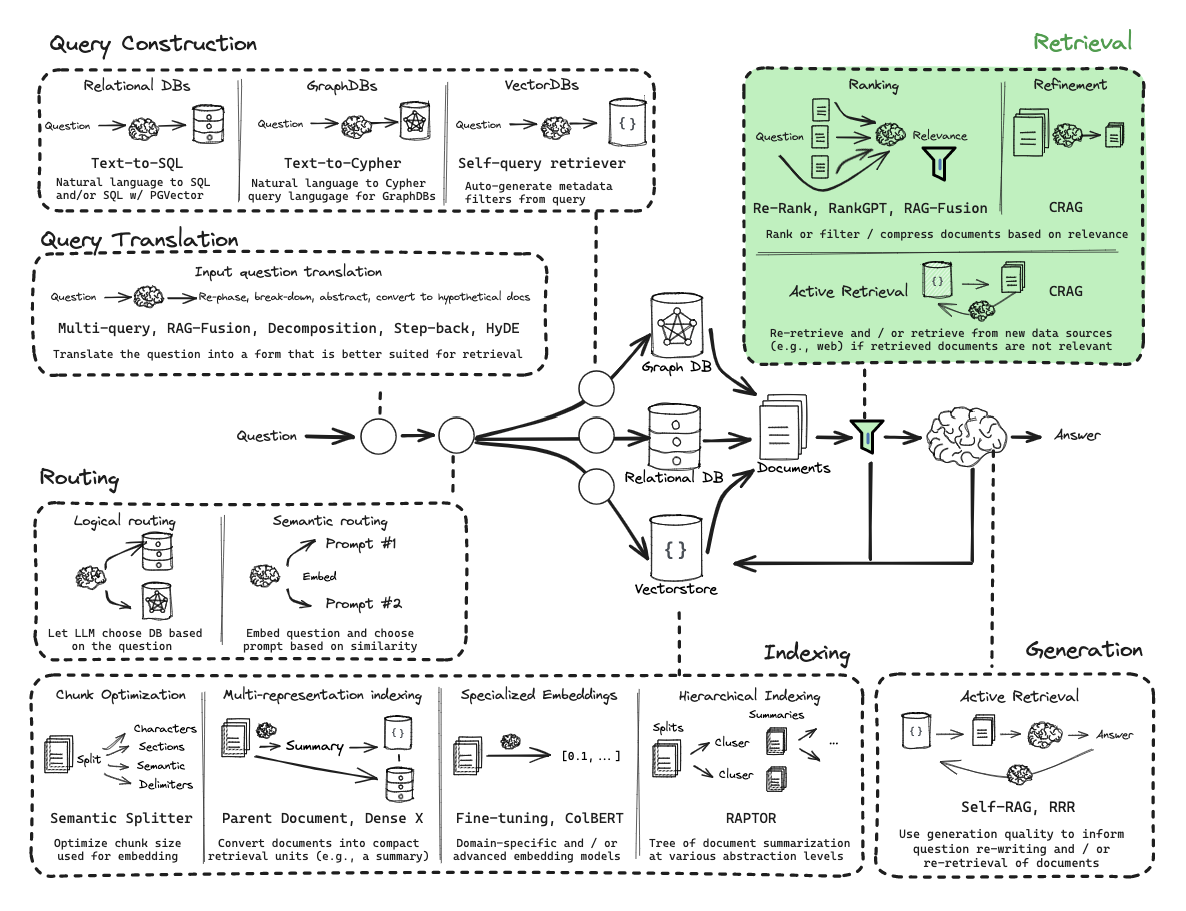
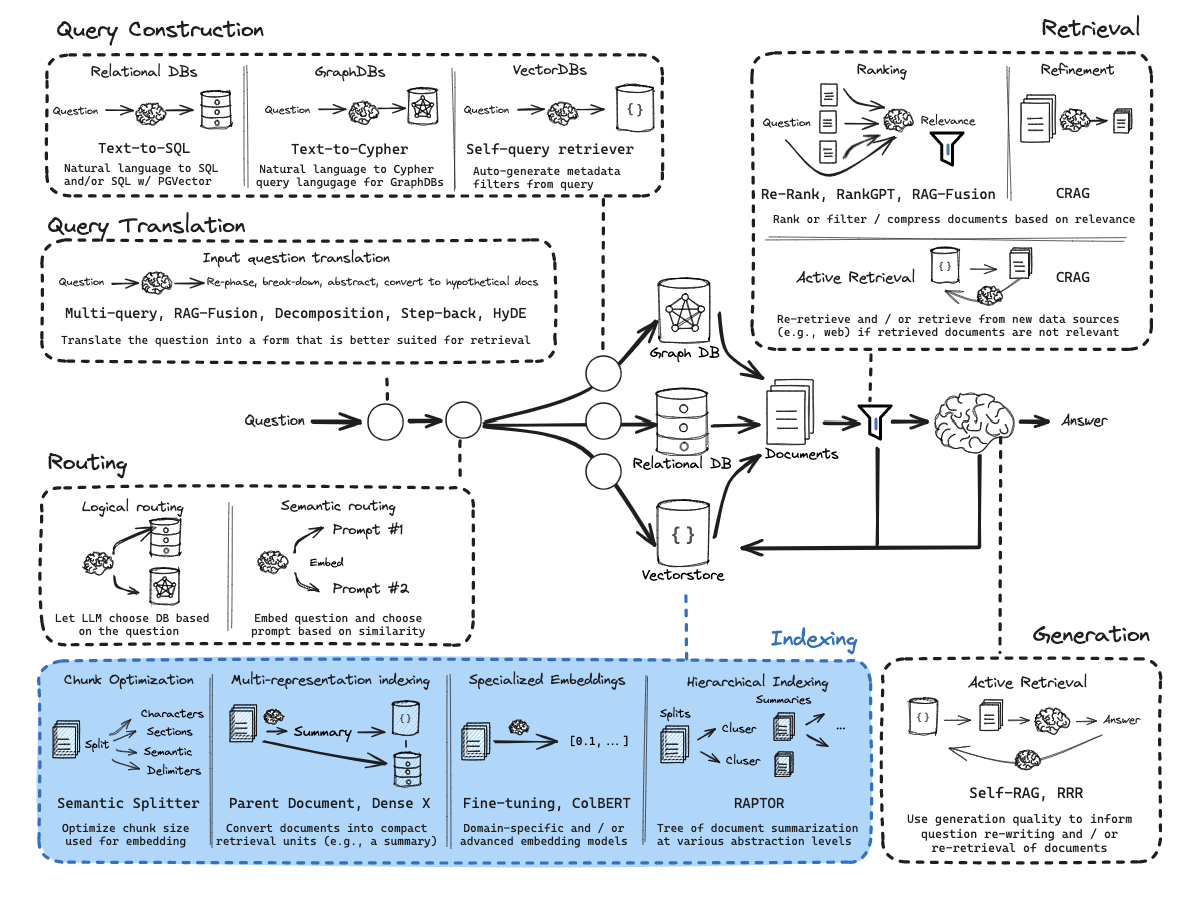
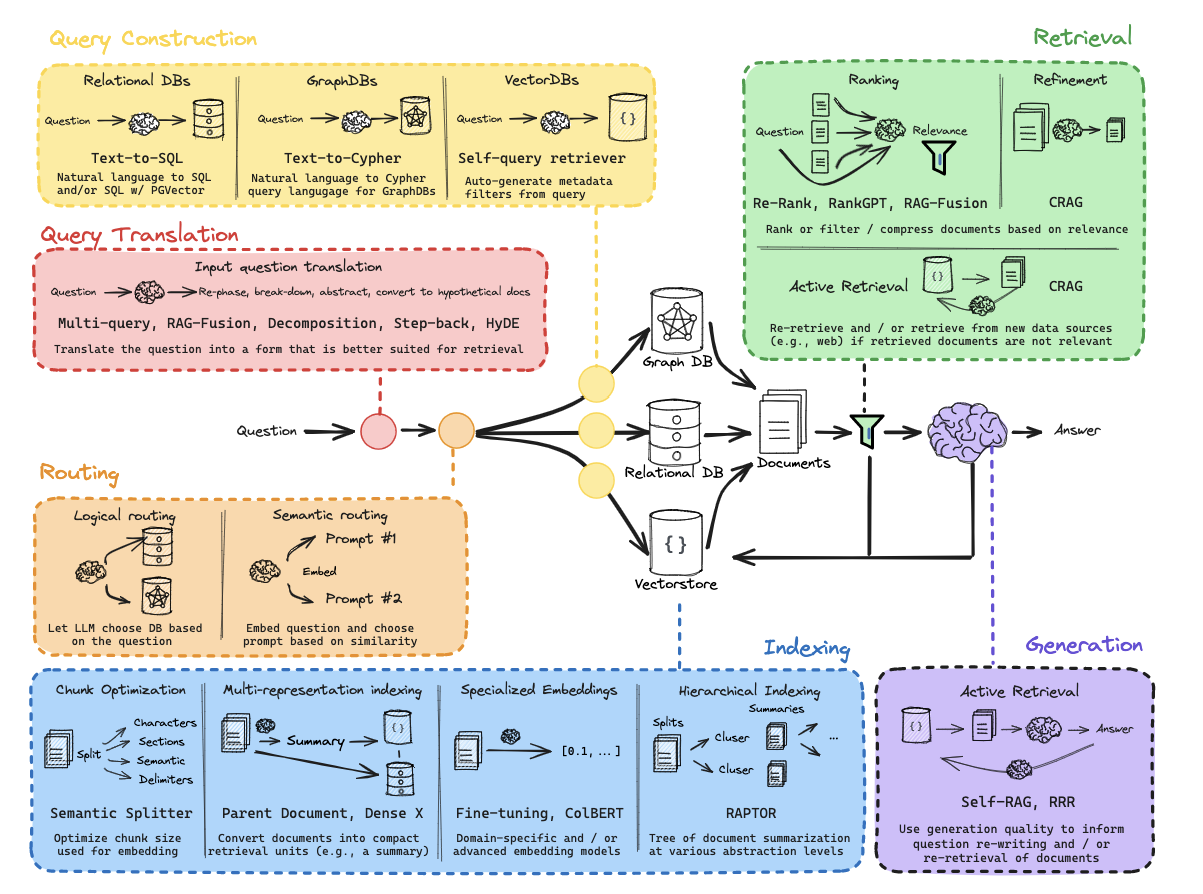
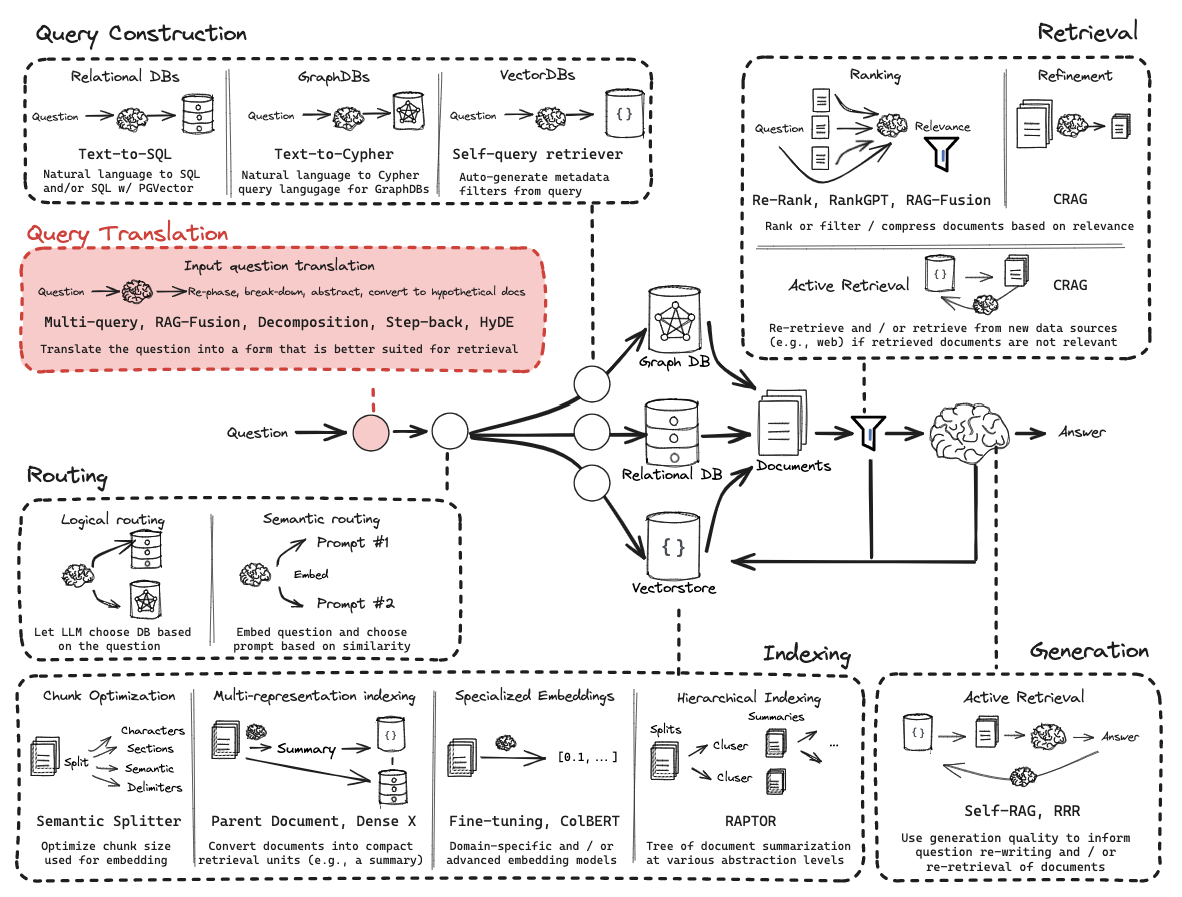
从零开始的RAG:检索
环境
(1) 包
1 ! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain cohere
(2) LangSmith
https://docs.smith.langchain.com/
1 2 3 4 import osos.environ['LANGCHAIN_TRACING_V2' ] = 'true' os.environ['LANGCHAIN_ENDPOINT' ] = 'https://api.smith.langchain.com' os.environ['LANGCHAIN_API_KEY' ] = <your-api-key>
(3) API 密钥
1 2 os.environ['OPENAI_API_KEY' ] = <your-api-key> os.environ['COHERE_API_KEY' ] = <your-api-key>
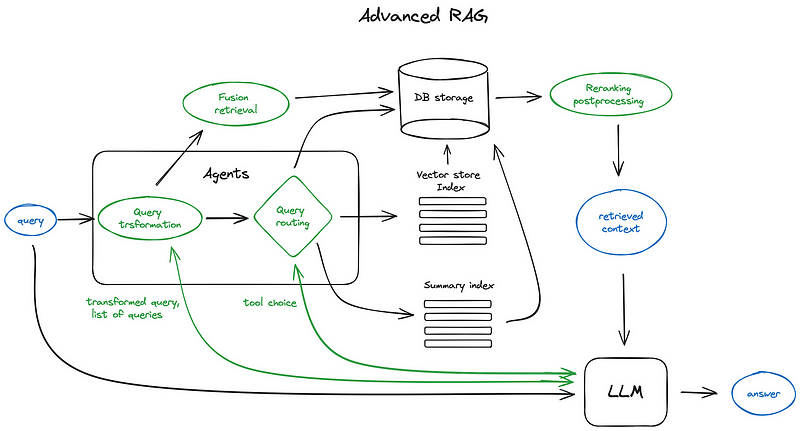
第15部分:重新排序
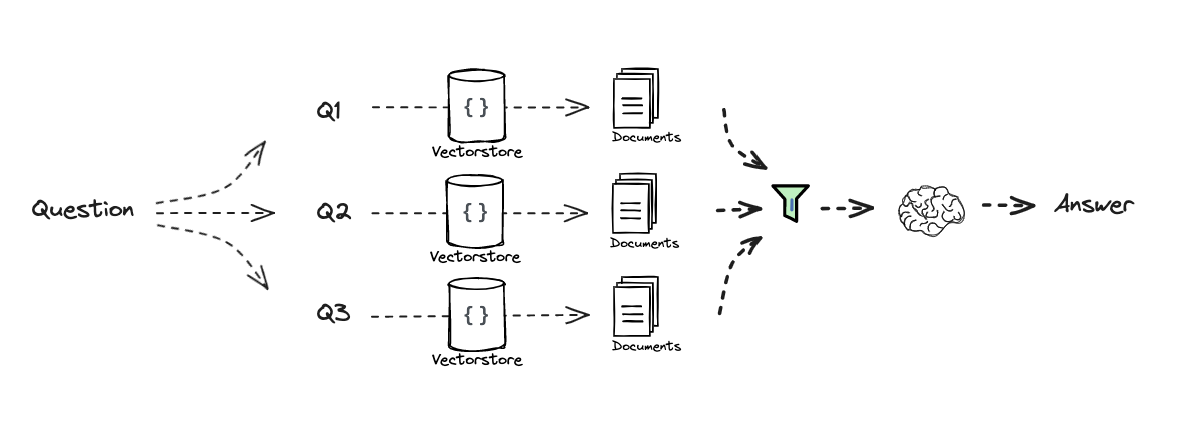
我们之前在RAG-fusion中展示过这个。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import bs4from langchain_community.document_loaders import WebBaseLoaderloader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/" ,), bs_kwargs=dict ( parse_only=bs4.SoupStrainer( class_=("post-content" , "post-title" , "post-header" ) ) ), ) blog_docs = loader.load() from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( chunk_size=300 , chunk_overlap=50 ) splits = text_splitter.split_documents(blog_docs) from langchain_openai import OpenAIEmbeddingsfrom langchain_community.vectorstores import Chromavectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings()) retriever = vectorstore.as_retriever()
1 2 3 4 5 6 7 from langchain.prompts import ChatPromptTemplatetemplate = """你是一个有帮助的助手,可以根据单个输入查询生成多个搜索查询。\n 生成与以下内容相关的多个搜索查询:{question} \n 输出(4个查询):""" prompt_rag_fusion = ChatPromptTemplate.from_template(template)
1 2 3 4 5 6 7 8 9 from langchain_core.output_parsers import StrOutputParserfrom langchain_openai import ChatOpenAIgenerate_queries = ( prompt_rag_fusion | ChatOpenAI(temperature=0 ) | StrOutputParser() | (lambda x: x.split("\n" )) )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from langchain.load import dumps, loadsdef reciprocal_rank_fusion (results: list [list ], k=60 ): """ 互惠排名融合,接受多个排名文档列表和一个可选参数k用于RRF公式 """ fused_scores = {} for docs in results: for rank, doc in enumerate (docs): doc_str = dumps(doc) if doc_str not in fused_scores: fused_scores[doc_str] = 0 previous_score = fused_scores[doc_str] fused_scores[doc_str] += 1 / (rank + k) reranked_results = [ (loads(doc), score) for doc, score in sorted (fused_scores.items(), key=lambda x: x[1 ], reverse=True ) ] return reranked_results question = "What is task decomposition for LLM agents?" retrieval_chain_rag_fusion = generate_queries | retriever.map () | reciprocal_rank_fusion docs = retrieval_chain_rag_fusion.invoke({"question" : question}) len (docs)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from operator import itemgetterfrom langchain_core.runnables import RunnablePassthroughtemplate = """根据以下上下文回答问题: {context} 问题:{question} """ prompt = ChatPromptTemplate.from_template(template) llm = ChatOpenAI(temperature=0 ) final_rag_chain = ( {"context" : retrieval_chain_rag_fusion, "question" : itemgetter("question" )} | prompt | llm | StrOutputParser() ) final_rag_chain.invoke({"question" :question})
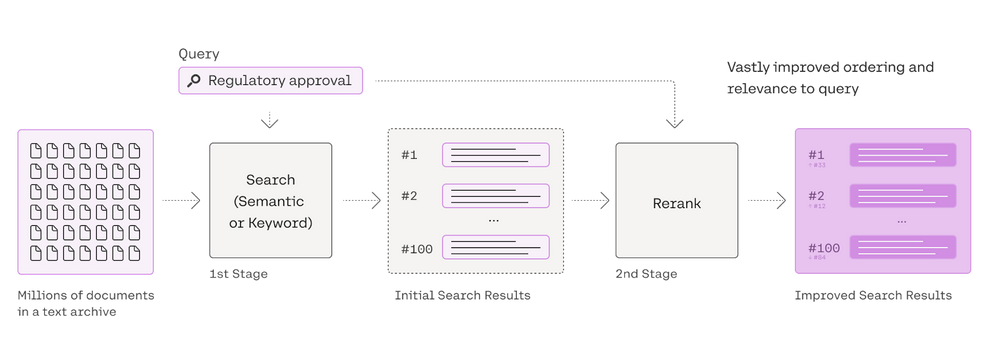
我们还可以使用Cohere Re-Rank 。
请参阅这里 :
1 2 3 from langchain_community.llms import Coherefrom langchain.retrievers import ContextualCompressionRetrieverfrom langchain.retrievers.document_compressors import CohereRerank
1 2 3 4 5 6 7 8 9 10 11 from langchain.retrievers.document_compressors import CohereRerankretriever = vectorstore.as_retriever(search_kwargs={"k" : 10 }) compressor = CohereRerank() compression_retriever = ContextualCompressionRetriever( base_compressor=compressor, base_retriever=retriever ) compressed_docs = compression_retriever.get_relevant_documents(question)
16 - 检索 (CRAG)
深入探讨
https://www.youtube.com/watch?v=E2shqsYwxck
笔记本
https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_crag.ipynb
https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_crag_mistral.ipynb
生成
17 - 检索 (Self-RAG)
笔记本
https://github.com/langchain-ai/langgraph/tree/main/examples/rag
https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_self_rag_mistral_nomic.ipynb
18 - 长上下文的影响
深入探讨
https://www.youtube.com/watch?v=SsHUNfhF32s
幻灯片
https://docs.google.com/presentation/d/1mJUiPBdtf58NfuSEQ7pVSEQ2Oqmek7F1i4gBwR6JDss/edit#slide=id.g26c0cb8dc66_0_0