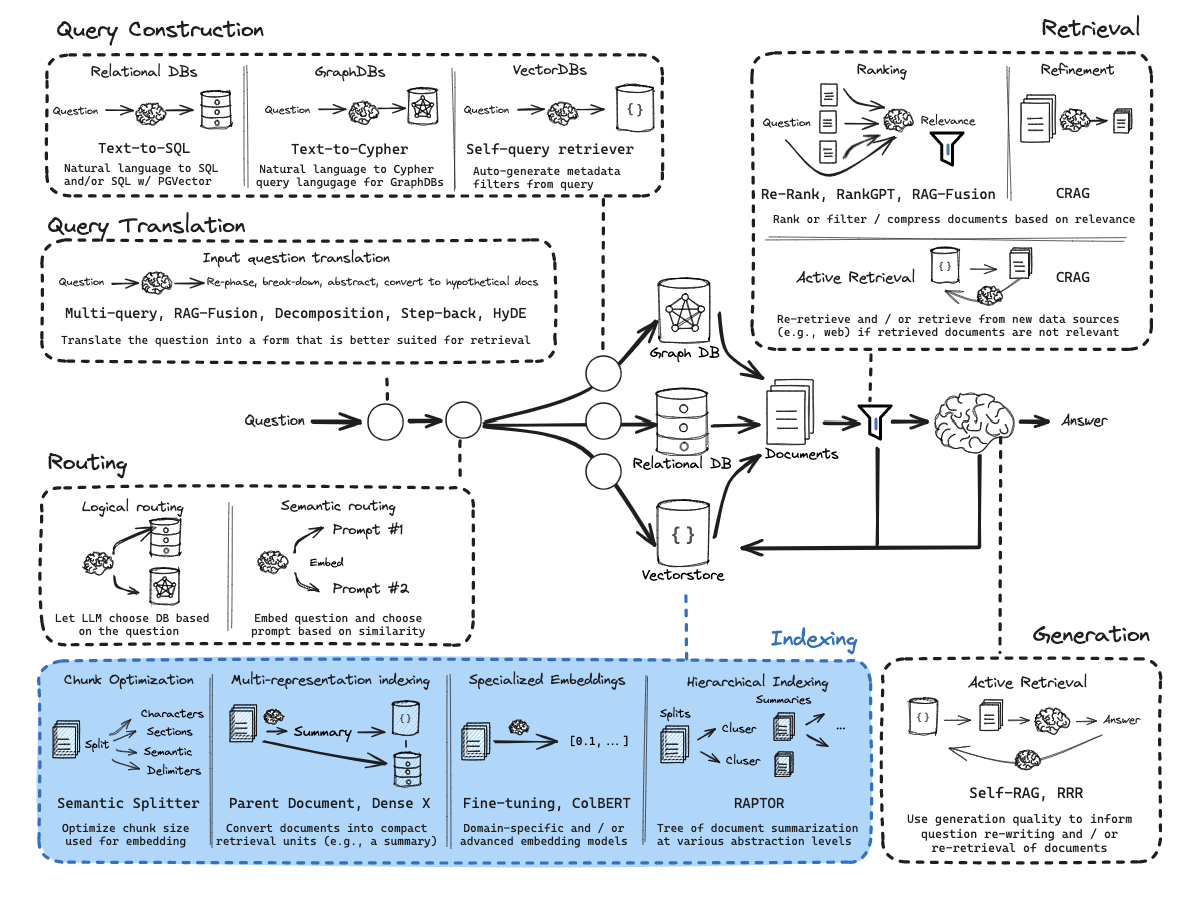
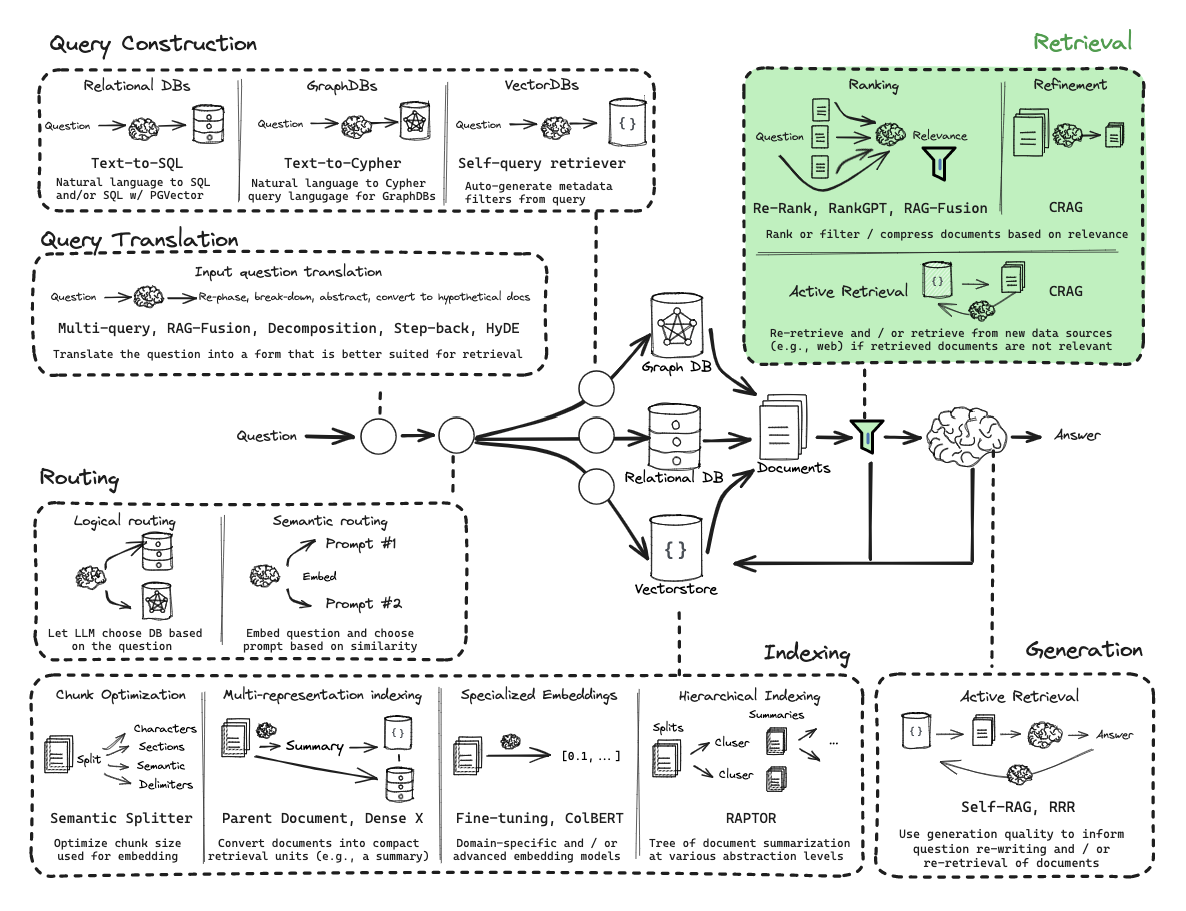
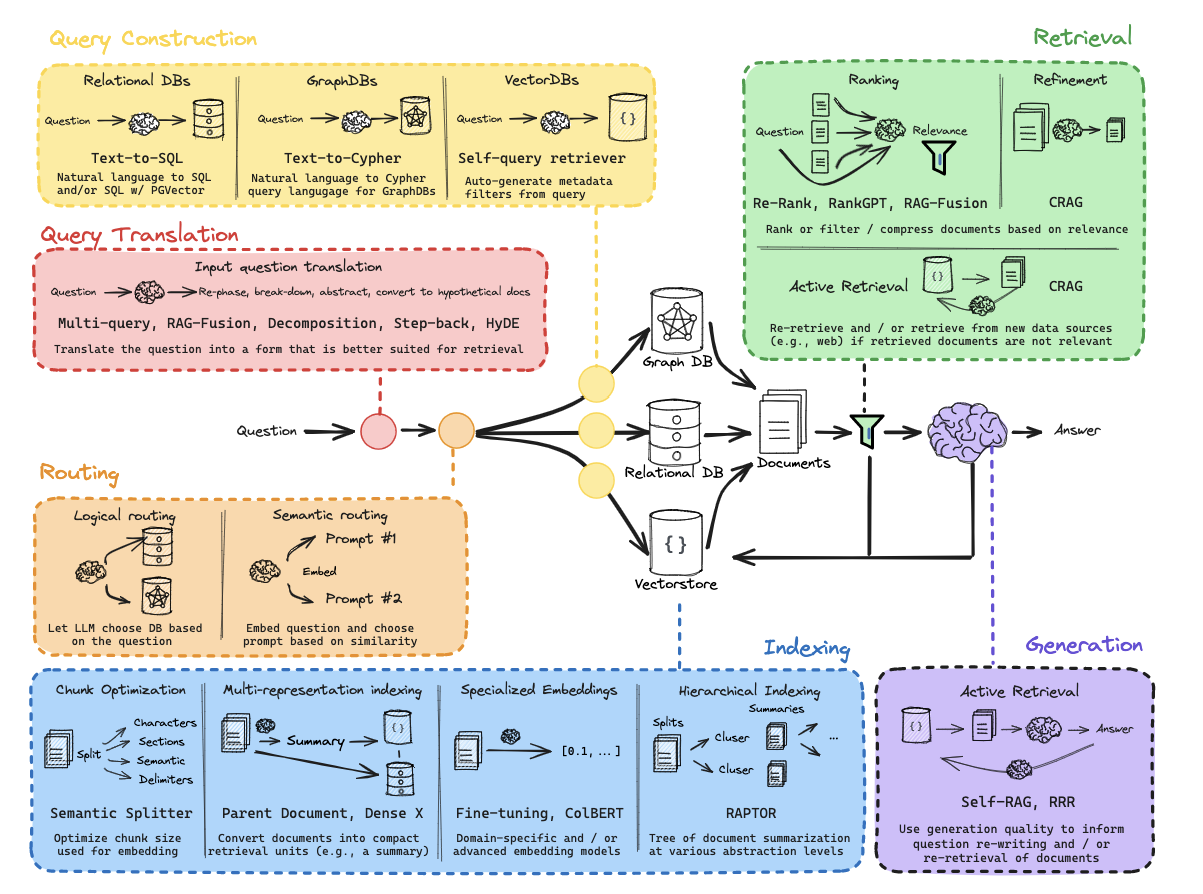
从零开始的RAG:查询转换
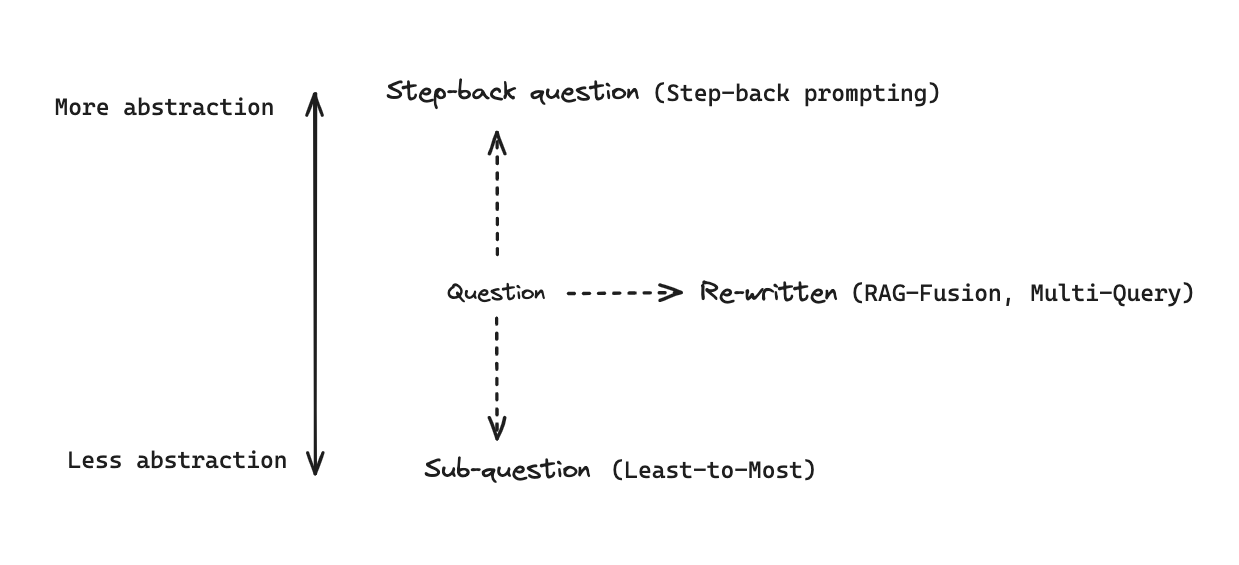
查询转换是一组专注于重写和/或修改检索问题的方法。
环境
(1) 包
1 ! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain
(2) LangSmith
https://docs.smith.langchain.com/
1 2 3 4 import osos.environ['LANGCHAIN_TRACING_V2' ] = 'true' os.environ['LANGCHAIN_ENDPOINT' ] = 'https://api.smith.langchain.com' os.environ['LANGCHAIN_API_KEY' ] = <your-api-key>
(3) API 密钥
1 os.environ['OPENAI_API_KEY' ] = <your-api-key>
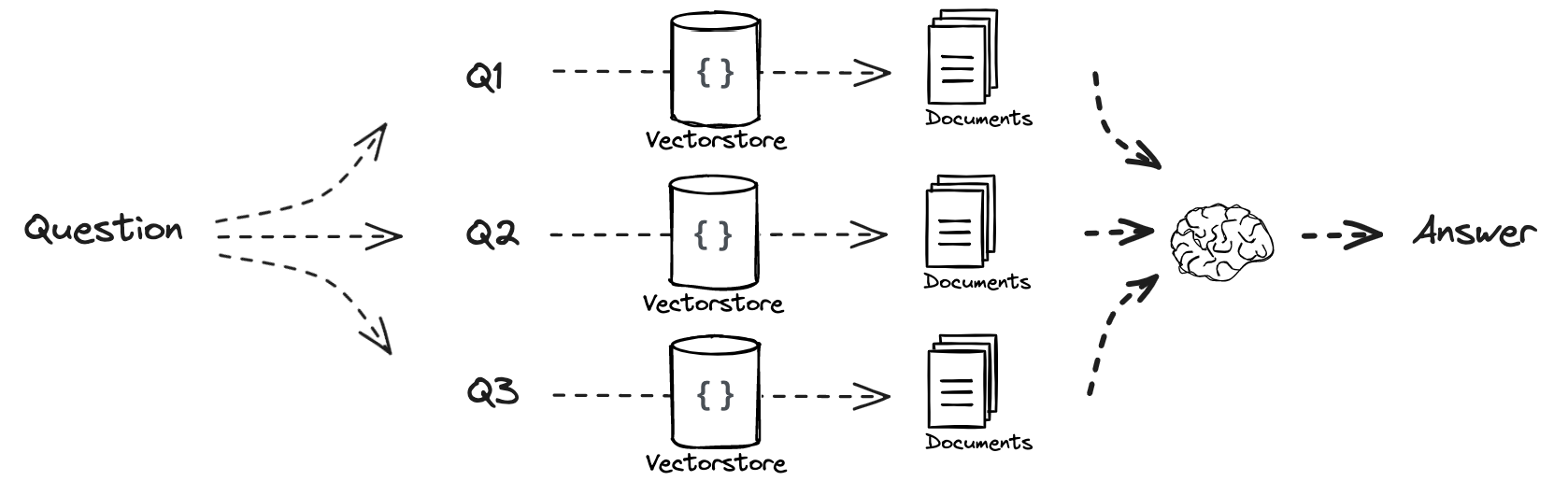
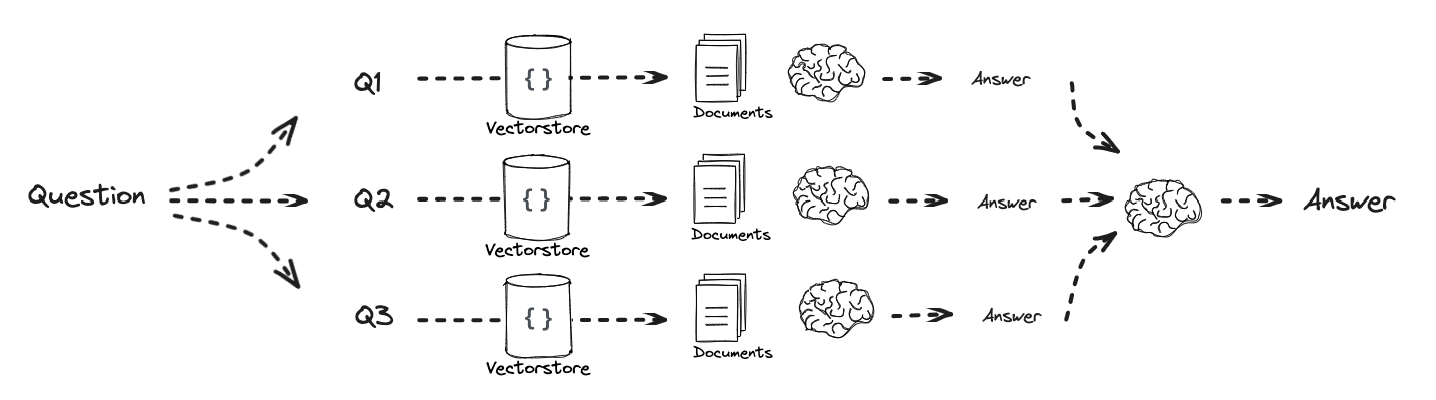
第5部分:多查询
流程:
文档:
索引
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import bs4from langchain_community.document_loaders import WebBaseLoaderloader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/" ,), bs_kwargs=dict ( parse_only=bs4.SoupStrainer( class_=("post-content" , "post-title" , "post-header" ) ) ), ) blog_docs = loader.load() from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( chunk_size=300 , chunk_overlap=50 ) splits = text_splitter.split_documents(blog_docs) from langchain_openai import OpenAIEmbeddingsfrom langchain_community.vectorstores import Chromavectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings()) retriever = vectorstore.as_retriever()
提示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from langchain.prompts import ChatPromptTemplatetemplate = """你是一个AI语言模型助手。你的任务是生成五个不同版本的用户问题,以从向量数据库中检索相关文档。通过对用户问题生成多个视角,你的目标是帮助用户克服基于距离的相似性搜索的一些限制。请提供这些替代问题,并用换行符分隔。原始问题:{question}""" prompt_perspectives = ChatPromptTemplate.from_template(template) from langchain_core.output_parsers import StrOutputParserfrom langchain_openai import ChatOpenAIgenerate_queries = ( prompt_perspectives | ChatOpenAI(temperature=0 ) | StrOutputParser() | (lambda x: x.split("\n" )) )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from langchain.load import dumps, loadsdef get_unique_union (documents: list [list ] ): """ 检索文档的唯一并集 """ flattened_docs = [dumps(doc) for sublist in documents for doc in sublist] unique_docs = list (set (flattened_docs)) return [loads(doc) for doc in unique_docs] question = "What is task decomposition for LLM agents?" retrieval_chain = generate_queries | retriever.map () | get_unique_union docs = retrieval_chain.invoke({"question" :question}) len (docs)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from operator import itemgetterfrom langchain_openai import ChatOpenAIfrom langchain_core.runnables import RunnablePassthroughtemplate = """根据以下上下文回答问题: {context} 问题:{question} """ prompt = ChatPromptTemplate.from_template(template) llm = ChatOpenAI(temperature=0 ) final_rag_chain = ( {"context" : retrieval_chain, "question" : itemgetter("question" )} | prompt | llm | StrOutputParser() ) final_rag_chain.invoke({"question" :question})
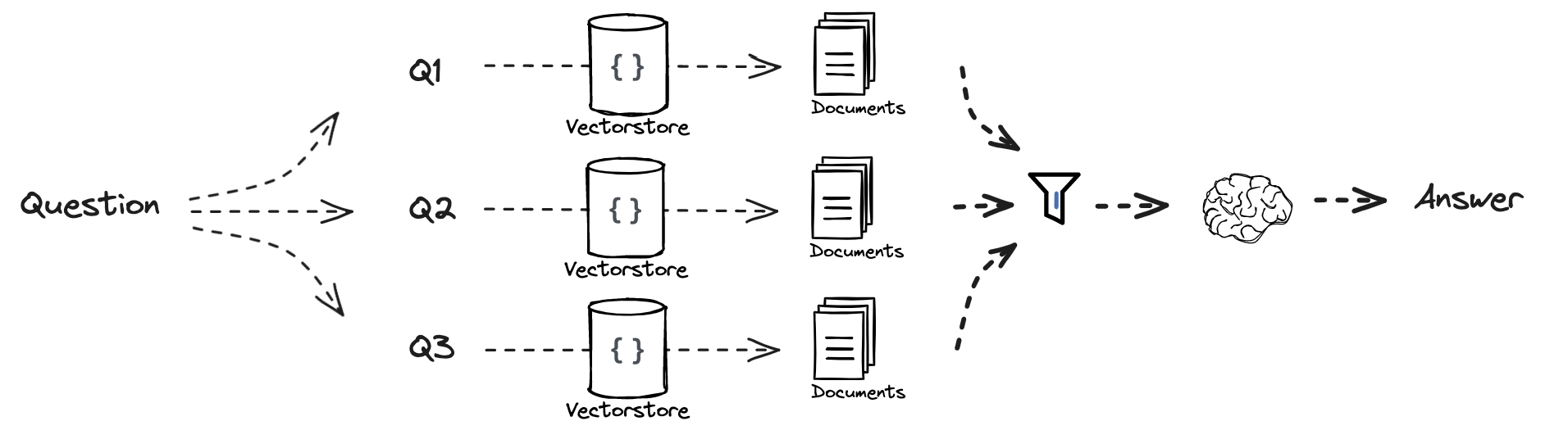
第6部分:RAG-Fusion
流程:
文档:
博客/仓库:
提示
1 2 3 4 5 6 7 from langchain.prompts import ChatPromptTemplatetemplate = """你是一个有帮助的助手,可以根据单个输入查询生成多个搜索查询。\n 生成与以下内容相关的多个搜索查询:{question} \n 输出(4个查询):""" prompt_rag_fusion = ChatPromptTemplate.from_template(template)
1 2 3 4 5 6 7 8 9 from langchain_core.output_parsers import StrOutputParserfrom langchain_openai import ChatOpenAIgenerate_queries = ( prompt_rag_fusion | ChatOpenAI(temperature=0 ) | StrOutputParser() | (lambda x: x.split("\n" )) )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from langchain.load import dumps, loadsdef reciprocal_rank_fusion (results: list [list ], k=60 ): """ 互惠排名融合,接受多个排名文档列表和一个可选参数k用于RRF公式 """ fused_scores = {} for docs in results: for rank, doc in enumerate (docs): doc_str = dumps(doc) if doc_str not in fused_scores: fused_scores[doc_str] = 0 previous_score = fused_scores[doc_str] fused_scores[doc_str] += 1 / (rank + k) reranked_results = [ (loads(doc), score) for doc, score in sorted (fused_scores.items(), key=lambda x: x[1 ], reverse=True ) ] return reranked_results retrieval_chain_rag_fusion = generate_queries | retriever.map () | reciprocal_rank_fusion docs = retrieval_chain_rag_fusion.invoke({"question" : question}) len (docs)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from langchain_core.runnables import RunnablePassthroughtemplate = """根据以下上下文回答问题: {context} 问题:{question} """ prompt = ChatPromptTemplate.from_template(template) final_rag_chain = ( {"context" : retrieval_chain_rag_fusion, "question" : itemgetter("question" )} | prompt | llm | StrOutputParser() ) final_rag_chain.invoke({"question" :question})
追踪:
https://smith.langchain.com/public/071202c9-9f4d-41b1-bf9d-86b7c5a7525b/r
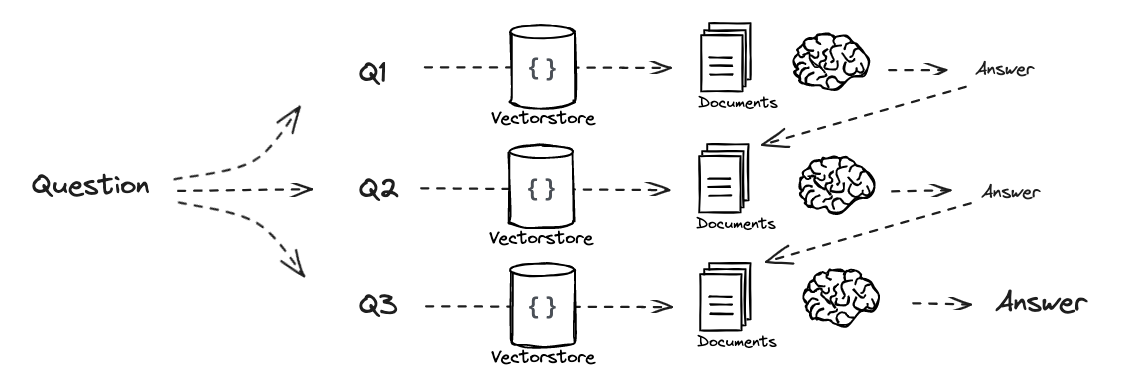
第7部分:分解
1 2 3 4 5 6 7 8 from langchain.prompts import ChatPromptTemplatetemplate = """你是一个有帮助的助手,可以生成与输入问题相关的多个子问题。\n 目标是将输入分解为一组可以单独回答的子问题/子问题。\n 生成与以下内容相关的多个搜索查询:{question} \n 输出(3个查询):""" prompt_decomposition = ChatPromptTemplate.from_template(template)
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_openai import ChatOpenAIfrom langchain_core.output_parsers import StrOutputParserllm = ChatOpenAI(temperature=0 ) generate_queries_decomposition = ( prompt_decomposition | llm | StrOutputParser() | (lambda x: x.split("\n" ))) question = "What are the main components of an LLM-powered autonomous agent system?" questions = generate_queries_decomposition.invoke({"question" :question})
递归回答
论文:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 template = """这是你需要回答的问题: \n --- \n {question} \n --- \n 这是任何可用的背景问题+答案对: \n --- \n {q_a_pairs} \n --- \n 这是与问题相关的额外上下文: \n --- \n {context} \n --- \n 使用上述上下文和任何背景问题+答案对来回答问题:\n {question} """ decomposition_prompt = ChatPromptTemplate.from_template(template)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from operator import itemgetterfrom langchain_core.output_parsers import StrOutputParserdef format_qa_pair (question, answer ): """格式化问答对""" formatted_string = "" formatted_string += f"问题:{question} \n答案:{answer} \n\n" return formatted_string.strip() llm = ChatOpenAI(model_name="gpt-3.5-turbo" , temperature=0 ) q_a_pairs = "" for q in questions: rag_chain = ( {"context" : itemgetter("question" ) | retriever, "question" : itemgetter("question" ), "q_a_pairs" : itemgetter("q_a_pairs" )} | decomposition_prompt | llm | StrOutputParser()) answer = rag_chain.invoke({"question" :q,"q_a_pairs" :q_a_pairs}) q_a_pair = format_qa_pair(q,answer) q_a_pairs = q_a_pairs + "\n---\n" + q_a_pair
单独回答
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 from langchain import hubfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.runnables import RunnablePassthrough, RunnableLambdafrom langchain_core.output_parsers import StrOutputParserfrom langchain_openai import ChatOpenAIprompt_rag = hub.pull("rlm/rag-prompt" ) def retrieve_and_rag (question,prompt_rag,sub_question_generator_chain ): """对每个子问题进行RAG""" sub_questions = sub_question_generator_chain.invoke({"question" :question}) rag_results = [] for sub_question in sub_questions: retrieved_docs = retriever.get_relevant_documents(sub_question) answer = (prompt_rag | llm | StrOutputParser()).invoke({"context" : retrieved_docs, "question" : sub_question}) rag_results.append(answer) return rag_results,sub_questions answers, questions = retrieve_and_rag(question, prompt_rag, generate_queries_decomposition)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def format_qa_pairs (questions, answers ): """格式化问答对""" formatted_string = "" for i, (question, answer) in enumerate (zip (questions, answers), start=1 ): formatted_string += f"问题 {i} :{question} \n答案 {i} :{answer} \n\n" return formatted_string.strip() context = format_qa_pairs(questions, answers) template = """这是一组问答对: {context} 使用这些来综合回答问题:{question} """ prompt = ChatPromptTemplate.from_template(template) final_rag_chain = ( prompt | llm | StrOutputParser() ) final_rag_chain.invoke({"context" :context,"question" :question})
第8部分:退一步
论文:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplateexamples = [ { "input" : "Could the members of The Police perform lawful arrests?" , "output" : "what can the members of The Police do?" , }, { "input" : "Jan Sindel’s was born in what country?" , "output" : "what is Jan Sindel’s personal history?" , }, ] example_prompt = ChatPromptTemplate.from_messages( [ ("human" , "{input}" ), ("ai" , "{output}" ), ] ) few_shot_prompt = FewShotChatMessagePromptTemplate( example_prompt=example_prompt, examples=examples, ) prompt = ChatPromptTemplate.from_messages( [ ( "system" , """你是世界知识的专家。你的任务是退一步,将问题改写为更通用的退一步问题,这样更容易回答。以下是一些示例:""" , ), few_shot_prompt, ("user" , "{question}" ), ] )
1 2 3 generate_queries_step_back = prompt | ChatOpenAI(temperature=0 ) | StrOutputParser() question = "What is task decomposition for LLM agents?" generate_queries_step_back.invoke({"question" : question})
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 response_prompt_template = """你是世界知识的专家。我将向你提问。你的回答应该是全面的,并且如果相关,不应与以下上下文相矛盾。否则,如果它们不相关,请忽略它们。 # {normal_context} # {step_back_context} # 原始问题:{question} # 答案:""" response_prompt = ChatPromptTemplate.from_template(response_prompt_template) chain = ( { "normal_context" : RunnableLambda(lambda x: x["question" ]) | retriever, "step_back_context" : generate_queries_step_back | retriever, "question" : lambda x: x["question" ], } | response_prompt | ChatOpenAI(temperature=0 ) | StrOutputParser() ) chain.invoke({"question" : question})
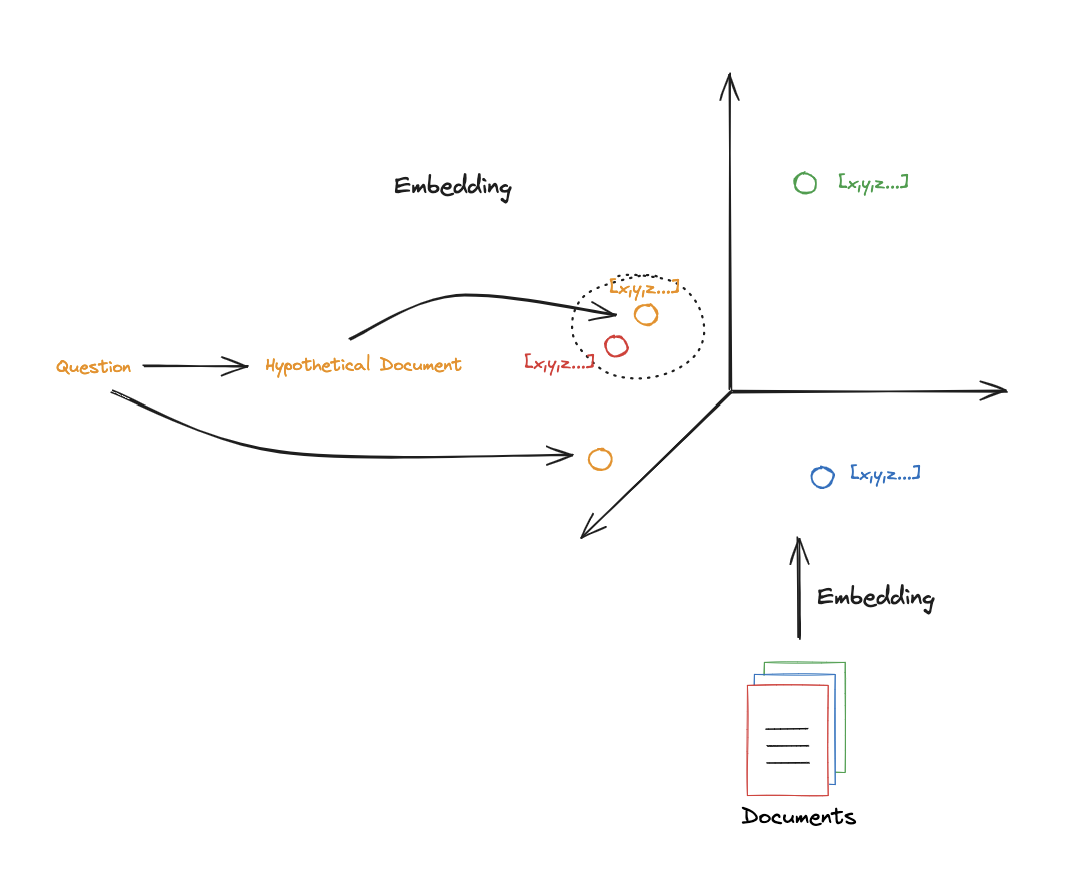
第9部分:HyDE
文档:
论文:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from langchain.prompts import ChatPromptTemplatetemplate = """请撰写一篇科学论文段落来回答问题 问题:{question} 段落:""" prompt_hyde = ChatPromptTemplate.from_template(template) from langchain_core.output_parsers import StrOutputParserfrom langchain_openai import ChatOpenAIgenerate_docs_for_retrieval = ( prompt_hyde | ChatOpenAI(temperature=0 ) | StrOutputParser() ) question = "What is task decomposition for LLM agents?" generate_docs_for_retrieval.invoke({"question" :question})
1 2 3 4 retrieval_chain = generate_docs_for_retrieval | retriever retireved_docs = retrieval_chain.invoke({"question" :question}) retireved_docs
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 template = """根据以下上下文回答问题: {context} 问题:{question} """ prompt = ChatPromptTemplate.from_template(template) final_rag_chain = ( prompt | llm | StrOutputParser() ) final_rag_chain.invoke({"context" :retireved_docs,"question" :question})