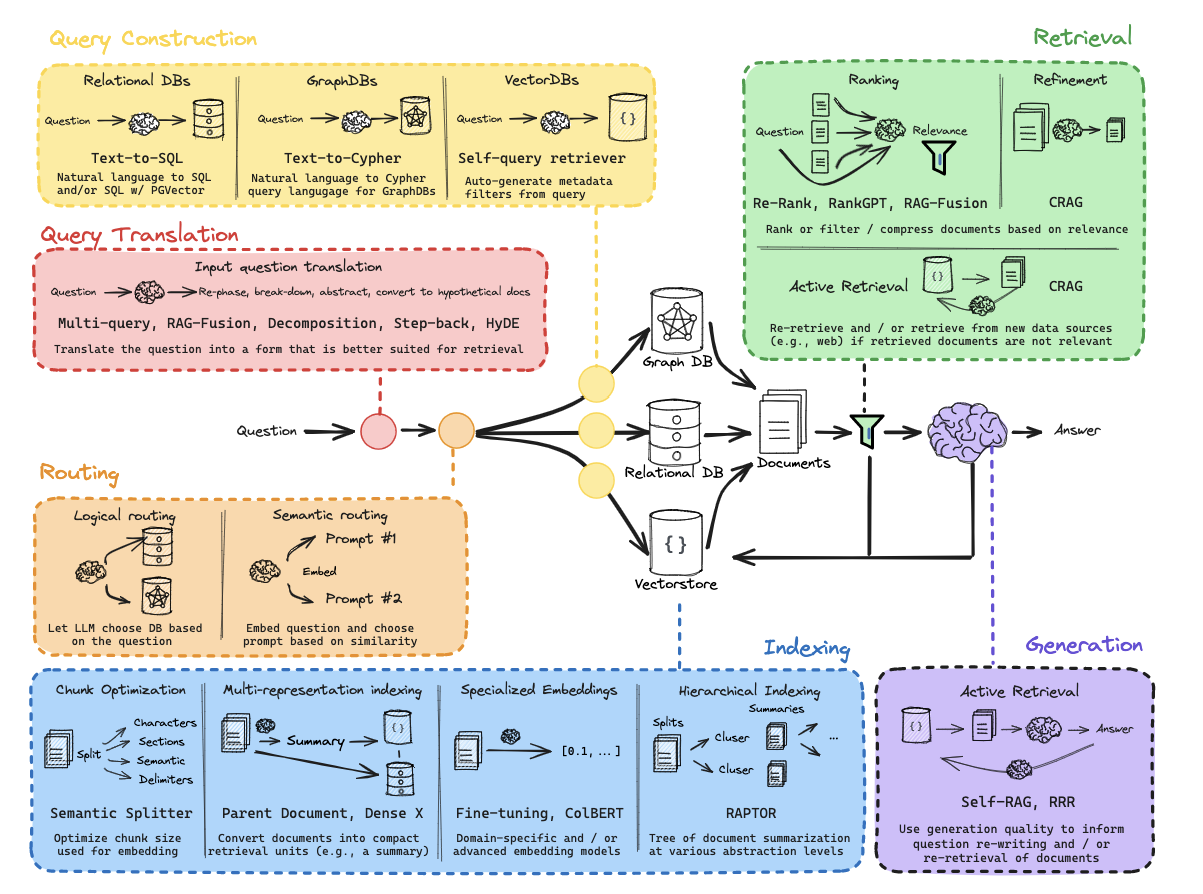
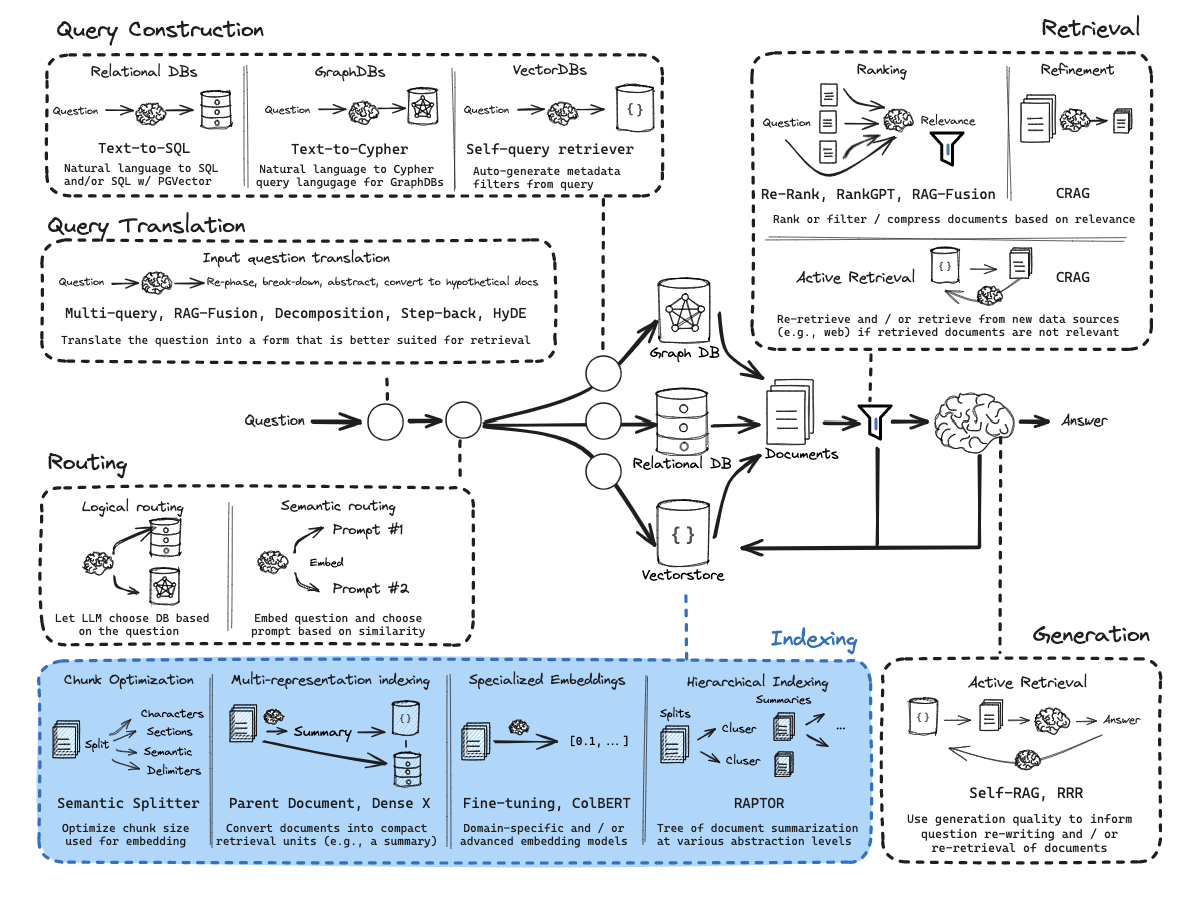
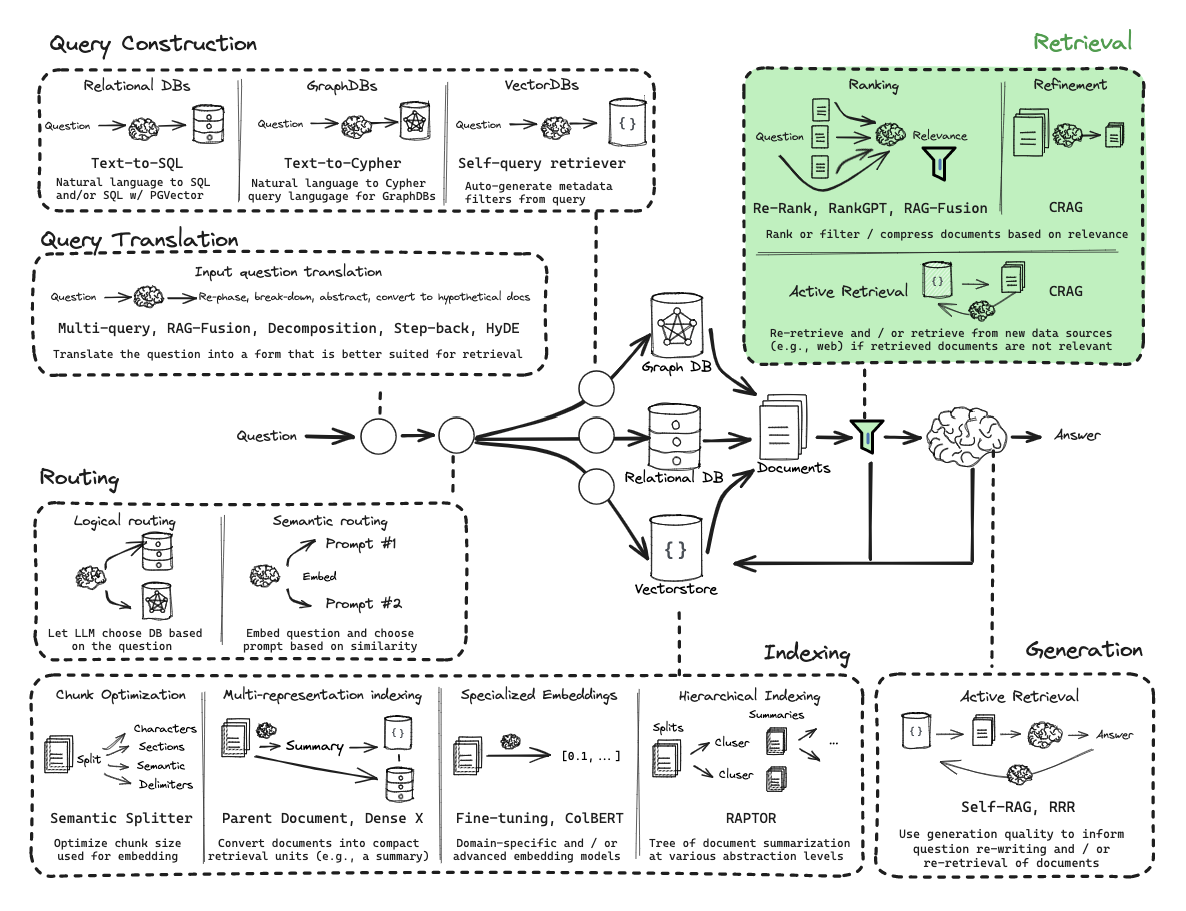
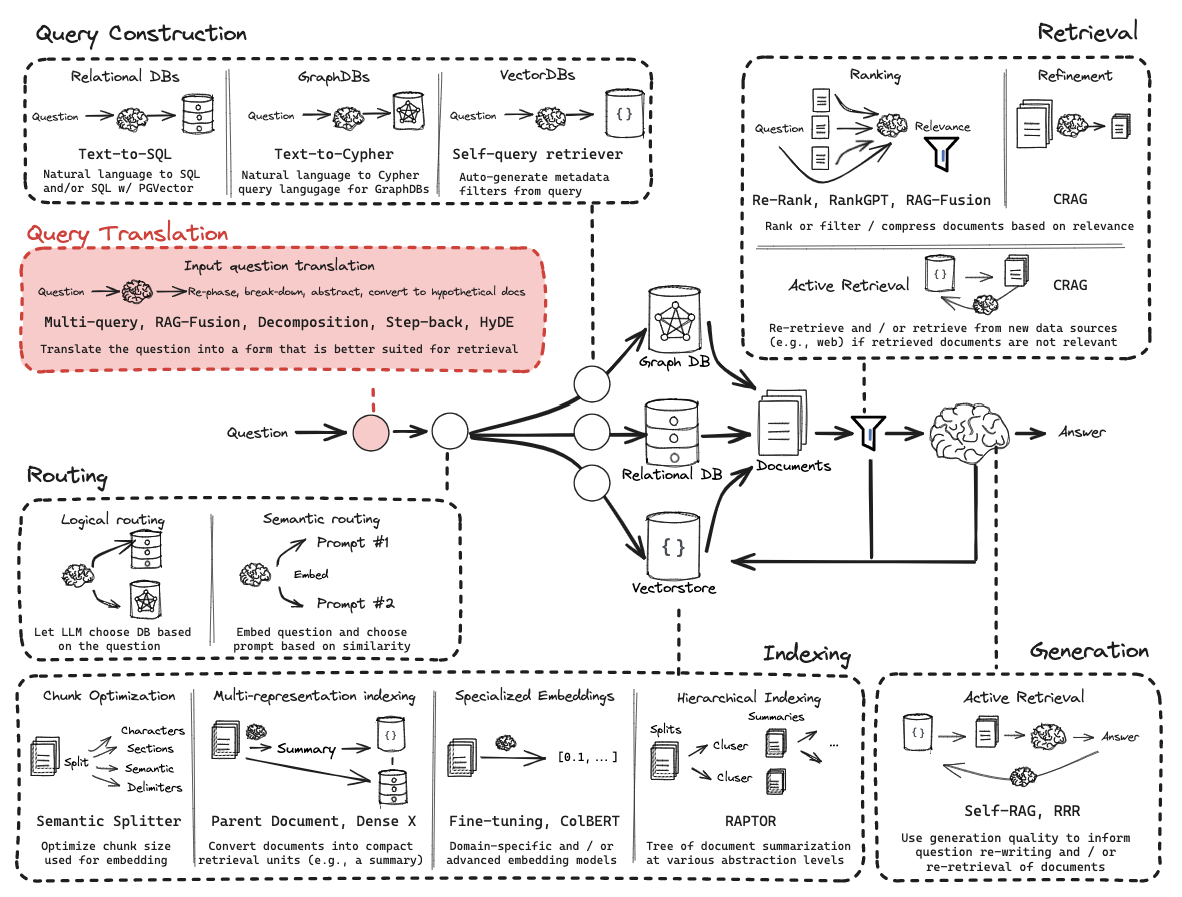
RAG从零开始构建教程:概述
这些教程将指导您从零开始构建RAG(检索增强生成)应用。
通过这些内容,您将对RAG的整体架构有更全面的理解,如下图所示:
环境配置
(1) 依赖包安装
1 ! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain
(2) LangSmith配置
详见:https://docs.smith.langchain.com/
1 2 3 4 import osos.environ['LANGCHAIN_TRACING_V2' ] = 'true' os.environ['LANGCHAIN_ENDPOINT' ] = 'https://api.smith.langchain.com' os.environ['LANGCHAIN_API_KEY' ] = <你的API密钥>
(3) API密钥配置
1 os.environ['OPENAI_API_KEY' ] = <你的OpenAI-API密钥>
第一部分:概述
RAG快速入门
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import bs4from langchain import hubfrom langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_community.vectorstores import Chromafrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthroughfrom langchain_openai import ChatOpenAI, OpenAIEmbeddingsloader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/" ,), bs_kwargs=dict ( parse_only=bs4.SoupStrainer( class_=("post-content" , "post-title" , "post-header" ) ) ), ) docs = loader.load() text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000 , chunk_overlap=200 ) splits = text_splitter.split_documents(docs) vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings()) retriever = vectorstore.as_retriever() prompt = hub.pull("rlm/rag-prompt" ) llm = ChatOpenAI(model_name="gpt-3.5-turbo" , temperature=0 ) def format_docs (docs ): return "\n\n" .join(doc.page_content for doc in docs) rag_chain = ( {"context" : retriever | format_docs, "question" : RunnablePassthrough()} | prompt | llm | StrOutputParser() ) rag_chain.invoke("什么是任务分解?" )
第二部分:索引
1 2 3 question = "我喜欢什么宠物?" document = "我最喜欢的宠物是猫。"
Token计数 考虑 约4个字符/token
1 2 3 4 5 6 7 8 9 import tiktokendef num_tokens_from_string (string: str , encoding_name: str ) -> int : """计算文本字符串中的token数量""" encoding = tiktoken.get_encoding(encoding_name) num_tokens = len (encoding.encode(string)) return num_tokens num_tokens_from_string(question, "cl100k_base" )
文本嵌入模型
1 2 3 4 5 from langchain_openai import OpenAIEmbeddingsembd = OpenAIEmbeddings() query_result = embd.embed_query(question) document_result = embd.embed_query(document) len (query_result)
对于OpenAI嵌入,推荐使用余弦相似度 (1表示完全相同)。
1 2 3 4 5 6 7 8 9 10 import numpy as npdef cosine_similarity (vec1, vec2 ): dot_product = np.dot(vec1, vec2) norm_vec1 = np.linalg.norm(vec1) norm_vec2 = np.linalg.norm(vec2) return dot_product / (norm_vec1 * norm_vec2) similarity = cosine_similarity(query_result, document_result) print ("余弦相似度:" , similarity)
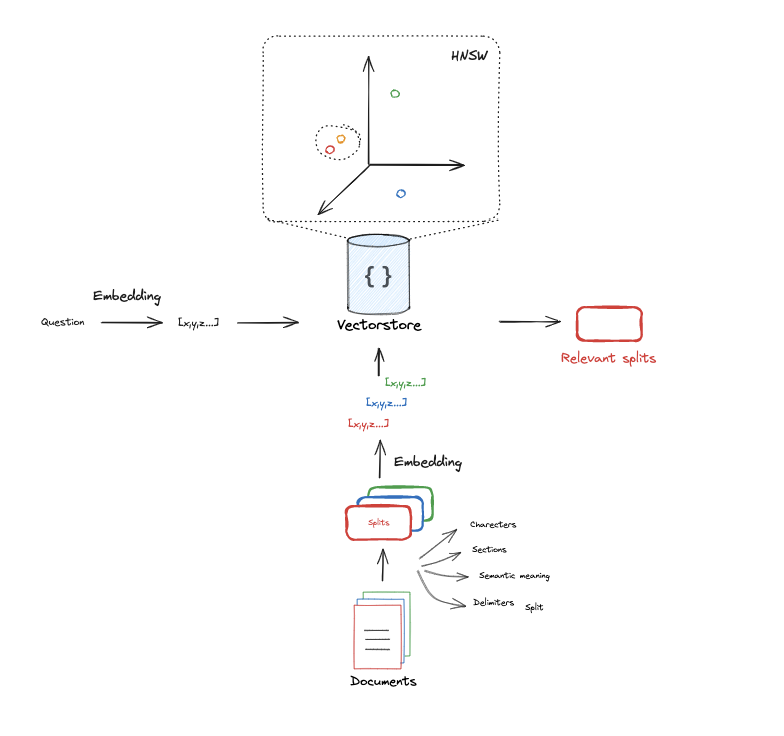
文档加载器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import bs4from langchain_community.document_loaders import WebBaseLoaderloader = WebBaseLoader( web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/" ,), bs_kwargs=dict ( parse_only=bs4.SoupStrainer( class_=("post-content" , "post-title" , "post-header" ) ) ), ) blog_docs = loader.load()
文本分割器
这是推荐用于通用文本的分割器。它通过一系列字符参数化。它会按顺序尝试在这些字符上进行分割,直到块的大小足够小。默认字符列表是["\n\n", “\n”, " ", “”]。这样做的效果是尽可能保持所有段落(然后是句子,再然后是单词)在一起,因为这些通常是语义关联最强的文本片段。
1 2 3 4 5 6 7 8 from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( chunk_size=300 , chunk_overlap=50 ) splits = text_splitter.split_documents(blog_docs)
向量存储
1 2 3 4 5 6 7 from langchain_openai import OpenAIEmbeddingsfrom langchain_community.vectorstores import Chromavectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings()) retriever = vectorstore.as_retriever()
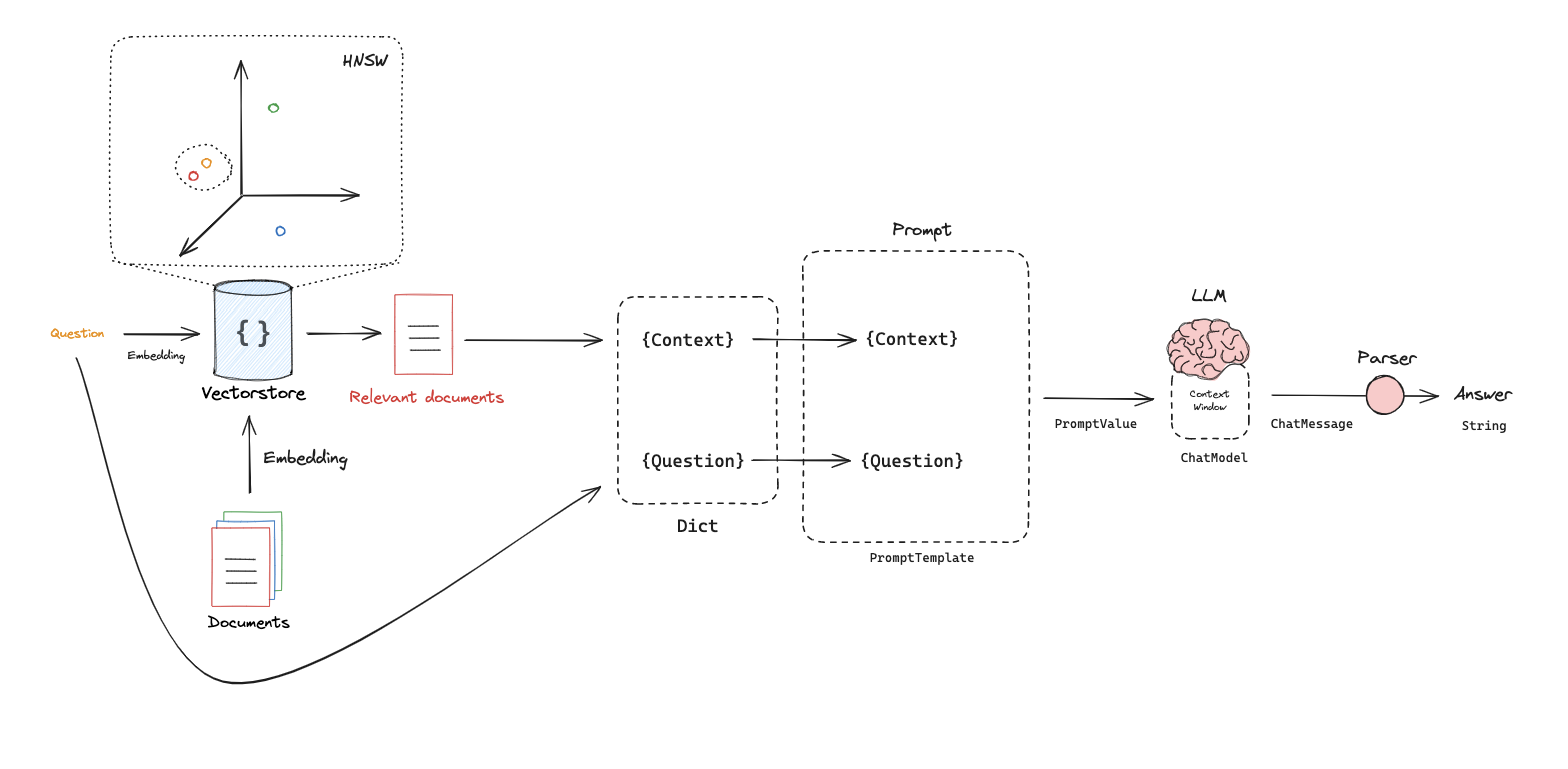
第三部分:检索
1 2 3 4 5 6 7 from langchain_openai import OpenAIEmbeddingsfrom langchain_community.vectorstores import Chromavectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings()) retriever = vectorstore.as_retriever(search_kwargs={"k" : 1 })
1 docs = retriever.get_relevant_documents("什么是任务分解?" )
第四部分:生成
1 2 3 4 5 6 7 8 9 10 11 12 from langchain_openai import ChatOpenAIfrom langchain.prompts import ChatPromptTemplatetemplate = """仅基于以下上下文回答问题: {context} 问题:{question} """ prompt = ChatPromptTemplate.from_template(template) prompt
1 2 llm = ChatOpenAI(model_name="gpt-3.5-turbo" , temperature=0 )
1 2 chain.invoke({"context" :docs,"question" :"什么是任务分解?" })
1 2 from langchain import hubprompt_hub_rag = hub.pull("rlm/rag-prompt" )
RAG chains文档
1 2 3 4 5 6 7 8 9 10 11 from langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthroughrag_chain = ( {"context" : retriever, "question" : RunnablePassthrough()} | prompt | llm | StrOutputParser() ) rag_chain.invoke("什么是任务分解?" )