
书生·浦语大模型实战营(四):XTuner 微调 LLM:1.8B、多模态、Agent
视频:https://www.bilibili.com/video/BV15m421j78d/?vd_source=3194af3e77968cb10b1d50711d07106a
文档:https://github.com/InternLM/Tutorial/blob/camp2/xtuner/readme.md
笔记
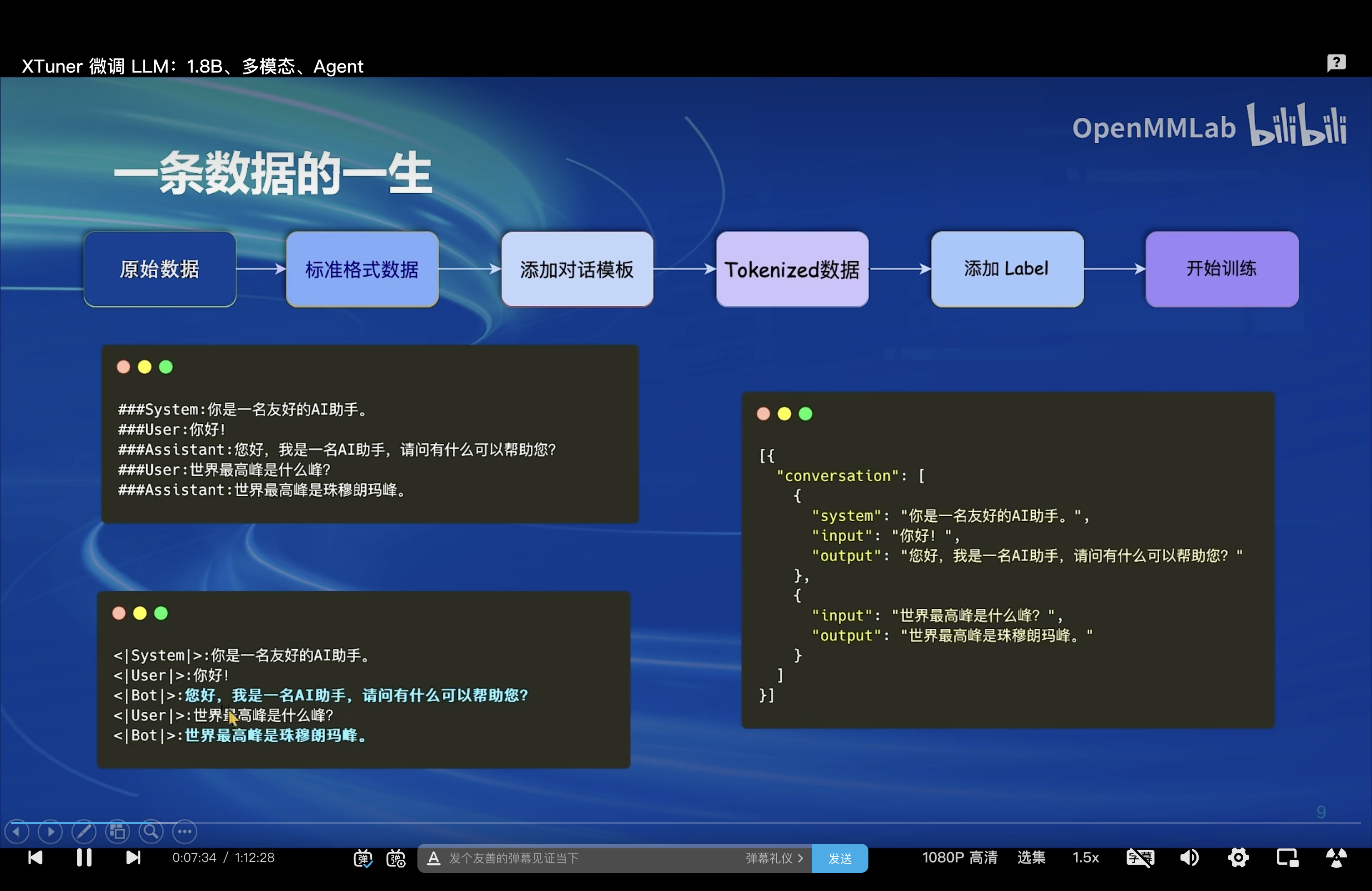
两种Finetune范式
LLM 的下游应用中,增量预训练和指令跟随是经常会用到两种的微调模式
增量预训练微调
使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识训练数据:文章、书籍、代码等
指令跟随微调
使用场景:让模型学会对话模板,根据人类指令进行对话训练数据:高质量的对话、问答数据

XTurn
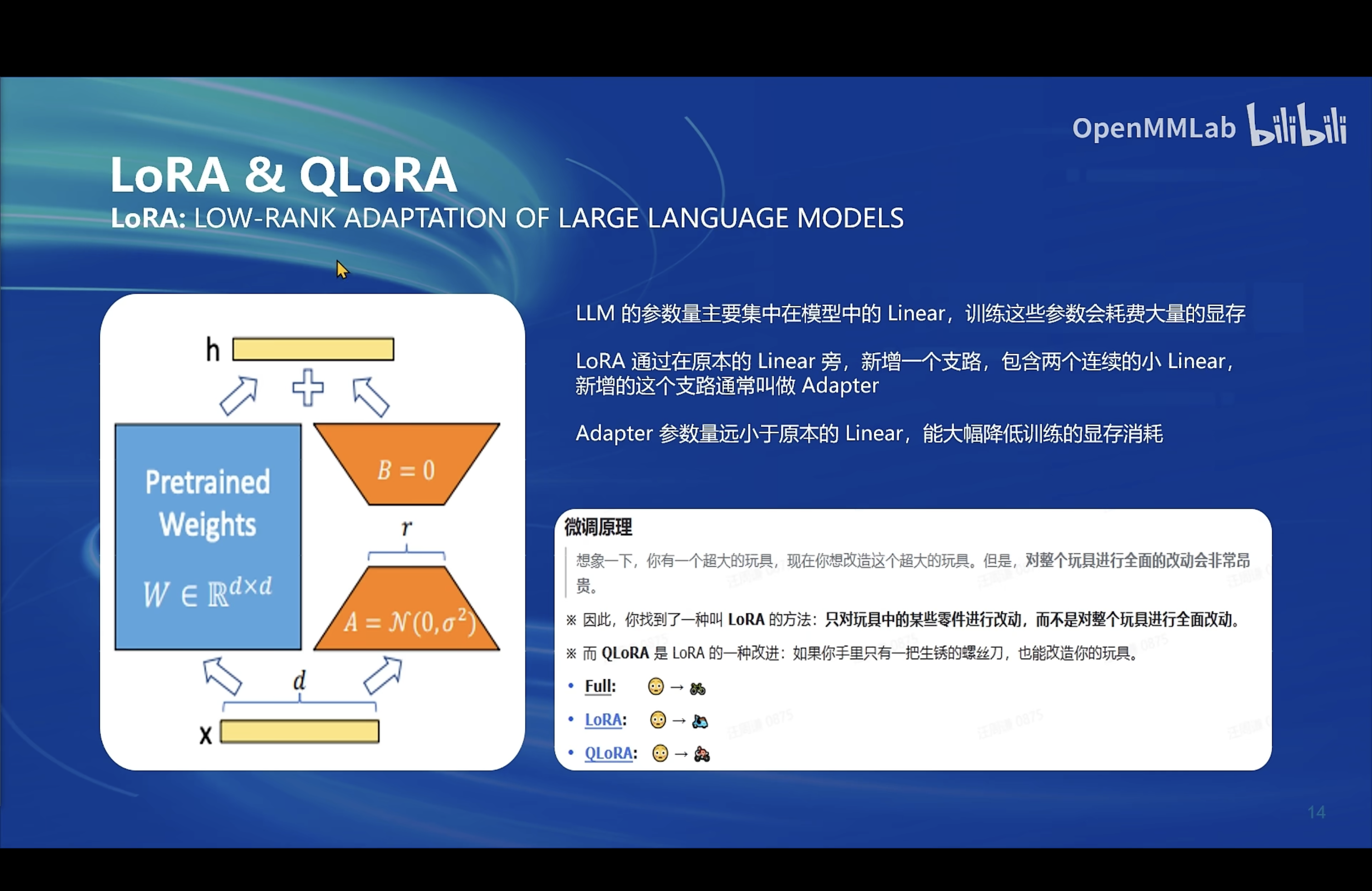
LoRA & QLoRA
LoRA: Low-Rank Adaptation of Large Language Models
- LLM 的参数量主要集中在模型中的 Linear, 训练这些参数会耗费大量的显存
- LoRA 通过在原本的 Linear 旁,新增一个支路,包含两个连续的小 linear,新增的这个支路通常叫做 Adapter
- Adapter 参数量远小于原本的 Linear,能大幅降低训练的显存消耗
QLoRA: Quantized LLMs with Low-Rank Adapters
- 4位NormalFloat量化:这是一种改进量化的方法,确保每个量化仓中有相同数量的值,这避免了计算问题和异常值的错误。
- 双量化:对量化常量再次量化以节省额外内存的过程。
- 统一内存分页:它依赖于NVIDIA统一内存管理,自动处理CPU和GPU之间的页到页传输,它可以保证GPU处理无错,特别是在GPU可能耗尽内存的情况下。
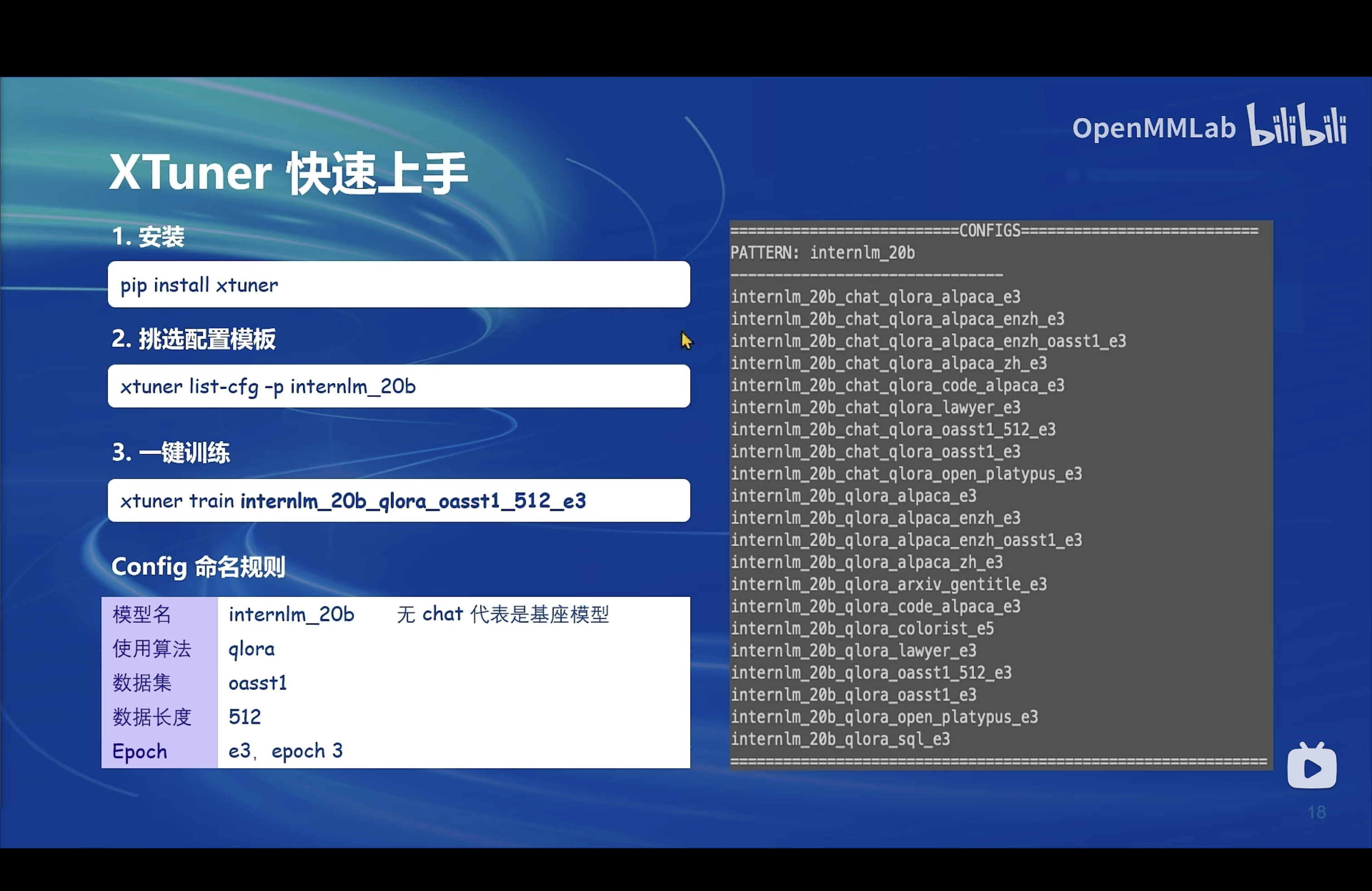
XTuner 一个大语言模型&多模态模型微调工具箱。由 MMRazor 和 MMDeploy 联合开发。
- 🤓 傻瓜化: 以 配置文件 的形式封装了大部分微调场景,0基础的非专业人员也能一键开始微调。
- 🍃 轻量级: 对于 7B 参数量的LLM,微调所需的最小显存仅为 8GB : 消费级显卡✅,colab✅

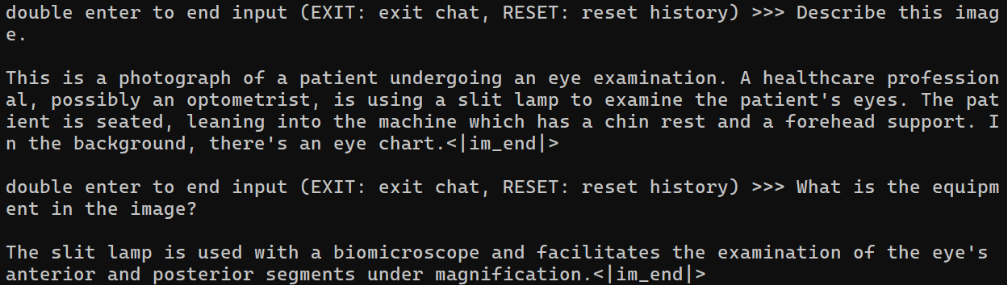
MS-Agent 数据集
这个数据集比较有意思,能够赋予大模型调用api的agent能力,原理:
- 模型的回复中会包括插件调用代码和执行代码
- 调用代码是 LLM 生成的
- 执行代码是需要调用服务来生成结果的,这里我们需要给
xtuner chat增加-lagent参数来实现
作业

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 fanfer 🥰!
相关推荐

评论