
快速摘要: DeepSeek-V3的技术报告重点关注其后训练(Post-Training)部分。SFT阶段构建了150万条指令微调数据集,其中推理数据通过训练融合了DeepSeek-R1和普通模型的领域专家模型生成,确保数据兼具R1的高准确性和普通模型的简洁性。强化学习阶段采用GRPO算法,结合Rule-Based RM和Model-Based RM两种奖励模型,其中Model-Based RM在偏好数据中引入了chain-of-thought以减少reward hacking。评估结果显示,DeepSeek-V3在多项基准上与Claude-Sonnet-3.5、GPT-4o等模型表现相当。此外,文章还讨论了R1蒸馏数据的消融实验和Self-Rewarding机制。
DeepSeek-V3 Technical Report
DeepSeek-V3的技术报告主要分为Architecture,Infrastructures,Pre-Training,Post-Training等几个部分,本文重点关注Post-Training的部分。### Supervised Fine-Tuning
在SFT流程中,会构建一个包含150万条实例的指令微调数据集,涵盖多个领域,每个领域采用针对其特定需求量身定制的数据创建方法。
推理数据:对于与推理相关的数据集(包括数学、代码和逻辑问题等),会通过DeepSeek-R1模型生成数据。尽管R1生成的数据很准确,但也存在过度思考、格式差以及内容过长的问题,这就需要平衡R1生成的高准确性推理数据与常规推理数据的清晰性和简洁性。
因此,**DeepSeek首先训练了一个针对特定领域(如代码、数学、推理)的专家模型,该模型融合了R1模型和普通模型,之后再用专家模型去生成SFT数据。**专家模型采用了结合SFT和RL的训练方式,SFT的训练过程中,会为每条数据生成两种不同类型的SFT样本:第一种将问题与其原始response配对,格式为<problem, original response>;第二种结合system prompt,将问题与R1 response配对,格式为<system prompt, problem, R1 response>。
System prompt经过精心设计,包含引导模型生成具有反思和验证机制的response的指令。在RL阶段,模型利用高temperature采样,去生成能够结合R1数据和原始数据的response模式(即使在没有system prompt提示的情况下也能完成)。在经历数百个RL步骤后RL模型学会了R1的推理模式,从而能够提升整体性能。
完成RL训练阶段后,会用专家模型,用reject sampling策略来生成高质量的SFT数据,供最终模型使用。这种方法确保了最终训练数据保留DeepSeek-R1的优势,同时生成简洁而有效的回复。
非推理数据:对于非推理类数据,如创意写作、角色扮演和简单问答,会使用 DeepSeek-V2.5生成回复,并邀请人工标注员验证数据的准确性。
**SFT设置:**使用SFT 数据集对 DeepSeek-V3-Base 进行微调训练,共训练两个epoch。采用cosine decay衰减学习率,初始学习率为5×10−6逐渐衰减到1×10−6。在训练过程中,每个序列由多个样本拼接而成。然而,我们采用了一种sample masking策略,以确保这些样本彼此不可见。### Reinforcement Learning
Reward **Model:**采用了Rule-Based RM和Model-Based RM两种奖励模型。
Rule-Based RM:对于可以使用特定规则验证的问题,采用基于规则的奖励系统来提供反馈。例如,对于某些数学问题,会要求模型以指定格式(如用框括起来)提供最终答案,从而可以应用规则验证正确性。同样,对于LeetCode问题,可以利用编译器通过测试用例生成反馈。
Model-Based RM:对于答案标准更自由的问题,会用奖励模型来判断response是否匹配预期的标准答案。该奖励模型从 DeepSeek-V3 SFT 模型开始训练。会构建偏好数据,其中不仅包括最终reward,还包括生成reward的chain-of-thought,从而减少reward hacking。
**GRPO:**和DeepSeek V2一样,用GRPO算法进行训练:
GRPO没有value model,用多次采样的方式算baseline,减少方差。### 评估
对比DeepSeek-V2-0506、DeepSeek-V2.5-0905、Qwen2.5 72B Instruct、LLaMA-3.1 405B Instruct、Claude-Sonnet-3.5-1022 和 GPT-4o-0513。
评估结果: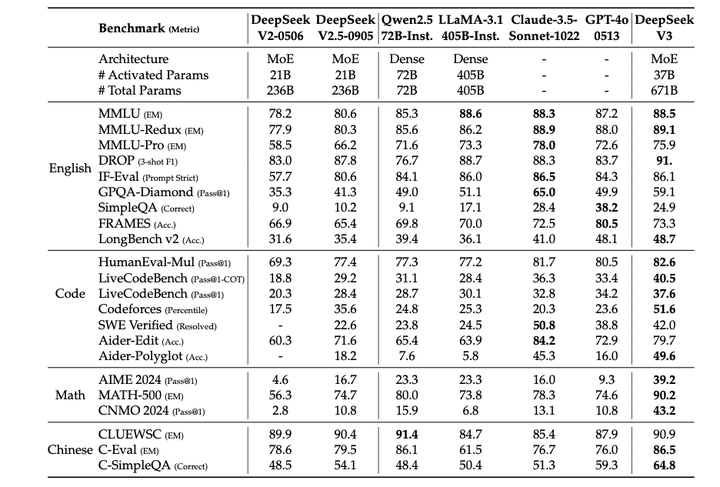
Open-Ended的评估: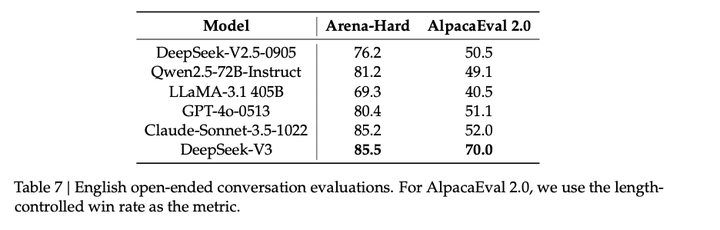
作为奖励模型的效果: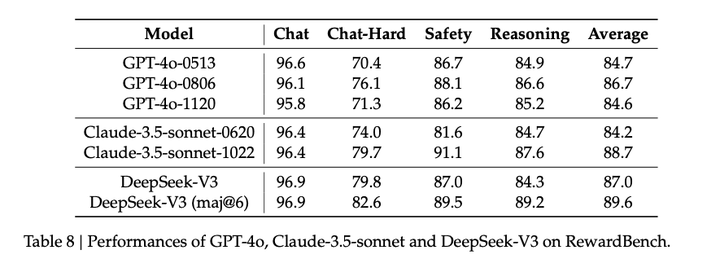
R1蒸馏数据的消融实验: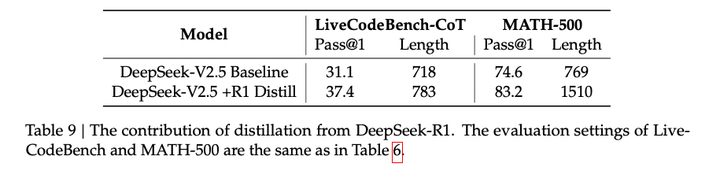
蒸馏R1数据虽然有效果,但是会使模型回复变长,因此需要精心设计。
Self-Rewarding:对于没有准确答案的领域,使用了constitutional AI approach的方式,利用the voting evaluation results of DeepSeek-V3 itself 作为feedback。
评论