
从零开始的RAG:索引
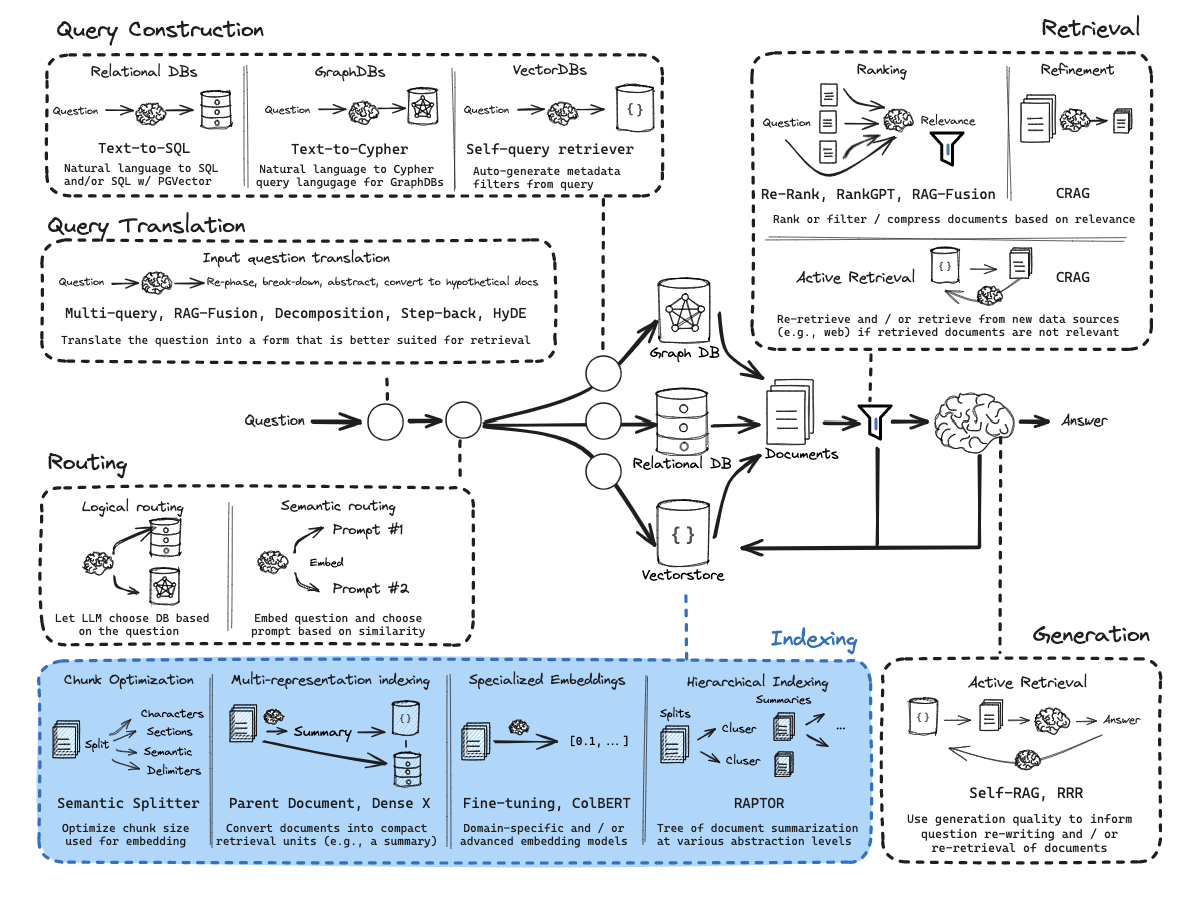
前言:分块
我们没有明确涵盖文档分块/拆分。
关于文档分块的优秀评论,请参阅Greg Kamradt的视频:
https://www.youtube.com/watch?v=8OJC21T2SL4
环境
(1) 包
python
! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain youtube-transcript-api pytube(2) LangSmith
https://docs.smith.langchain.com/
python
import os
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
os.environ['LANGCHAIN_API_KEY'] = <your-api-key>(3) API 密钥
python
os.environ['OPENAI_API_KEY'] = <your-api-key>第12部分:多表示索引
流程:
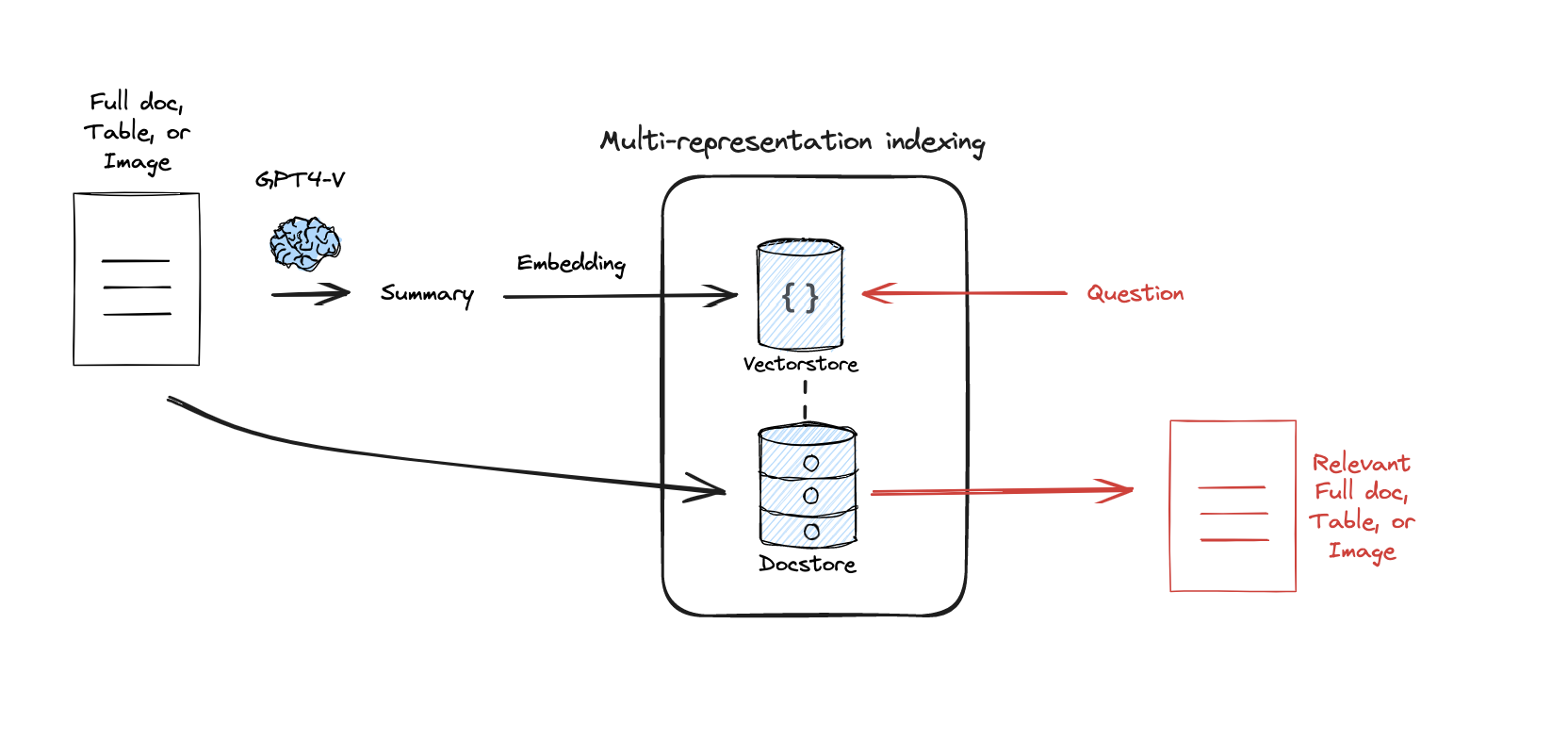
文档:
https://blog.langchain.dev/semi-structured-multi-modal-rag/
https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector
论文:
https://arxiv.org/abs/2312.06648
python
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
loader = WebBaseLoader("https://lilianweng.github.io/posts/2024-02-05-human-data-quality/")
docs.extend(loader.load())python
import uuid
from langchain_core.documents import Document
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
chain = (
{"doc": lambda x: x.page_content}
| ChatPromptTemplate.from_template("Summarize the following document:\n\n{doc}")
| ChatOpenAI(model="gpt-3.5-turbo",max_retries=0)
| StrOutputParser()
)
summaries = chain.batch(docs, {"max_concurrency": 5})python
from langchain.storage import InMemoryByteStore
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.retrievers.multi_vector import MultiVectorRetriever
# 用于索引子块的向量存储
vectorstore = Chroma(collection_name="summaries",
embedding_function=OpenAIEmbeddings())
# 父文档的存储层
store = InMemoryByteStore()
id_key = "doc_id"
# 检索器
retriever = MultiVectorRetriever(
vectorstore=vectorstore,
byte_store=store,
id_key=id_key,
)
doc_ids = [str(uuid.uuid4()) for _ in docs]
# 与摘要链接的文档
summary_docs = [
Document(page_content=s, metadata={id_key: doc_ids[i]})
for i, s in enumerate(summaries)
]
# 添加
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))python
query = "Memory in agents"
sub_docs = vectorstore.similarity_search(query,k=1)
sub_docs[0]python
retrieved_docs = retriever.get_relevant_documents(query,n_results=1)
retrieved_docs[0].page_content[0:500]相关想法是父文档检索器。
第13部分:RAPTOR
流程:
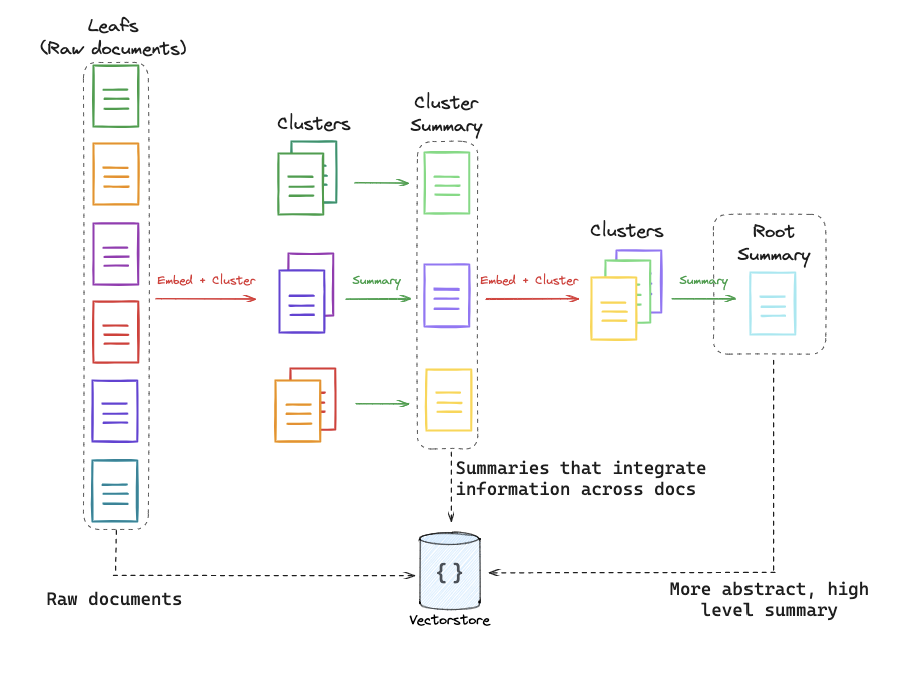
深入视频:
https://www.youtube.com/watch?v=jbGchdTL7d0
论文:
https://arxiv.org/pdf/2401.18059.pdf
完整代码:
https://github.com/langchain-ai/langchain/blob/master/cookbook/RAPTOR.ipynb
第14部分:ColBERT
RAGatouille使得使用ColBERT变得简单。
ColBERT为段落中的每个token生成一个上下文影响的向量。
ColBERT同样为查询中的每个token生成向量。
然后,每个文档的得分是每个查询嵌入与任何文档嵌入的最大相似性的总和:
python
! pip install -U ragatouillepython
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")python
import requests
def get_wikipedia_page(title: str):
"""
检索维基百科页面的完整文本内容。
:param title: str - 维基百科页面的标题。
:return: str - 页面的完整文本内容作为原始字符串。
"""
# 维基百科API端点
URL = "https://en.wikipedia.org/w/api.php"
# API请求的参数
params = {
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
"explaintext": True,
}
# 自定义User-Agent头以符合维基百科的最佳实践
headers = {"User-Agent": "RAGatouille_tutorial/0.0.1 (ben@clavie.eu)"}
response = requests.get(URL, params=params, headers=headers)
data = response.json()
# 提取页面内容
page = next(iter(data["query"]["pages"].values()))
return page["extract"] if "extract" in page else None
full_document = get_wikipedia_page("Hayao_Miyazaki")python
RAG.index(
collection=[full_document],
index_name="Miyazaki-123",
max_document_length=180,
split_documents=True,
)python
results = RAG.search(query="What animation studio did Miyazaki found?", k=3)
resultspython
retriever = RAG.as_langchain_retriever(k=3)
retriever.invoke("What animation studio did Miyazaki found?")
评论