TransFusion
Author: Bai, Xuyang; Hu, Zeyu; Zhu, Xinge; Huang, Qingqiu; Chen, Yilun; Fu, Hongbo; Tai, Chiew-Lan;
Code: https://github.com/XuyangBai/TransFusion
Comment: soft calibration , attention
Completed: December 11, 2022
Key Words: Fusion, Object Detection
Link: arXiv:2203.11496
Score: ⭐️⭐️⭐️⭐️⭐️
Source: CVPR2022
Status: once
Abstract
针对:Lidar-camera fusion ,劣质图像鲁棒性差这个问题,认为是由当下的hard-association (calibration)导致的。
We propose TransFusion, a robust solution to LiDAR-camera fusion with a soft-association mechanism to handle inferior image conditions.
Introduction&Related work
VoxelNet \ PointPillar 仅仅使用Lidar信息就取得了很好的效果。由于点云的稀疏性,要使用Fusion
融合的方法一般分成三种:1.result-level:PoinNet、RoarNet 2.proposal-level:MV3D 、AVOD
- point-level(更好的效果):一部分先将点云投射到鸟瞰图(BEV)平面上,然后将图像特征与BEV像素相融合
PI-RCNN: An efficient multi-sensor 3d object detector with point-based attentive
cont-conv fusion module. AAAI, 2020.3D-CVF: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. ECCV, 2020
Contributions:
- 采用soft-association
- 使用了基于transformer的融合方法进行细腻度融合来解决3D检测问题。有很好的鲁棒性
- 查询方法上的改进
- nuScenes的SOTA效果
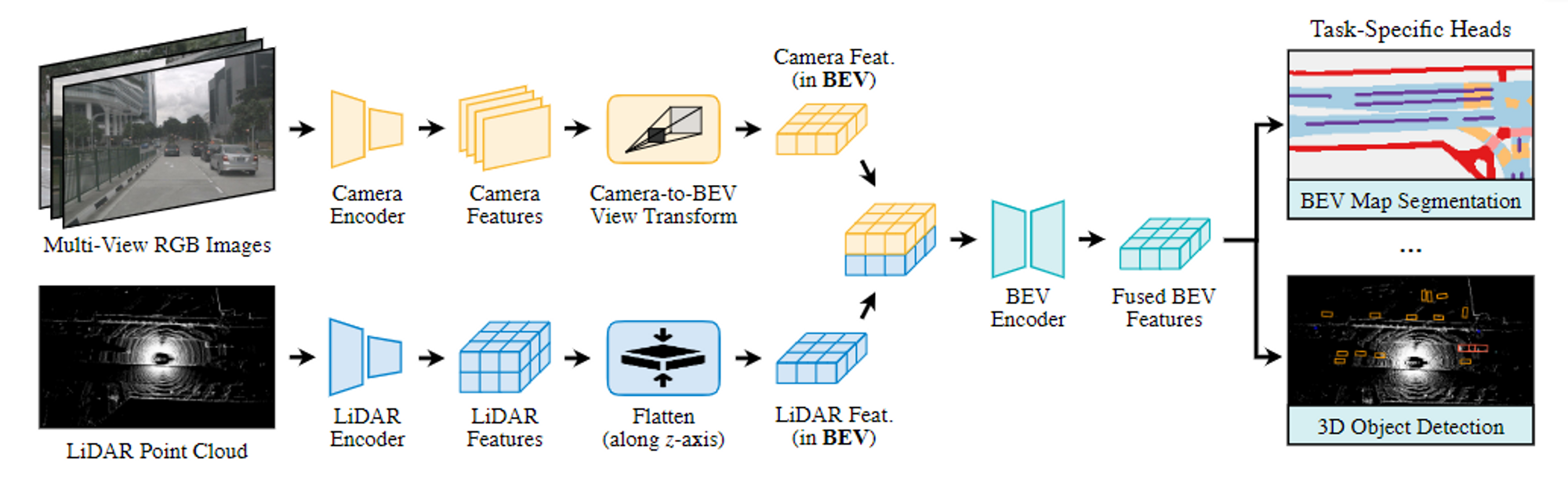
Methodology

3D and 2D backbones to extract LiDAR BEV feature map and image feature map.有两个layer组成
(1)第一层使用一组稀疏的object query生成初始 3D 边界框,以input-dependent和category-aware的方式进行初始化。 (2)第二层将第一阶段的object query(带有初始预测)与图像特征密切关联并融合,产生丰富的纹理和颜色线索,以获得更好的检测结果。引入了空间调制交叉注意 (SMCA) 机制以涉及局部诱导偏差(locality inductive bias)并帮助网络更好地关注相关图像区域。我们还提出了一种图像image-guided query initialization策略,以涉及 LiDAR BEV 上的image guidance。该策略有助于生成在稀疏 LiDAR 点云中难以检测到的object query。
Preliminary
第一层解码器:使用一组稀疏的object query从 LIDAR 点云预测初始边界框
与2D中的 input-dependent object query不同,我们使object queryinput-dependent和category-aware,更好丰富query的位置和类别信息。
object query:用transformer架构学习一小组嵌入(embeddings)(向量集合)
在我们的工作中,每个object query都包含一个提供对象定位的query positions和一个编码实例信息的query feature,例如框的大小、方向等。
Query Initialization
如果能对object queries 又较好的初始化效果,可以弥补1-layer 和6-layers的效果差距。经过我们的观察,我们提出一个 基于center-heatmap 的 input-dependent 的初始化策略,仅仅使用一层layer就获得很好的效果。
Category-aware
BEV 平面上的物体都是具有绝对比例的,在同一类别中的比例差异很小。因此通过给每一个类别embedding的方式使得object queries 是 category aware 的。
具体做法是,通过将类别的one-hot编码线性投影成向量,然后利用这个编码和query feature相加,这样的category-aware带来了两个好处:
- 一方面在self-attention模块建立object-object relations \ cross-attention 建立object-context relations 时提供了side information
- 另一方面,在预测阶段,它可以提供有价值的先验知识,使得网络专注于类别内的差异,从而有利于属性预测
Transformer Decoder and FFN(前馈神经网络)
Transformer Decoder
object query和feature maps (来自点云或图像) 之间的交叉注意力将相关上下文聚集到候选对象上,而object query之间的self attention则导致不同候选对象之间的成对关系。
query positions通过多层感知器 (MLP) 嵌入到d-dimensional positional encoding中,并与query features按element-wisely(list对应元素相加)相加。这使网络能够共同推理上下文和位置。
前馈网络 feed-forward network(FFN)
将包含丰富实例信息的 N个object query独立解码为框和类标签。
根据Center-Point,我们的FFN预测从query position的中心偏移量center offset为δx,δy,边界框高度为z,大小l,w,h为log(l),log(w),log(h),偏航角yaw angle α为sin(α),cos(α),速度(如果可用)为v_x,v_y。
我们还预测了 K 个语义类的每类概率p∈[0,1]。每个属性由单独的两层 1×1 卷积计算。通过将每个object query解码为预测,我们得到一组预测 ,其中, 是第i个query的预测边界框。
我们采用辅助解码机制,在每个解码层之后添加FFN和监督。因此,我们可以从第一个解码器层获得初始边界框预测。 我们利用 LiDAR-camera fusion module中的此类初始预测来限制交叉注意力.
LiDAR-Camera Fusion
Image Feature Fetching.
point-level融合方法带来改进,但融合质量在很大程度上受到 LiDAR 点的稀疏性的限制。当一个物体只包含少量的激光雷达点时,它只能获取相同数量的图像特征,浪费了高分辨率图像丰富的语义信息。
因此我们没有使用hard association.保留了所有的图像特征$$F_C ∈ R^{Nv×H×W×d}$$作为memory bank,在transformer 解码器中使用交叉注意力,以sparse-to-dense和自适应方法实现特征融合。
SMCA for Image Feature Fusion.
Multi-head attention是一种流行的在两组输入之间进行信息交换和建立软关联的机制,它已被广泛用于特征匹配任务。为了减轻硬关联策略带来的对传感器校准和劣质图像特征的敏感性,我们利用交叉注意机制在激光雷达和图像之间建立软关联,使网络能够自适应地确定应该从图像中获取哪些信息。
我们设计了一个空间调制交叉注意力 (SMCA) 模块 ,它通过围绕每个query的投影 2D 中心的 2D 圆形高斯掩码Gaussian mask对交叉注意力进行加权。2D Gaussian 权重mask M的生成方式与 CenterNet 类似。
(i, j) 是权重掩码 M 的空间索引
(cx, cy) 是通过将query预测投影到图像平面上计算的 2D 中心
r是三维边界框投影角的最小外切圆的半径
σ 是调制高斯分布带宽的超参数
然后,这个weight map与所有attention heads之间的cross-attention map按元素相乘。这样,每个object query只关注投影的 2D 框周围的相关区域,这样网络就可以更好更快地根据输入的 LiDAR 特征学习在哪里选择图像特征。注意力图的可视化如图 3 所示。该网络通常倾向于关注靠近对象中心的前景像素而忽略不相关的像素,为对象分类和边界框回归提供有价值的语义信息。 在 SMCA 之后,我们使用另一个 FFN(上面) 使用包含 LiDAR 和图像信息的object query来生成最终的边界框预测。

图3 第一行显示输入图像和投影在图像上的object query的预测,第二行显示交叉注意力图。我们的融合策略能够动态选择相关的图像像素,并且不受 LiDAR 点数的限制。
Label Assignment and Losses
使用Hungarian Algorithm(匈牙利算法)计算匹配成本。其中匹配成本由分类、回归、和IoU成本的加权和定义。
其中,Lcls是二元交叉熵损失,Lreg是预测的BEV中心和ground truth中心之间的L1损失(都在[0,1]中归一化),Liou是预测的方框和ground truth boxes之间的IoU损失。
考虑到所有的匹配对,我们为分类计算focal loss。用L1 loss 仅针对positive pairs 计算边界盒回归。对于heatmap prediction,我们采用 penalty reduced focal loss(Center Point采用的方法)
对于两个解码层采用一样的标签分配策略和损失公式。
image-guided query initialization
为了进一步利用高分辨率图像检测小物体的能力并使我们的算法对稀疏的 LiDAR 点云更加鲁棒,我们提出了一种Image-Guided Query Initialization策略,该策略利用 LiDAR 和camera信息来选择object query。

我们首先沿垂直维度浓缩图像特征,然后利用LiDAR BEV特征的交叉注意将这些特征投射到BEV平面上。每幅图像都由一个单独的多头关注层处理,它捕捉到图像列和BEV位置之间的关系。