场景题:编程助手
RAG-Agent:基于LangGraph的多智能体RAG
1. 项目概述
1.1 项目目标
本项目旨在构建一个名为“RAG-Agent”的先进智能系统,该系统深度融合检索增强生成(RAG)技术与基于LangGraph的多智能体(Multi-Agent)协作框架。其核心目标是克服传统RAG系统在处理复杂查询、保证信息准确性、上下文理解、结构化数据处理(尤其是代码)以及应对多样化数据源方面的局限性,为用户(特别是软件开发者)提供更精准、全面、可靠且高效的信息获取与智能辅助能力。
1.2 问题背景
传统RAG系统常面临内容缺失、忽略低排名相关文档、上下文漂移、无法有效提取答案、格式错误、回答具体性不当、不完整、数据摄取扩展性差、难以处理复杂结构化数据(如代码、PDF表格)以及潜在的安全风险等12个核心挑战。同时,单一模型难以覆盖所有专业领域和任务类型。
1.3 核心方法
本项目采用多智能体协作架构,通过LangGraph进行任务编排和状态管理。系统将复杂任务分解给具有特定专长的智能体(如代码检索、文档问答、代码分析、验证等),协同完成信息检索、分析、整合与生成。同时,采用先进的RAG技术栈,优化数据处理、嵌入、索引和检索流程,并建立持续的数据接入与更新机制,确保知识库的时效性和准确性。
2. 系统架构

本系统采用分层架构,主要包括:
• 数据接入与管理层 (Data Ingestion & Management Layer):负责从异构数据源(代码库、文档系统、API等)持续、增量地接入数据。包括变更监控、增量预处理(清洗、解析、智能分块)、元数据提取与管理、版本控制和质量保障机制。
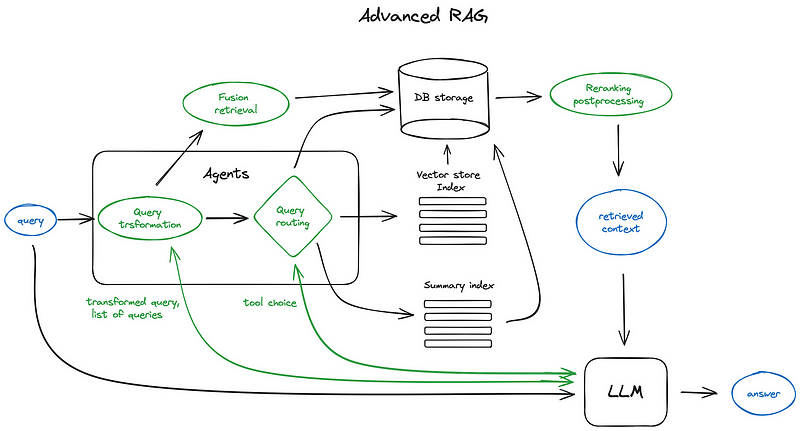
• RAG核心层 (RAG Core Layer):实现高效的检索增强能力。包括:
• 双嵌入引擎: 分别针对代码(如CodeBERT)和文本(如BGE)优化。
• 多级向量索引: 使用Qdrant等支持元数据过滤和混合搜索的向量数据库,构建代码和文档的独立、多粒度索引。
• 高级检索引擎: 实现混合检索(向量+关键词)、多路查询转换(HyDE、多查询、历史重写等)和重排序(Cross-Encoder)。
• LangGraph多智能体协作框架 (LangGraph Multi-Agent Framework):系统的“大脑”,负责协调智能体工作。
• 任务调度与协同Agent (Coordinator): 解析用户意图,分解任务,编排工作流,管理状态,整合结果。
• 专业智能体池: 包括代码检索Agent、文档问答Agent、代码分析Agent、开发辅助Agent、信息整合Agent、验证Agent、生成Agent等。各Agent具备特定工具和知识,处理专门子任务。
• Agent知识库: 存储领域知识、协作模式、反馈学习结果。
• 用户交互层 (User Interaction Layer):提供API接口和用户界面,接收用户查询,展示结果,并收集反馈。
• 持久化与监控层 (Persistence & Monitoring Layer):包括向量数据库、元数据存储、版本快照、以及系统运行状态和检索效果的监控。
3. 核心功能模块
智能代码与文档检索:支持自然语言查询代码库和技术文档,理解代码语义和文档结构,提供精准、上下文相关的检索结果。
深度代码理解与分析:解析代码结构(AST),分析函数逻辑、依赖关系、代码质量,提供代码解释和可视化辅助。
复杂文档问答:处理多种格式文档(包括复杂PDF),理解表格、图表,进行跨文档信息整合与问答。
智能代码生成与辅助:根据需求描述、上下文和代码库风格生成代码片段、函数或框架,提供代码优化、重构建议。
错误诊断与修复:分析错误信息和上下文,推断错误根因,提供修复建议甚至自动生成修复代码。
技术决策支持:基于知识库提供技术选型对比、架构设计建议、最佳实践推荐。
上下文感知与个性化:利用对话历史和用户反馈,提供更连贯、个性化的交互体验和学习路径。
结果验证与可靠性增强:通过验证Agent进行事实核查、信息一致性检验,减少幻觉,提升答案可靠性。
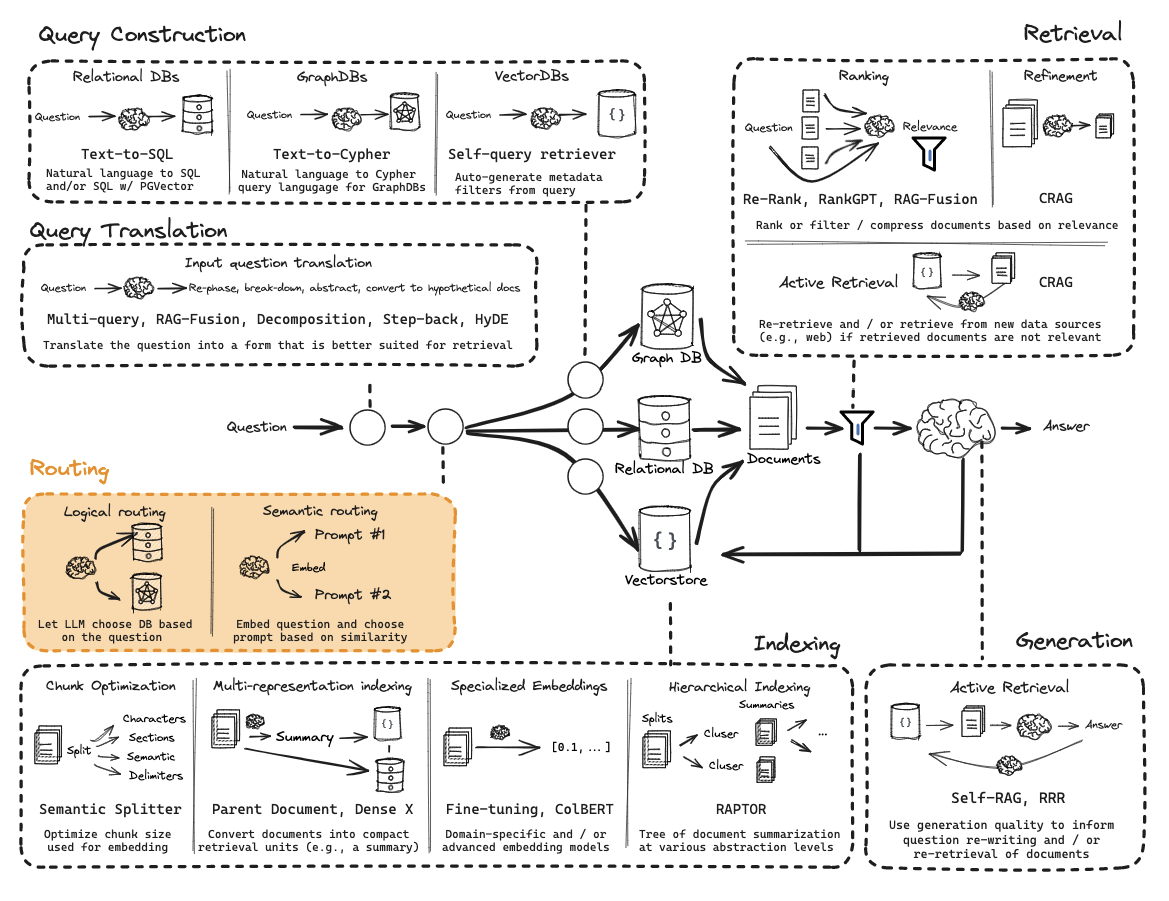
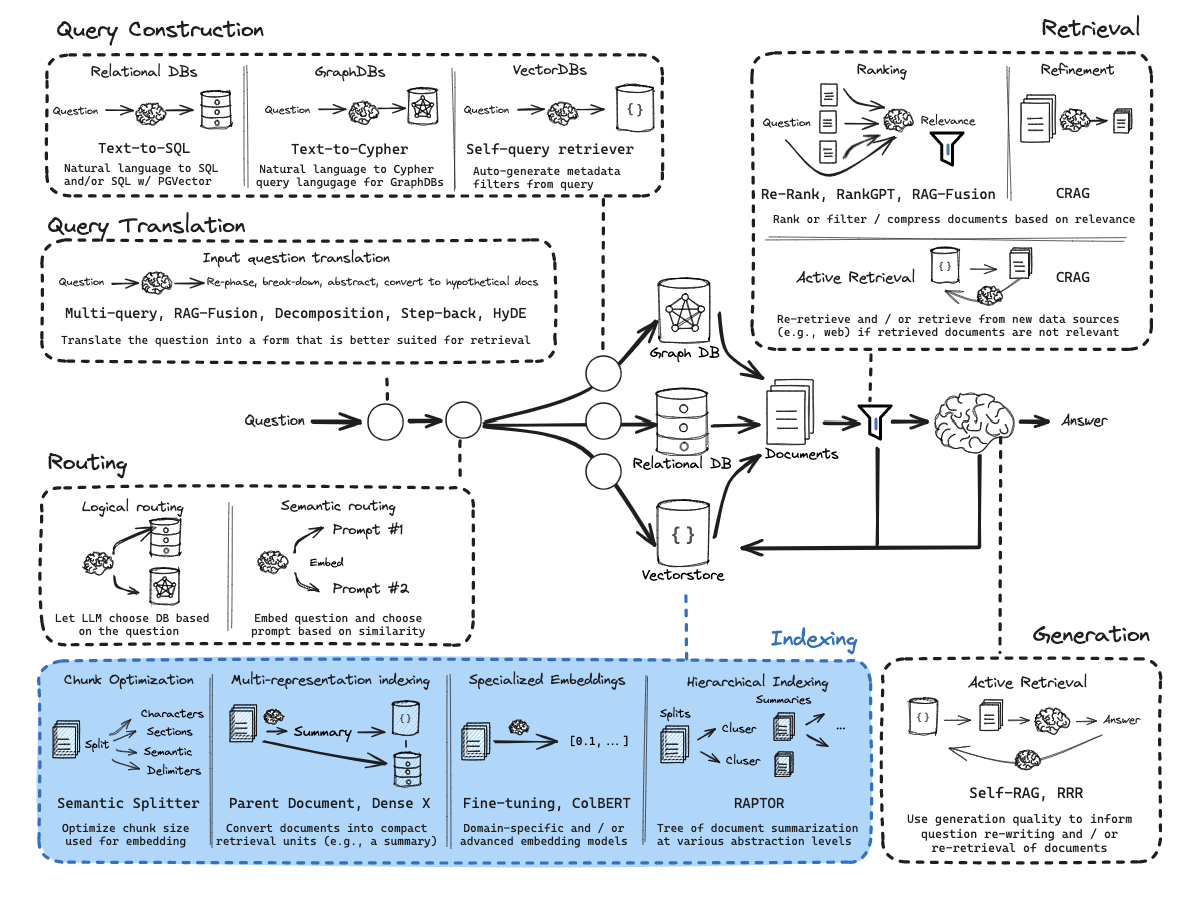
4. RAG实施细节
• 数据预处理:
• 代码: 使用AST解析器提取函数、类、注释等结构化信息,保留代码依赖关系。
• 文档: 提取标题层级、列表、表格等结构;使用OCR和表格提取工具处理复杂PDF;保留文档间引用关系。
• 分块 (Chunking):
• 代码: 采用多层级、语法感知的分块策略(文件->类->函数->代码块),保证语义单元完整性。
• 文档: 采用递归分块(章节->段落->句子),结合重叠窗口,保留结构信息。
• 嵌入模型:
• 代码: 推荐 microsoft/codebert-base 或类似代码专用模型,理解代码语法和语义。
• 文档: 推荐 BAAI/bge-large-zh-v1.5 或类似强中文/多语言模型,用于通用文本理解。
• 使用 DualEmbeddingPipeline 管理不同类型内容的嵌入生成。
• 向量数据库:
• 推荐 Qdrant,因其强大的元数据过滤能力、对混合搜索的支持、以及较好的部署灵活性。
• 为代码和文档分别建立Collection,使用不同维度(匹配嵌入模型)。
• 配置合适的索引参数(如HNSW)平衡查询速度与精度。
• 检索策略:
• 混合检索: 结合稠密向量检索(捕获语义)和稀疏检索(如BM25,捕获关键词)提高召回率。
• 查询转换: 应用多种策略(原始查询、历史重写、HyDE、退后提示、多查询变体)生成多个查询向量,扩大检索范围。
• 重排序: 使用 Cross-Encoder 模型(如 cross-encoder/ms-marco-MiniLM-L-6-v2)对初步召回结果进行精细排序,提升头部结果相关性。
• 多级检索: 先检索摘要/高级块,再深入到详细块。
5. LangGraph多智能体设计
• 核心Agent角色:
• 任务调度与协同Agent (Coordinator): 系统入口,负责意图识别、任务分解、状态流转、结果汇总、与用户交互。
• 查询分解Agent: 将复杂查询拆解为可执行的子任务。
• 多路检索Agent: 并行执行多种检索策略(向量、混合、代码特定、文档特定),调用RAG核心层。
• 代码分析Agent: 深度分析代码结构、功能、质量,调用AST解析等工具。
• 文档问答Agent: 处理文档内容理解和问答,处理PDF、Markdown等。
• 信息整合Agent: 合并来自多Agent、多数据源的信息,处理冲突。
• 验证Agent: 进行事实核查,评估信息一致性、可靠性,使用Self-RAG反思机制。
• 生成Agent: 基于整合、验证后的信息,选择合适的LLM和提示词生成最终答案。
• (可选) 开发辅助Agent: 专注于代码生成、优化、调试等开发场景。
• LangGraph应用:
• 使用 StateGraph 定义清晰的状态转换图,管理复杂工作流。
• 实现智能体之间的消息传递和状态共享。
• 支持条件分支(根据查询类型、中间结果质量路由)、并行处理(多路检索)、循环机制(迭代深化、验证重试)。
• 协作模式:
• 串行: 任务有严格依赖顺序。
• 并行: 子任务可独立执行以提高效率。
• 迭代深化: 对于复杂问题,逐步求精。
• 反思改进: 基于验证结果调整策略或重新执行部分流程。
• 解决RAG挑战: 通过专业分工(如代码分析Agent处理结构化代码)、多策略并行(提高召回)、信息整合与验证(提高准确性、完整性、减少幻觉)等方式应对各项挑战。
6. 数据持续接入与更新策略
• 变更监控:
• 代码库: 使用Webhooks(实时)和定期轮询(兜底)监控Git/SVN提交。
• 文档系统: 监控文件系统修改时间、Wiki/CMS API版本或更新时间戳。
• 增量处理:
• 变更分析: 分析变更类型(增删改)、影响范围(依赖图)、评估优先级。
• 处理流水线: 根据分析结果,仅对变更及其受影响部分执行预处理、分块、嵌入。
• 向量数据库更新:
• 增量Upsert: 使用 upsert 操作更新或插入向量,利用向量数据库的去重能力。
• 批量优化: 聚合小型更新,使用批处理接口提高效率,设置刷新间隔和批次大小阈值。
• 删除处理: 监控删除事件,从向量数据库中删除对应向量。
• 索引优化与重建:
• 增量优化: 定期执行向量数据库提供的增量优化操作。
• 定期/条件重建: 根据时间、变更量或性能指标,定期执行索引全量重建,保证索引健康度。采用蓝绿部署(创建临时集合->复制->验证->切换->删除旧集合)保证服务连续性。
• 时效性与版本控制:
• 时间元数据: 为数据块添加摄入时间、更新时间、过期时间(可选)等元数据。
• 过期数据清理: 定期检查并删除过期数据。
• 知识快照: 定期或按需创建知识库快照(元数据+可选数据备份),支持版本回滚。
• 质量保障与监控:
• 数据质量验证: 在数据入库前进行自动验证(格式、长度、完整性、可选语义检查)。
• 检索效果监控: 使用标准Benchmark查询集定期评估检索性能(Precision@K, Recall@K, MRR),设置告警阈值,监控性能衰退。
7. 技术选型总结
• 核心框架: LangGraph (用于多智能体编排与状态管理)
• 编程语言: Python
• 向量数据库: Qdrant (推荐) 或 Milvus/Weaviate (根据规模和需求选择)
• 嵌入模型: Sentence Transformers库,CodeBERT (代码),BGE-large-zh (文本)
• 重排序模型: Cross-Encoder (如 ms-marco-MiniLM-L-6-v2)
• LLM: 根据需求选择合适的模型 (如 GPT系列, Claude系列, 或特定领域微调模型)
• 代码解析: AST解析库 (如 Python ast)
• PDF处理: PyMuPDF, Unstructured.io, 或特定OCR/表格提取服务
8. 潜在挑战与应对策略
• 系统复杂性: 多智能体协调、状态管理复杂。
• 应对: 充分利用LangGraph的抽象能力,设计清晰的Agent职责和状态图,加强日志和监控。
• 数据一致性: 保证代码、文档、元数据更新的同步和一致。
• 应对: 强化变更分析中的依赖识别,事务性更新(若数据库支持),建立严格的验证流程。
• 性能与延迟: 复杂的工作流可能导致响应延迟。
• 应对: 优化Agent协作模式(并行化),缓存中间结果,选择高效模型和数据库,优化索引。
• 准确性与幻觉: 整合多源信息可能引入冲突,LLM仍可能产生幻觉。
• 应对: 强化验证Agent的作用,设计冲突解决策略,明确标注信息来源和置信度,利用反馈进行优化。
• 扩展性: 数据量和用户请求增长带来的压力。
• 应对: 采用分布式架构,选择可扩展的向量数据库,优化增量更新流程,容器化部署。
• 成本控制: LLM调用和计算资源消耗。
• 应对: 优化提示词,智能路由任务给成本更低的模型或非LLM工具,高效利用缓存。
• 数据安全与隐私: 处理私有代码库和文档的风险。
• 应对: 部署在安全环境,严格权限控制,数据脱敏(若需),遵守相关法规。
9. 项目路线图/未来展望
初期 (MVP): 搭建核心RAG流程和基础Agent框架,支持代码和Markdown文档检索问答。
中期: 完善所有核心Agent角色,实现复杂的协作流,增强代码分析和生成能力,支持PDF等更多格式,建立完整的持续更新和监控机制。
长期:
深度集成: 与IDE、CI/CD、项目管理工具深度集成。
个性化与自适应: 基于用户反馈和使用习惯进行个性化推荐和学习。
多模态支持: 扩展支持图像、图表等非文本数据的理解。
主动智能: 实现主动问题发现、建议推送等前瞻性功能。
团队协作增强: 支持团队知识共享和协作开发场景。
10. 总结
RAG-Agent项目通过结合先进的RAG技术和创新的LangGraph多智能体协作框架,旨在构建一个功能强大、适应性强、准确可靠的智能开发助手和知识管理系统。该系统有望显著提升开发者效率,改善知识获取体验,并通过持续的数据管理和质量保障机制,确保其长期价值。虽然面临挑战,但通过周密的设计和技术选型,本项目具备解决核心痛点并取得成功的巨大潜力。