RAG的问题与解决
RAG系统关键问题与挑战 (12个)
以下是RAG系统在工程实践中遇到的主要问题和挑战,整合自文章引用的论文和补充内容:
内容缺失 (Missing Content): 当答案不在知识库中时,系统倾向于生成看似合理但错误的答案,而非承认未知。
错过排名靠后的文档 (Missed Top Ranked): 正确答案可能存在于检索结果排名较低(超出Top-K范围)的文档中,因上下文长度限制而被忽略。
脱离上下文/整合限制 (Not In Context): 相关文档被检索到,但在最终传递给大模型的上下文中被遗漏,导致答案生成时未使用该信息。
未能提取答案 (Not Extracted): 相关文档在上下文中,但由于信息干扰、矛盾或文档过长,大模型未能从中提取正确答案。
格式错误 (Wrong Format): 输出格式(如表格、列表)与用户要求不符。
具体性不正确 (Incorrect Specificity): 回答过于泛化或过于具体,不满足用户需求。
回答不完整 (Incomplete Answers): 对于需要整合多个来源信息的问题,回答只覆盖了部分内容。
数据摄取扩展性 (Data Ingestion Scalability): 处理大规模数据时,数据管道出现瓶颈,影响效率和系统稳定性。
结构化数据问答 (Structured Data QA): 难以准确检索结构化数据,尤其在查询模糊或需要复杂转换(如Text-to-SQL)时。
复杂PDF数据提取 (Data Extraction from Complex PDFs): 传统方法难以处理PDF中的表格、图片等嵌入式内容。
备用模型需求 (Fallback Model(s)): 单一模型可能因访问限制或其他问题失败,需要备用方案。
大模型安全性 (LLM Security): 面临恶意输入、输出安全、敏感信息泄露等风险。
RAG系统优化策略 (12个)
文章围绕RAG工作流程的5个环节,提出了12个优化策略:
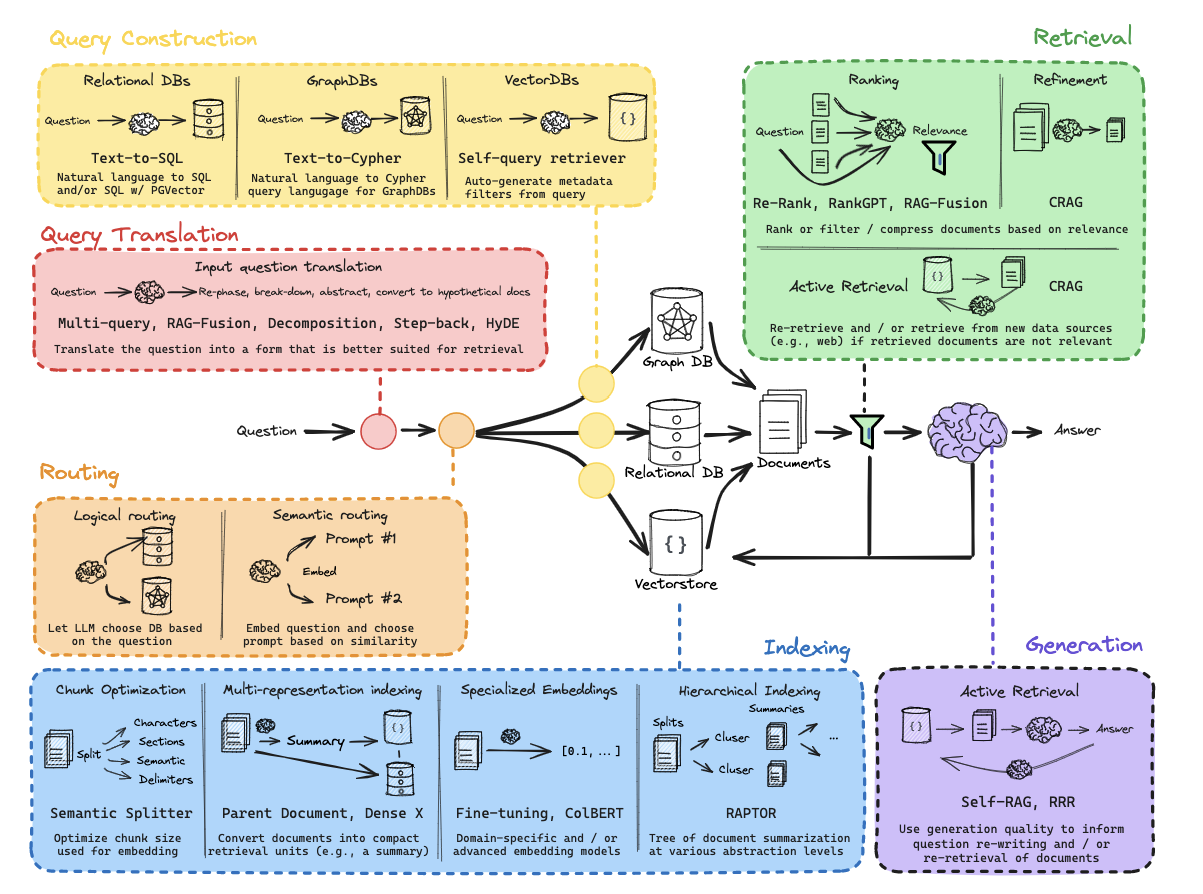
数据清洗 (Clean your data):
文本清理:规范化、去重、纠错。
实体解析:消除歧义。
文档划分、数据增强、用户反馈、时间敏感数据处理。
分块处理 (Chunking):
核心目标:优化文本单元粒度,平衡语义完整性与向量表征效率。
方法:内容分块、递归分块、从小到大分块、特殊结构分块(Markdown, LaTeX, Code)。
大小选择:依赖嵌入模型、查询类型,需实验确定(如128、256、512)。
嵌入模型 (Embedding Model):
选择:考虑模型性能(如MTEB排行榜)、是否支持中文、动态/静态词向量(如BERT优于Word2Vec)。
微调:一般不推荐,成本高、效果不确定。
元数据利用 (Metadata+):
联合存储:将元数据(时间戳、类别、来源等)与向量结合。
应用:实现基于属性的过滤、排序(如时间衰减、按学科筛选)。
多级索引 (Multi-level Indexing):
目的:处理多样化上下文场景。
实现:构建面向不同信息维度(摘要、事实、时间等)的专门索引,配合智能路由层。
注意:层级不宜过多(<4层),可探索动态剪枝、联邦索引。
索引/查询算法 (Indexing/Query Algorithm):
常用框架:近似最近邻搜索(ANNS)平衡精度与效率。
注意:知识密集型领域(法律、医疗)需谨慎使用模糊匹配,可能需要更高精度或混合方法。
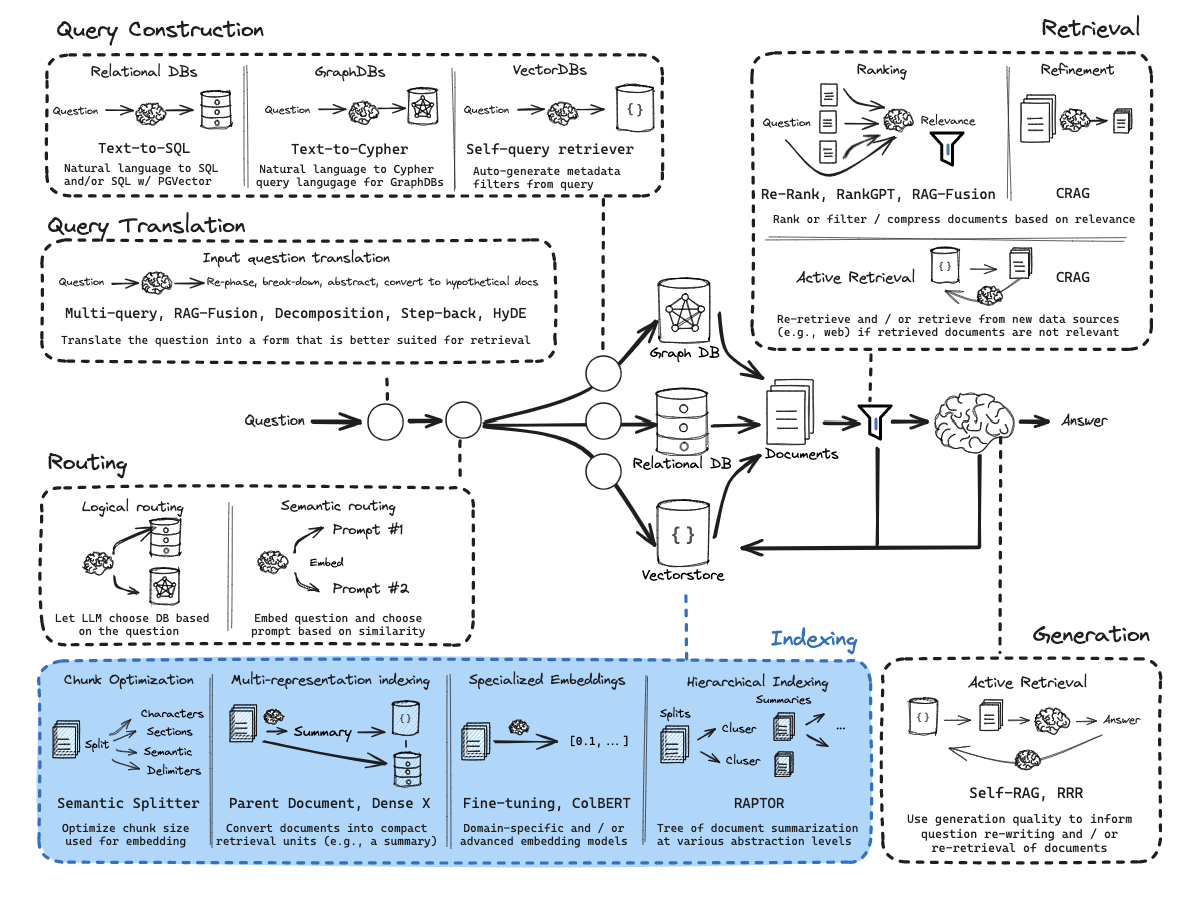
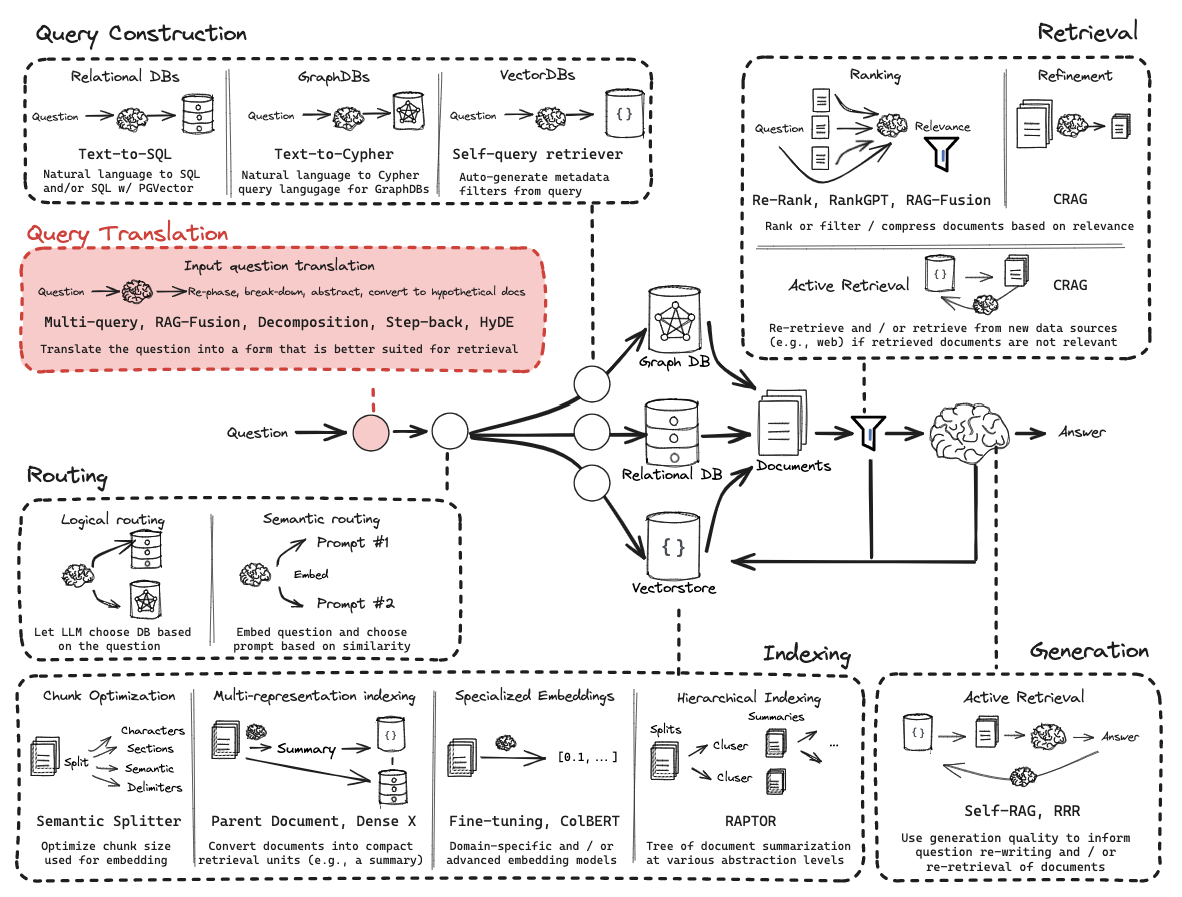
查询转换 (Query Transformation):
目的:优化用户查询以提升召回率。
方法:结合历史对话重述、假设文档嵌入(HyDE)、退后提示(Step Back Prompting)、多查询检索(Multi Query Retrieval)。
检索参数优化 (Retrieval Parameters):
混合搜索:结合稀疏(关键字,如BM25)和稠密(向量)搜索,设置权重。
结果数量(TopK):根据查询复杂度调整,平衡覆盖率与噪声。
相似度度量:常用余弦相似度,需注意模型支持。
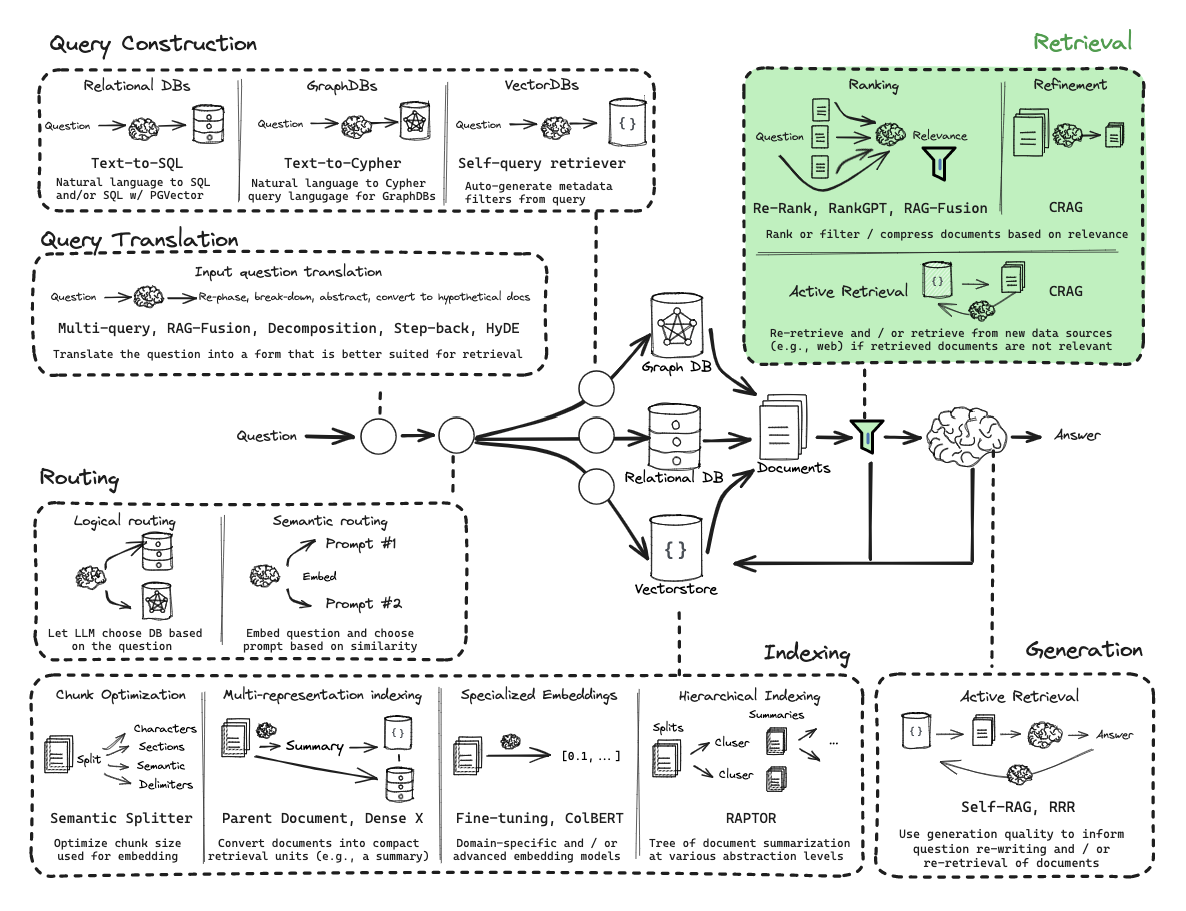
高级检索策略 (Advanced Retrieval Strategies):
上下文压缩:用LLM压缩或过滤检索到的内容。
句子窗口搜索:检索小块,但提供周围更大窗口的上下文。
父文档搜索:检索子文档,但返回其所属的父文档。
自动合并:基于层级分块,智能合并子块结果返回父块。
多向量检索:用多个向量(不同粒度、摘要、问答对等)表示同一文档,提升复杂查询效果。
多代理检索 (Multi-agent Retrieval): (见下文详述)
Self-RAG: 通过自我反思(是否需检索、内容相关性、生成质量)来优化流程。
重排模型 (Re-ranking):
目的:解决向量相似度高但实际用意不符的问题。
实现:使用第二阶段模型(如Cross-Encoder)对初步召回结果进行更精细的意图排序。
提示词工程 (Prompting):
作用:指导LLM生成,控制输出质量和风格。
方法:明确指令、角色扮演、限定知识来源、少量样本学习(Few-shot)。
大语言模型 (LLM):
作用:整合检索信息,生成最终答案。
优化:选择合适的模型,利用框架(LangChain, LlamaIndex)集成,结合重排序或领域微调提升性能。