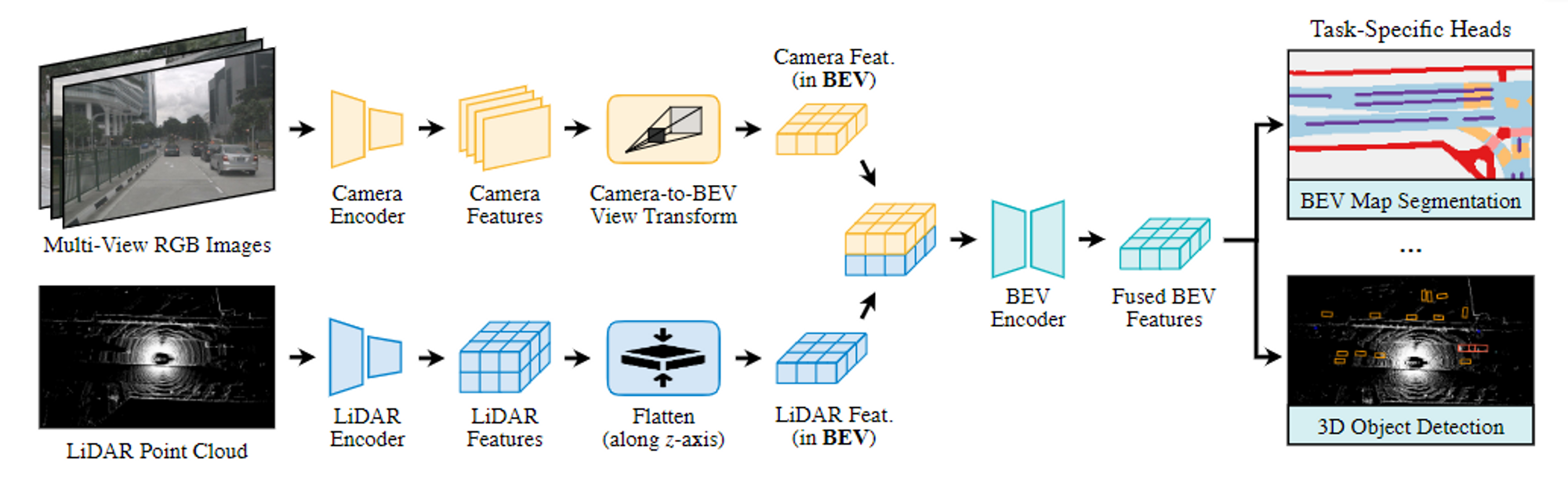
VoxPoser
VoxPoser:使用语言模型的可组合三维价值地图进行机器人操纵
author:Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li , Jiajun Wu, Li Fei-Fei
Abstract
大型语言模型(LLMs)显示出具有可操作知识的丰富性,可以通过推理和规划的形式提取用于机器人操纵的知识。尽管取得了进展,但大多数仍然依赖预定义的运动原语来进行与环境的物理交互,这仍然是一个主要瓶颈。在这项工作中,我们旨在合成机器人轨迹,即一系列密集的6自由度末端执行器路径点,用于各种操纵任务,并给定开放式指令和开放式对象。我们首先观察到LLMs在根据自由形式语言指令推断能力和约束方面表现出色。更重要的是,通过利用它们编写代码的能力,它们可以与视觉-语言模型(VLM)交互以组合3D价值地图将知识落实到代理者所观测到空间中。然后,在基于模型的规划框架中使用组合后的价值地图来零样本综合闭环机器人轨迹,并对动态扰动具有鲁棒性。我们进一步演示了所提出框架如何从在线经验中受益,并有效学习涉及接触丰富交互场景下的动力学模型。我们在模拟和真实机器人环境中对所提出方法进行了大规模研究,展示了能够执行各种以自由形式自然语言指定的日常操纵任务的能力。视频和代码请访问voxposer.github.io。
关键词:操纵,大型语言模型,基于模型的规划

Instruction
语言是人类用来提炼和传达对世界的知识和经验的一种压缩媒介。大型语言模型(LLMs)已经成为捕捉这种抽象、通过语言空间投影来代表世界的一种有前途的方法。尽管这些模型被认为能够以文本形式内化可概括的知识,但如何利用它们来使具体agent(如机器人)在现实世界中实际行动仍是一个问题。
我们研究的问题是如何将抽象的语言指令(例如“布置桌子”)转化为机器人动作。以往的工作利用词汇分析来解析指令,而最近则使用语言模型将指令分解为一系列文本步骤。然而,为了使机器人与环境进行物理互动,现有方法通常依赖于一系列预定义的动作原语(即技能),这些原语可能由LLM或规划器调用,而依赖于单独技能获取通常被认为是系统的一个主要瓶颈,因为缺乏大规模的机器人数据。那么问题来了:我们如何利用LLM内化的知识,甚至在细粒度的动作层面,为机器人提供帮助,而无需进行繁琐的数据收集或为每个单独的原语手动设计?
在解决这个挑战时,我们首先注意到LLM直接以文本输出控制动作是不切实际的,因为这些控制动作通常由高频控制信号在高维空间中驱动。然而,我们发现LLM擅长推断语言条件下的可用性和限制,并且通过利用它们的编写代码能力,它们可以组成密集的3D体素地图,将这些知识植入视觉空间,通过协调感知调用(例如通过CLIP或开放词汇检测器)和数组操作(例如通过NumPy)。
例如,给定一个指令“打开顶部抽屉并注意花瓶”,LLM可以被提示推断:
1)应该抓住顶部抽屉的把手;
2)把手需要向外平移;
3)机器人应该远离花瓶。
通过生成Python代码调用感知API,LLM可以获得相关对象或部件的空间-几何信息,然后操纵3D体素,在观察空间中的相关位置规定奖励或成本(例如,把手区域被赋予高值,而花瓶周围被赋予低值)。最后,组成的价值地图可以作为运动规划器的目标函数,直接合成实现给定指令的机器人轨迹,无需为每个任务或LLM提供额外的训练数据。图1中展示了一个示意图和我们考虑的一些任务。
我们将这种方法称为VOXPOSER,它从LLMs中提取可供性和约束,以在观察空间中组合3D价值地图,用于指导机器人的交互。与通常依赖数量有限或变化有限的机器人数据不同,该方法利用LLMs进行开放世界推理,并利用VLMs进行可泛化的视觉基础定位,在基于模型的规划框架中直接实现物理机器人动作。我们展示了其对各种日常操作任务具有零样本泛化能力,包括使用开放集对象的开放集指令。我们进一步展示了VoxPoser如何通过有限在线交互来高效学习涉及接触丰富交互的动力学模型。
Method
3.1首先提供了VoxPoser的优化问题表述
3.2然后我们描述了如何将VoxPoser用作通用的零样本框架,将语言指令映射到3D value map
3.3我们展示了如何闭环合成机器人操作的轨迹
3.4虽然是零样本学习,但我们展示了VoxPoser如何从在线交互中学习以高效解决富有接触性质的任务。
3.2 生成3D Map
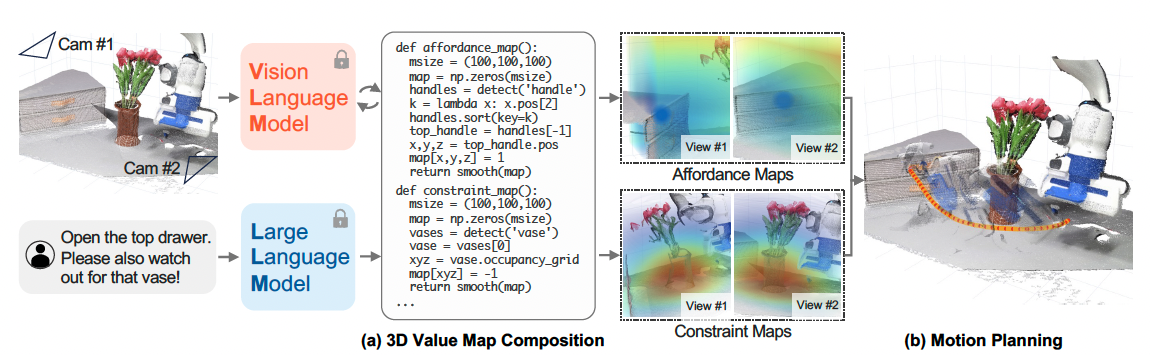
我们提供了一个关键观察结果,即大量任务可以通过机器人观测空间中的体素值图V ∈ Rw×h×d来描述,该图引导场景中“感兴趣实体”的运动,例如机器人末端执行器、物体或物体部分。
例如,考虑任务“打开顶层抽屉”及其第一个子任务“抓住顶部抽屉手柄”(由LLMs推断)在图2中。 “感兴趣的实体”是机器人末端执行器,并且体素值映射应反映对抽屉手柄的吸引力。通过进一步命令“小心花瓶”,地图也可以更新以反映对花瓶的排斥力。
值得注意的是,我们观察到大型语言模型通过在互联网规模的数据上进行预训练,不仅能够识别“感兴趣的实体”,还能够编写Python程序来准确反映任务指令。具体而言,在代码中给出指令作为注释时,可以提示LLMs执行以下操作:1)调用感知API(调用视觉语言模型(VLM),如开放词汇检测器[13-15])获取相关对象的空间几何信息;2)生成NumPy操作以操纵3D数组;3)在相关位置处指定精确值。我们将这种方法称为VOXPOSER。具体而言,我们旨在通过提示LLM并通过Python解释器执行代码来获得一个体素值图Vti = VoxPoser(ot, ℓi),其中ot是时间t处的RGB-D观察结果,ℓi是当前指令。此外,由于V通常是稀疏的,我们通过平滑操作使体素图变得密集化,因为它们鼓励运动规划者优化更平滑的轨迹。
附加轨迹参数化。上述的VoxPoser公式使用LLMs来组合V:N3 → R,将离散坐标映射到实值“成本”,我们可以用它来优化仅由位置项组成的路径。为了扩展到SE(3)姿态,我们还可以使用LLMs在与任务目标相关的坐标处组合旋转图像Vr:N3 → SO(3)(例如,“末端执行器应该面向手柄支撑法线”)。同样地,我们进一步组合夹爪图像Vg:N3 → {0, 1}以控制夹爪开闭和速度图像Vv:N3 → R以指定目标速度。请注意,虽然这些附加的轨迹参数化没有映射到实值“成本”,但它们也可以在优化过程中进行因子分解(方程1)以对轨迹进行参数化。
LLMs和提示。
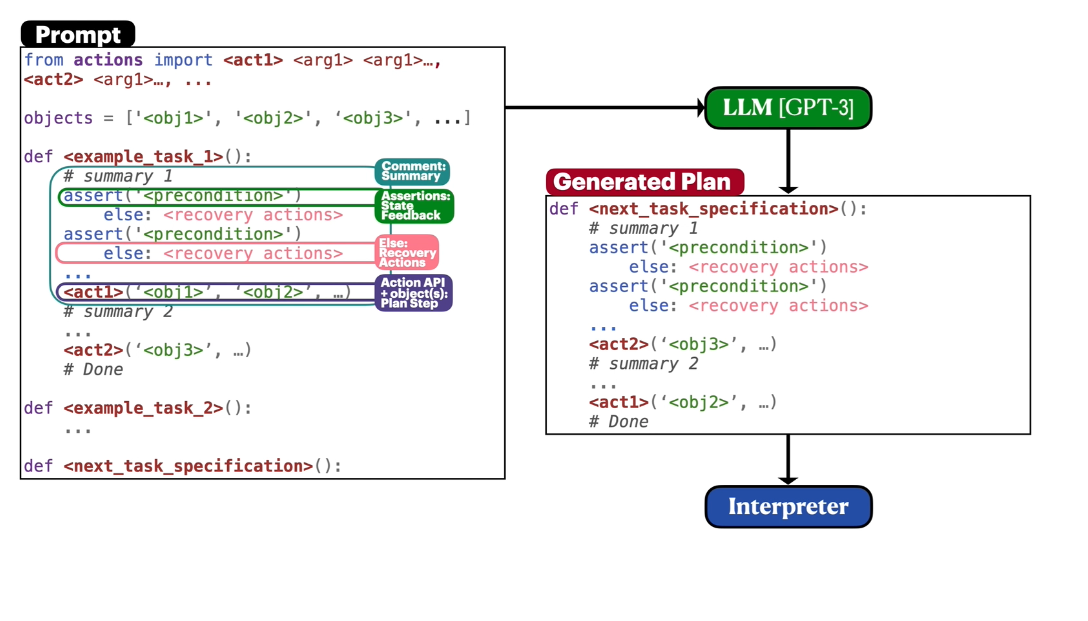
我们遵循Liang等人的提示结构[75],该结构通过递归调用其自动生成的代码来调用LLMs,其中每个语言模型程序(LMP)负责唯一的功能(例如处理感知呼叫)。我们使用OpenAI API中的GPT-4 [2]。对于每个LMP,我们将5-20个示例查询和相应的响应作为提示的一部分包含在内。图2中可以找到一个示例(为了清晰起见进行了简化)。完整的提示请参见附录。
补充
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as
policies: Language model programs for embodied control. arXiv preprint arXiv:2209.07753,
2022.

编写代码的LLMs可以重新用于编写机器人策略代码,给定自然语言命令。具体而言,策略代码可以表达处理感知输出(例如来自物体检测器[2]、[3])和参数化控制原始API的函数或反馈循环。当以几个示例语言命令(格式为注释)作为输入,并通过少量提示提供相应的策略代码时,LLMs可以接受新命令并自主地重新组合API调用以生成新的策略代码。通过链接经典逻辑结构和引用第三方库(例如NumPy、Shapely)进行算术运算,在此方式下使用的LLMs可以编写机器人策略:展示空间几何推理、泛化到新指令,并根据上下文(即行为常识)对模糊描述(“更快”)提供精确值(例如速度)。
VLMs和感知。
给定LLMs的对象/部分查询,我们首先调用开放词汇检测器OWL-ViT [15]来获取一个边界框,然后将其输入Segment Anything [118]以获取一个掩码,并最终使用视频跟踪器XMEM [119]跟踪该掩码。使用RGB-D观察重建对象/部分点云。
价值地图组合。
我们定义以下类型的价值地图:可行性、避免、末端执行器速度、末端执行器旋转和夹爪动作。每种类型使用不同的LMP,它接收指令并输出形状为(100, 100, 100, k)的体素地图,其中k对于每个价值地图都不同(例如,对于可行性和避免来说k = 1表示成本,而对于旋转来说k = 4表示SO(3))。我们将欧几里得距离变换应用于可行性地图,并对避免地图应用高斯滤波器。在价值地图LMP之上,我们定义了两个高级LMP来协调它们的行为:规划者以用户指令L作为输入(例如,“打开抽屉”),并输出一系列子任务ℓ1:N;组合者接收子任务ℓi并使用详细语言参数化调用相关的价值地图LMPs。
Related Works
端到端成本预测器通过监督学习优化以将自然语言指令映射到2D成本地图上,在碰撞自由方式下引导运动规划生成首选轨迹。
P. Sharma, B. Sundaralingam, V. Blukis, C. Paxton, T. Hermans, A. Torralba, J. Andreas,
and D. Fox. Correcting robot plans with natural language feedback. arXiv preprint
arXiv:2204.05186, 2022.
为了使语言模型能够感知物理环境,可以提供场景的文本描述[39、11、59]或感知API [75]
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch,
Y. Chebotar, P. Sermanet, N. Brown, T. Jackson, L. Luu, S. Levine, K. Hausman, and
B. Ichter. Inner monologue: Embodied reasoning through planning with language models. In
arXiv preprint arXiv:2207.05608, 2022
需要利用视觉方法,生成结构化的Scene文本,但是他的文本仅包含类别
I. Singh, V. Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and
A. Garg. Progprompt: Generating situated robot task plans using large language models.
arXiv preprint arXiv:2209.11302, 2022. ICRA2023
我们提出了一个编程式LLM提示结构,使其能够在具体环境、机器人能力和任务之间实现功能性计划生成。我们主要思路是用类似程序的方式向LLM提示可用行动和物体在环境中以及可执行示例程序。
A. Zeng, A. Wong, S. Welker, K. Choromanski, F. Tombari, A. Purohit, M. Ryoo, V. Sindhwani,
J. Lee, V. Vanhoucke, et al. Socratic models: Composing zero-shot multimodal reasoning
with language. arXiv preprint arXiv:2204.00598, 2022.
或者采用多模态输入
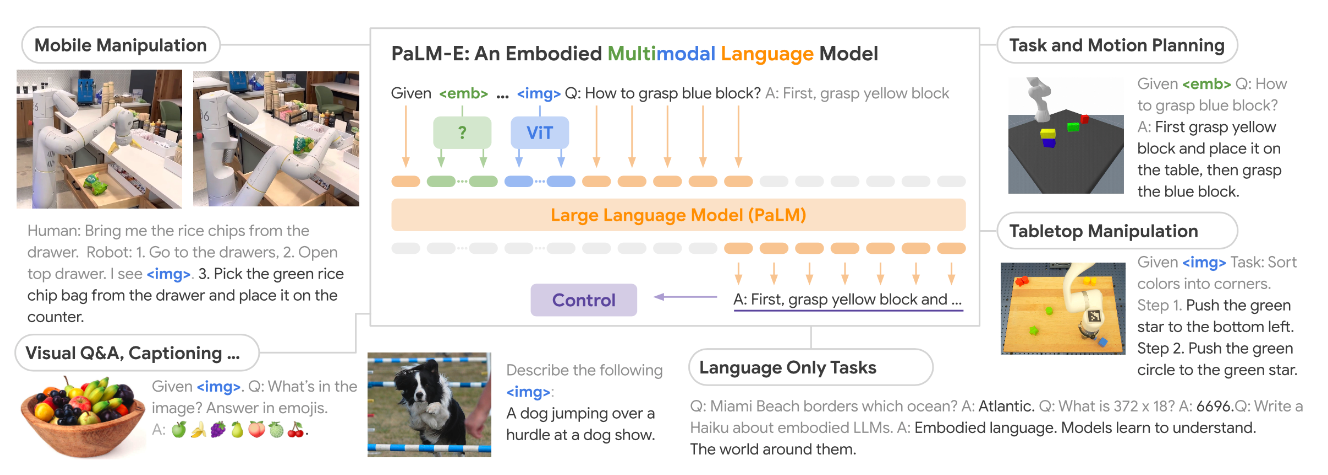
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson,
Q. Vuong, T. Yu, et al. Palm-e: An embodied multimodal language model. arXiv preprint
arXiv:2303.03378, 2023.
提出了具有体验性的语言模型,将真实世界的连续传感器模态直接融入到语言模型中,并建立单词和感知之间的联系。我们所提出的体验性语言模型输入是多模式句子,交替包含视觉、连续状态估计和文本输入编码。(训练了一个526B参数大小的模型)
OpenAI. Gpt-4 technical report. arXiv, 2023.