VoxelNet
Abstract
本文消除了对3D点云的手动特征工程的需要,提出了VoxelNet,将特征提取和bounding box统一到单个阶段、端到端的可训练深度网络中。
VoxelNet将点云划分为等距的3D体素,通过引入提速特征编码(VFE)层将每个体素内的一组点转化为统一的特征表示。
Introduction
针对现在对于3D点云还需要手动特征工程的需求,我们提出了VoxelNet:这是一个通用的3D检测框架,它以端到端的方式同时从点云中学习有区别的特征表示,并预测精确的3D边界框
主要贡献:
- 我们提出了一种新的端到端可训练的深度架构,用于基于点云的三维检测VoxelNet,直接在稀疏的三维点上操作,避免了人工特征工程引入的信息瓶颈。
- 我们提出了一种有效的方法来实现体素网,它既受益于稀疏点结构,又受益于体素网格上的高效并行处理。
- 我们在KITTI benchmark上进行实验,结果表明,在基于激光雷达的汽车、行人和自行车检测基准中,VoxelNet产生了SOTA结果
Methodology
分为三个功能模块:特征学习网络、卷积神经网络、区域提取网络
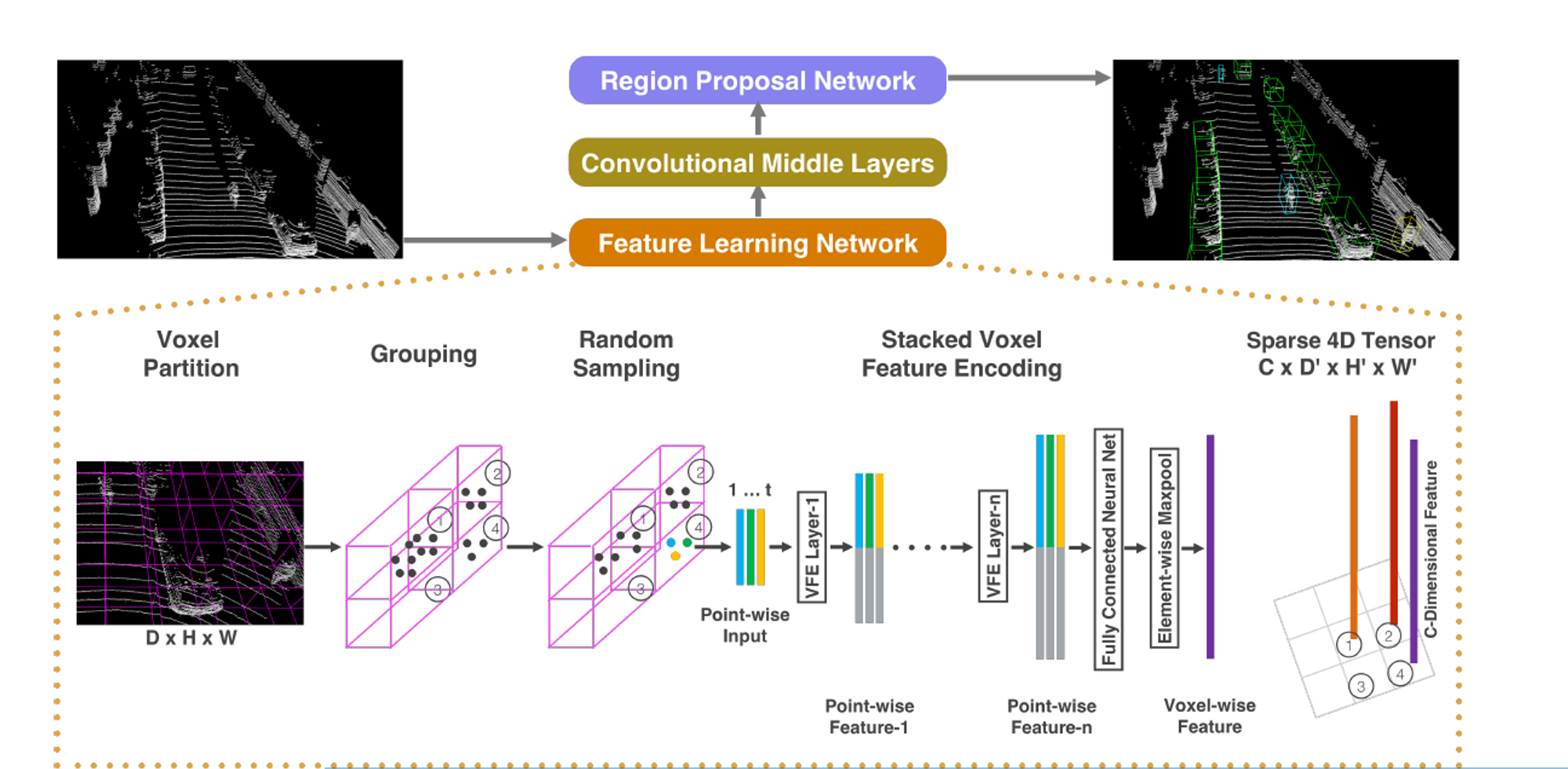
特征学习网络将原始点云作为输入,将空间划分为体素,并将每个体素内的点转换为表征形状信息的矢量表示。这个空间被表示为一个稀疏的4D张量。卷积中间层处理4D张量以聚集空间上下文。最后,RPN生成3D检测
Feature Learning Network
-
划分体素,将整个空间划分成大小相同的Voxel
-
分组,将激光雷达点分配到相应的Voxel中,由于雷达的稀疏和不均匀采样,不同的体素包含数量可变的激光雷达点。
-
随机采样。从包含超过T个点的体素中随机抽取固定数量T的点。这个策略有两个目的:(1)节省计算资源 (2)减少了体素之间点的数量的不均衡,减少了采样偏差,增加了更多的变化。
-
体素特征编码 (stacked Voxel feature encoding)
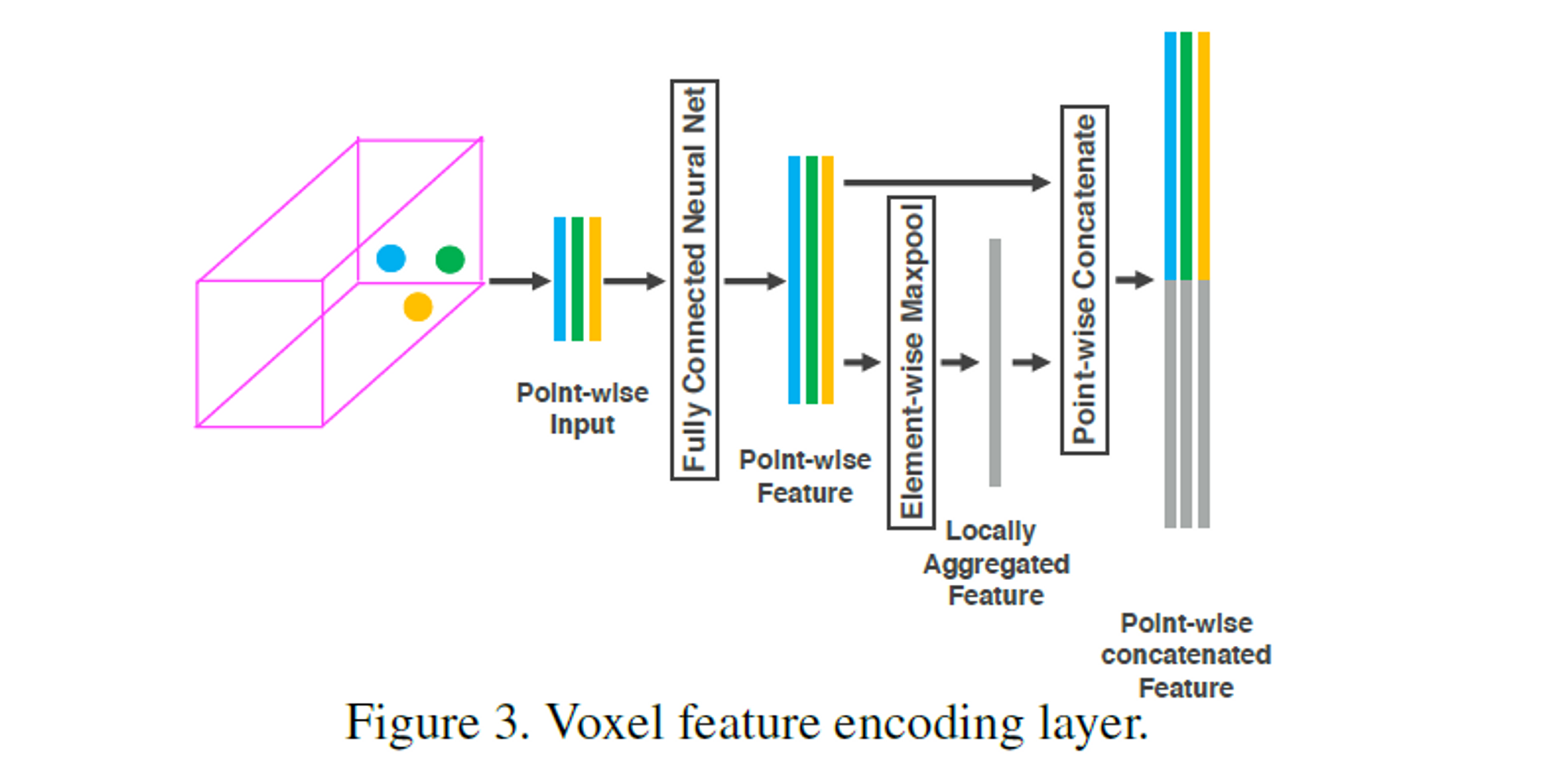

上图中Voxel有3个点云数据。作者先用一个FCN层(印象中FCN指的是全卷积层,但这里指的是全连接层)提取这3个点云数据的特征,获得3个Point-wise Feature。
因为这个操作是逐点运算的,并没有引入点与点之间的关系,也就是local feature。作者在此基础上引入Element-wise maxpool,获得Locally Aggregated Feature。Locally Aggregated Feature反应了这些点的一个局部关系。
作者将Point-wise Feature和Locally Aggregated Feature进行了简单的堆叠融合,作为下一个VFE层的输入。
这样连续堆叠几次VFE层后,就获得更丰富的特征表示。最后,使用一个Element-wise maxpool获得最后的一个Voxel-wise Feature。也就是第一张图片中的这个部分
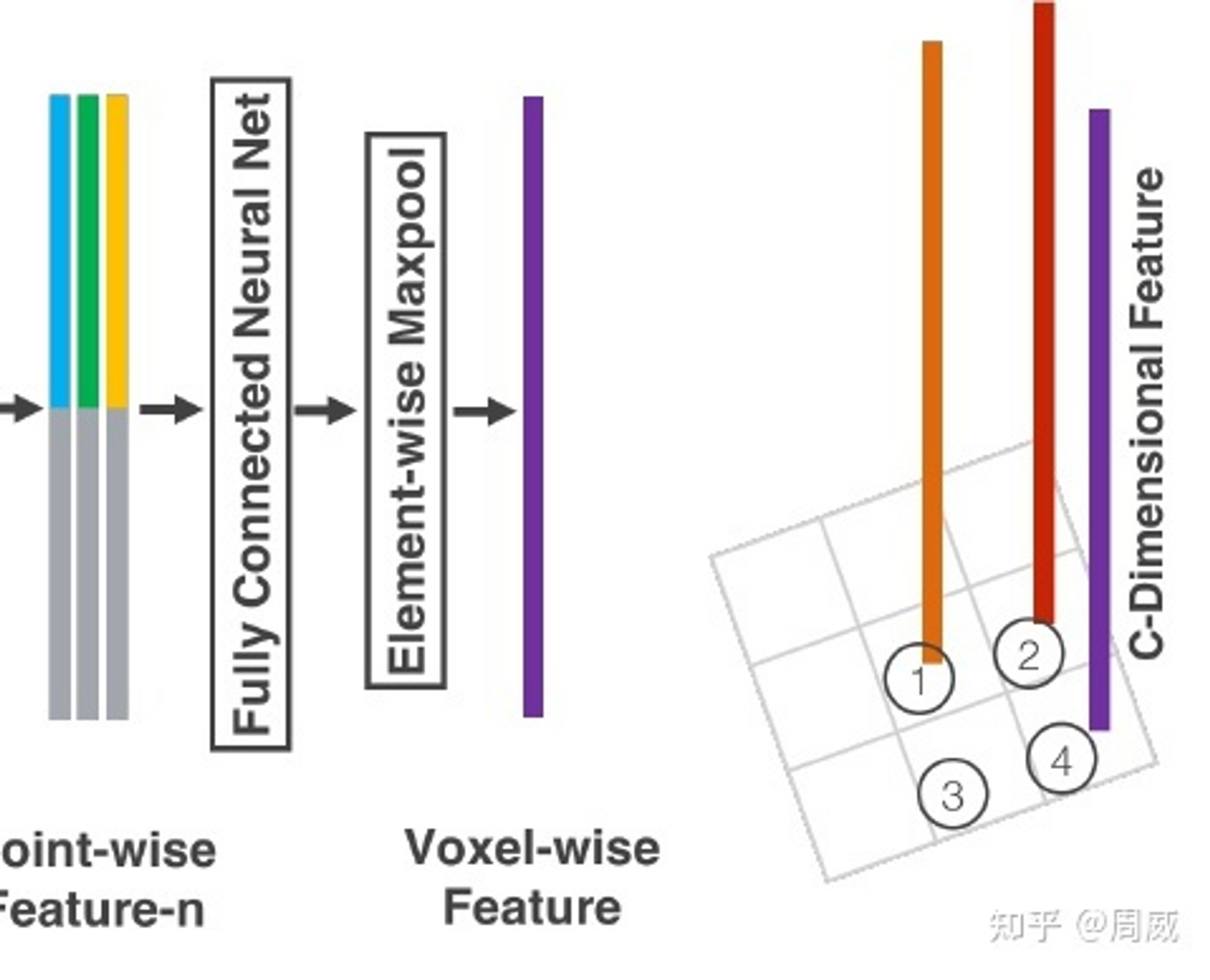
用表示第i个VFE层,该层将维度cin的输入特征转换为维度cout的输出特征。线性层学习一个大小为cin *(cout/2)的矩阵,逐点拼接产生维数为cout的输出。
-
Sparse Tensor Representation:仅仅处理非空体素,获得了体素特征列表,是一个4D 的稀疏张量 由于大量的是空体素,因此大大减少了内存使用和计算成本
补充Mask
由于体素具有数量可变的点,因此通过mask的方式,进行处理后再交给gpu运算。
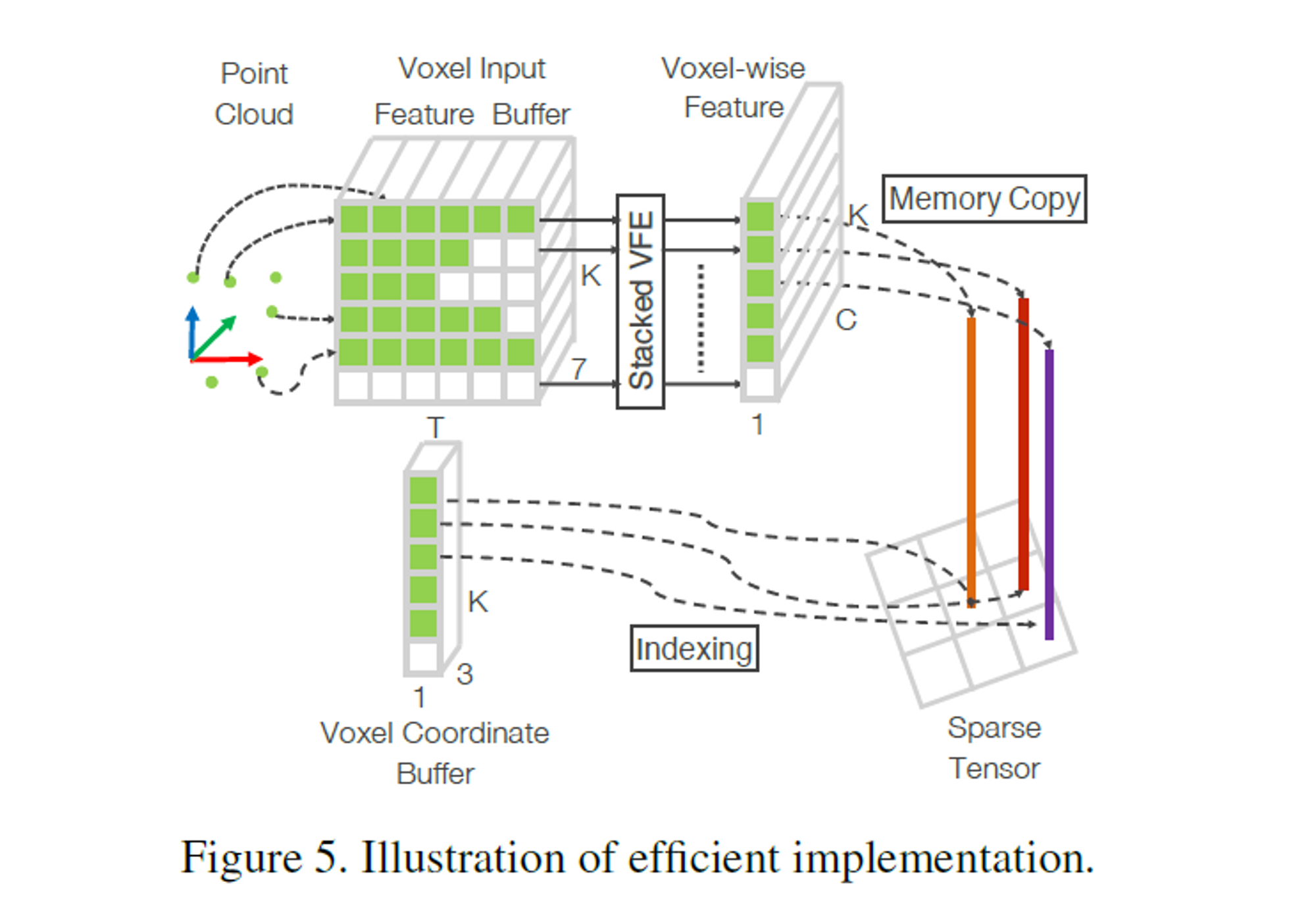
首先初始化一个KT7的张量来存储体素输入特征,K是非空体素的最大数量,T是每个体素的最大的点数,7是每个点的输入编码的维度。
注意再完成VFE的连接后,将空点所对应的特征重置为0.
Convolutional Middle Layers
点云数据通过特征学习网络后可以被表示成一个稀疏的4D张量,维度记做(C,D′,H′,W′) 。其中, C 为Voxel-wise Feature的向量维度(也就是图3中向量的高度), D′,H′,W′ 为空间的深度、高度和宽度(单位为Voxel数量)。
因为张量是4维的,作者就用3D卷积来构建这个中间卷积层。目的显然是为了扩大感受野,增加更多的信息描述。
Region Proposal Network
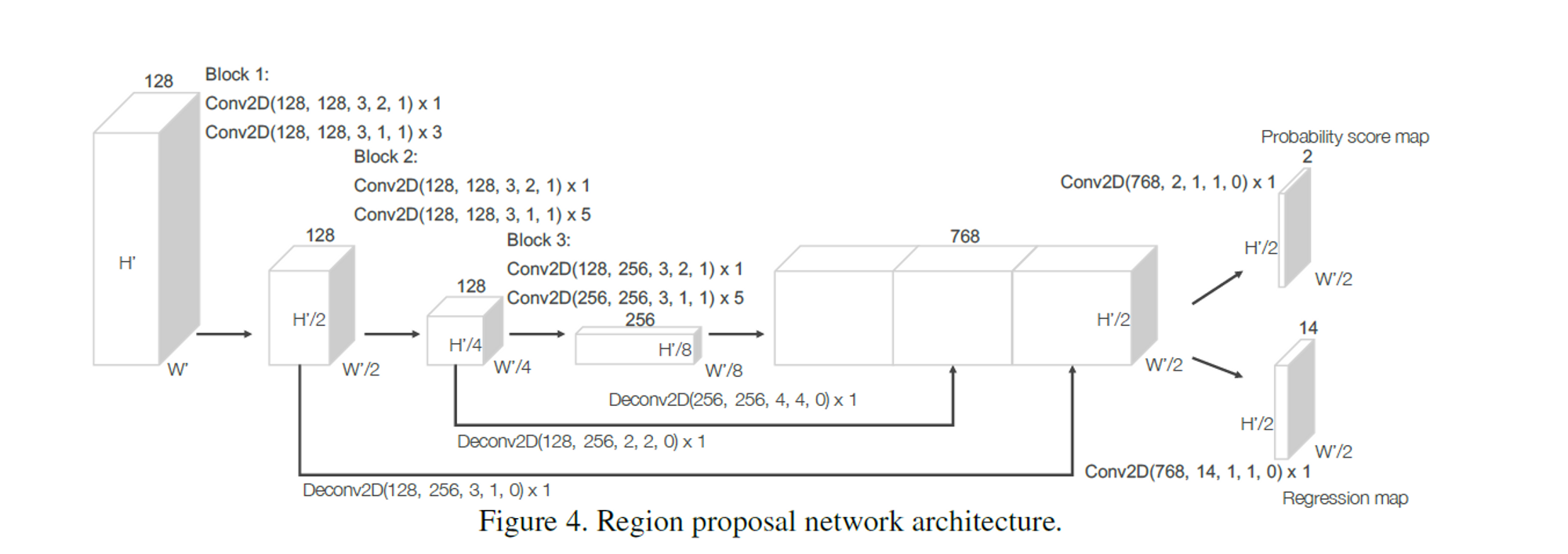
RPN层在2D物体检测中层出不穷,早在Faster-RCNN中就被提出来了。RPN层主要用来根据学习到的特征,并结合Anchor,在原图中找到物体所在检测框和对应的类别。
一般而言,RPN层有两个分支,一个用来输出类别的概率分布(通常叫做Score Map),一个用来输出Anchor到真实框的变化过程(通常叫做 Regression Map)
作者提出的RPN层的结构如下图所示。该网络以中间卷积层的输出特征图为输入,分别经过三次下采样(每次stride=2)获得三个不同维度的特征图。作者将这个三个特征图缩放至同一维度后进行拼接,有点FPN(特征金字塔网络)的感觉。最后,拼接的特征被映射成两个输出特征图
损失函数
作者引入了个正anchor和个负anchor。一个gt-3D 检测框可以用一个7维向量表示,分别是.前三项是框的中心坐标点,然后是长宽高,最后是绕Z轴的偏航角
假设与gt-bbox匹配的positive anchor的参数为 。那么RPN层中的regression分支要学的东西,就是从positive anchor到gt-bbox的变化过程参数,定义如下:
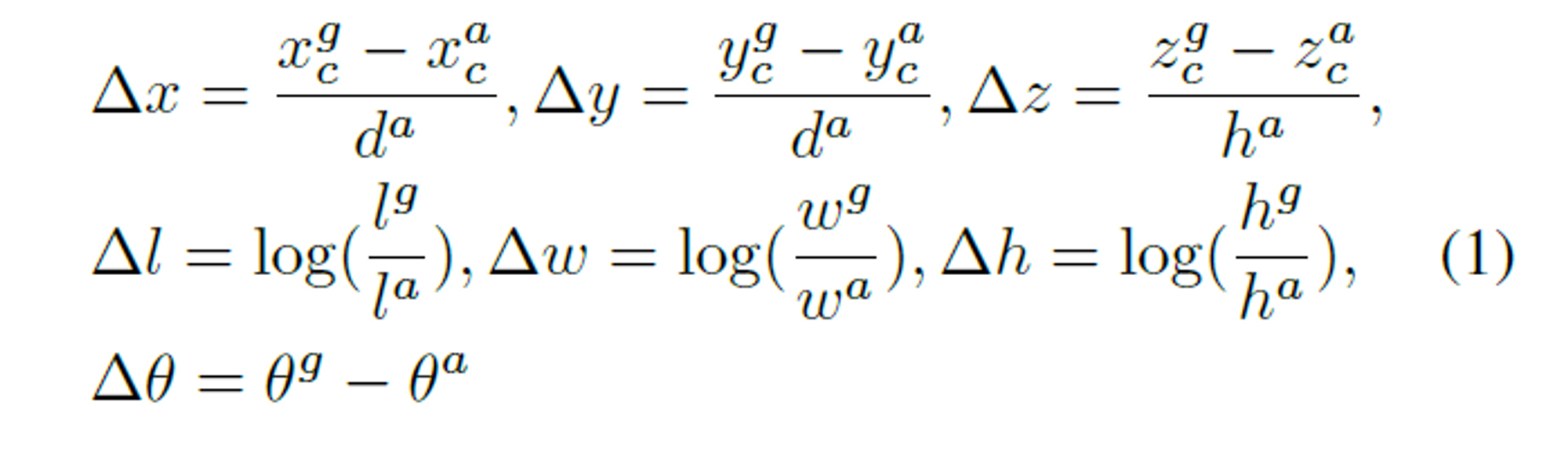
那么损失函数的定义主要分为两部分,分别为(1)分类损失(3)上述7个参数的回归损失。
其中分类损失包括Positive anchor和Negative anchor的损失。
具体定义如下: