应的奖励。- 宽松奖励:每一组测试的总分平均分配给该组内的所有测试用例。只要通过其中任意测试,就能获得相应分数。
下图对比了不同reward设计的效果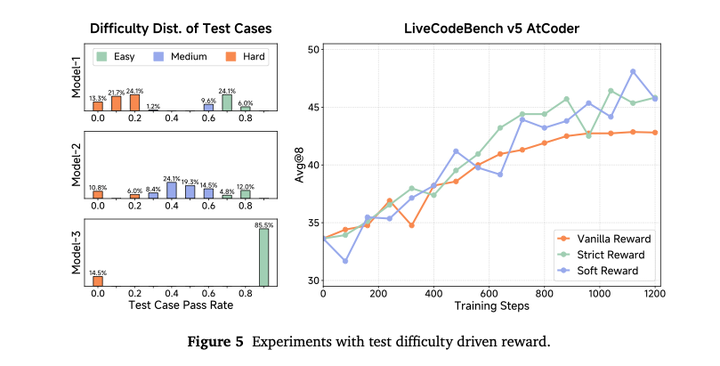
RL超参数: 采用了512的bsz,以及32的mini-bsz。在每个训练迭代中执行16次梯度更新,学习率设为1e-6。最大序列长度设为32768个token,温度和top-p参数均配置为1.0,以促进输出多样性。### RL训练框架
本文开发了Seamless Rollout Engine,能够执行异步的reward计算,并且动态填充数据rollout**。**
持续rollout:Seamless Rollout Engine会主动处理已完成的rollout任务并及时启动新的任务。它会实时监测已完成任务的worker,立即计算其奖励,并根据需求触发新的 rollout。计算奖励后,会更新有效样本数量与当前步骤的通过率统计,并根据这些统计信息,如果当前活跃任务无法满足训练需求,则会启动新的rollout任务。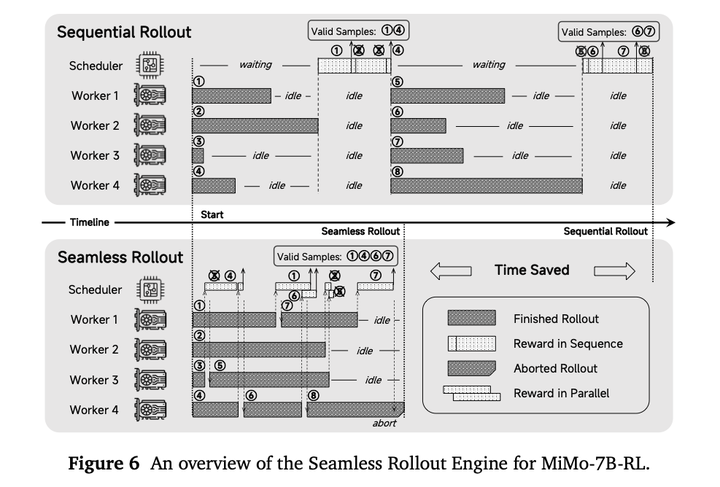
异步奖励计算:虽然对数学数据进行奖励计算很快,但判断与代码相关的数据会带来显著的开销,导致GPU空闲时间延长。此外,传统的奖励计算按顺序进行,未能充分利用现代处理器的多进程能力。为了解决这些问题,采用Ray启动异步奖励计算,从而并发地管理 rollout和奖励任务。任务完成后,系统会动态地将rollout输出转发以进行奖励评估,以防止rollout流水线中的瓶颈。
提前终止:当有效样本的数量超过所需的训练batch大小时,必须对正在进行的任务进行管理。突然终止正在进行的任务往往会抑制长序列响应的生成,这可能会扰乱RL训练动态。一个简单的解决方案是等待所有任务完成后,再从输出中随机采样所需批次。然而,如果长序列的rollout恰好在动态采样阶段末尾启动,这种方法可能会延长等待时间。为了解决这一延迟并保持数据分布的完整性,采用先进先出的选择策略。只有当有效样本数量满足batch要求,且这些样本之前启动的任务全部完成时,才终止正在进行的任务。
Seamless Rollout Engine与naive实现的性能对比如下**: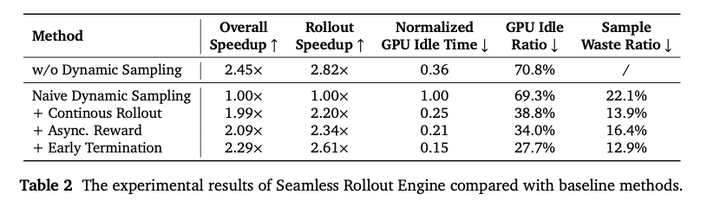

此外,MiMo还在vLLM中加入了MTP来提高RL中的采样速度。
后训练评估:后训练的评估结果如下: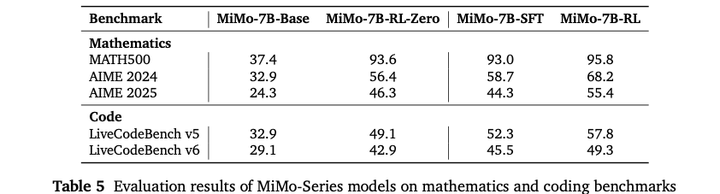
另外,本文还给出了一些实验结论。
**SFT格式对齐:**在MiMo-7B-Base的最初RL训练阶段,观察到模型主要学习如何适应答案抽取函数,例如对于数学问题的"boxed{}"格式。因此,本文试图采用一种轻量级的 SFT,帮助基座模型对齐预期的答案格式。MiMo-7B-RL-LiteSFT 在推理能力和最终性能上都表现不佳。虽然 MiMo-7B-RL-LiteSFT 的起始性能高于 MiMo-7B-RL-Zero,但在训练 500步后,其表现落后于基座模型。此外,与采用重SFT的 MiMo-7B-RL 相比,MiMo-7B-RL-LiteSFT 增长趋势相似但由于初始点较低,最终结果更差。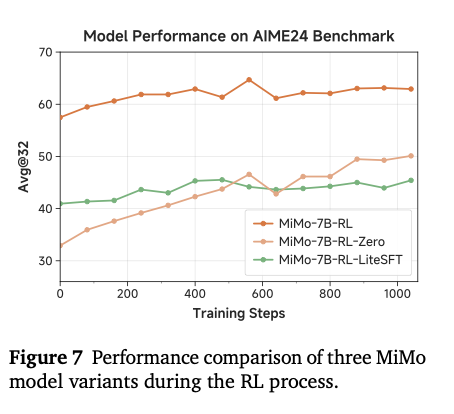
**不同领域间的相互干扰:**在MiMo-7B-Base的后期RL训练过程中,在训练步数2000到 2500之间,模型在代码问题上表现出持续提升,但在数学推理任务上的表现则波动且下降。相比之下,冷启动SFT模型的RL训练在两个领域都表现为持续提升。输出分析表明,基座模型凭借其强大的探索能力,往往会在数学问题中过度探索,导致reward hacking。而代码问题则因为测试集验证更严格,使得reward hacking难度加大。这强调了高质量数学问题测试集对于稳健RL训练的重要性。
**语言混用惩罚:**与DeepSeek-7B-RL-Zero 类似,本文也观察到 MiMo-7B-Base的RL训练中存在语言混用问题。为此,本文试图引入语言混用惩罚机制来抑制这种行为,但实际设计中发现,惩罚函数的构建充满挑战。检测英文回答中的中文字符较为容易,但反过来则更难,因为许多专业术语本身就源自英文。因此,该惩罚机制虽然能减少语言混用,也带来了reward hacking的新风险,例如通过全英文输出绕过惩罚,导致模型对问题语言的泛化能力下降。
评论