文本检索技术
对话 API
请求参数说明
| 参数 | 类型 | 必填 | 描述 |
|---|---|---|---|
messages |
Array | 必填 | 包含对话的消息列表。 |
model |
String | 必填 | 要使用的模型的ID。 |
frequency_penalty |
Number 或 null | 可选 | 根据文本中已有令牌的频率对新令牌进行惩罚。取值范围在-2.0到2.0之间。 |
logit_bias |
Map | 可选 | 修改指定令牌在完成中出现的可能性。接受一个将令牌映射到偏置值(-100到100)的JSON对象。 |
logprobs |
Boolean 或 null | 可选 | 是否返回输出令牌的对数概率。 |
top_logprobs |
Integer 或 null | 可选 | 如果 logprobs 设置为 true,则返回每个令牌位置上最有可能的令牌数,每个都带有关联的对数概率。 |
max_tokens |
Integer 或 null | 可选 | 可以在聊天完成中生成的最大 令牌数 29。 |
n |
Integer 或 null | 可选 | 为每个输入消息生成的聊天完成选择的数量。 |
presence_penalty |
Number 或 null | 可选 | 根据新令牌是否出现在到目前为止的文本中对其进行惩罚,增加模型谈论新主题的可能性。 |
seed |
Integer 或 null | 可选 | 如果指定,系统将尽力进行确定性采样,以使具有相同 seed 和参数的重复请求应返回相同的结果。 |
stop |
String/Array 或 null | 可选 | API 将停止生成进一步的令牌的序列,最多可设置为 4 个。 |
stream |
Boolean 或 null | 可选 | 如果设置,将发送部分消息增量,就像在 ChatGPT 中一样。令牌将作为数据仅 server-sent events 6 发送,一旦可用,流将以 data: [DONE] 消息终止。参考 Example Python code 7。 |
temperature |
Number 或 null | 可选 | 使用的采样温度,介于 0 和 2 之间。较高的值(如 0.8)会使输出更随机,而较低的值(如 0.2)会使其更集中和确定性。 |
top_p |
Number 或 null | 可选 | 与温度采样的替代方法,称为核采样,其中模型考虑具有 top_p 概率质量的令牌的结果。因此,0.1 表示仅考虑构成前 10% 概率质量的令牌。 |
返回结果字段
| 参数 | 类型 | 描述 |
|---|---|---|
| id | 字符串 | 用于唯一标识聊天完成的标识符。 |
| choices | 数组 | 聊天完成选择的列表。如果n大于1,则可以有多个选择。 |
| created | 整数 | 聊天完成创建的Unix时间戳(以秒为单位)。 |
| model | 字符串 | 用于聊天完成的模型。 |
| system_fingerprint | 字符串 | 此指纹表示模型运行时的后端配置。可与seed请求参数一起使用,了解可能影响确定性的后端更改。 |
| usage | 对象 | 完成请求的使用统计信息。 |
| finish_reason | 字符串 | 表示聊天完成的原因。可能的值包括"stop"(API返回了完整的聊天完成而没有受到任何限制),“length”(生成超过了max_tokens或对话超过了max context length),等等。 |
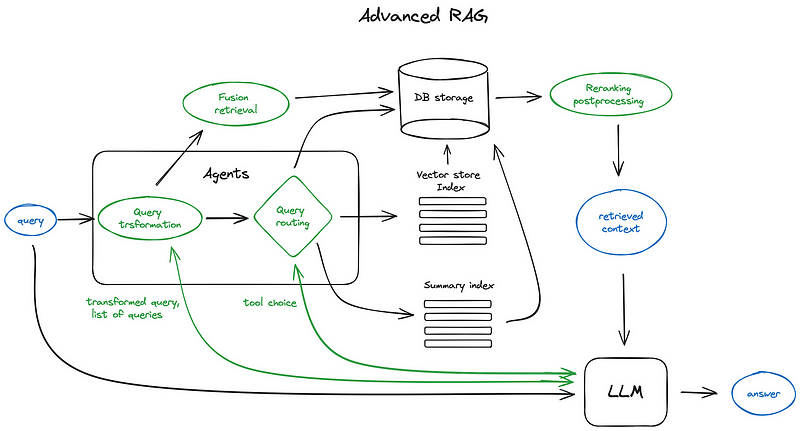
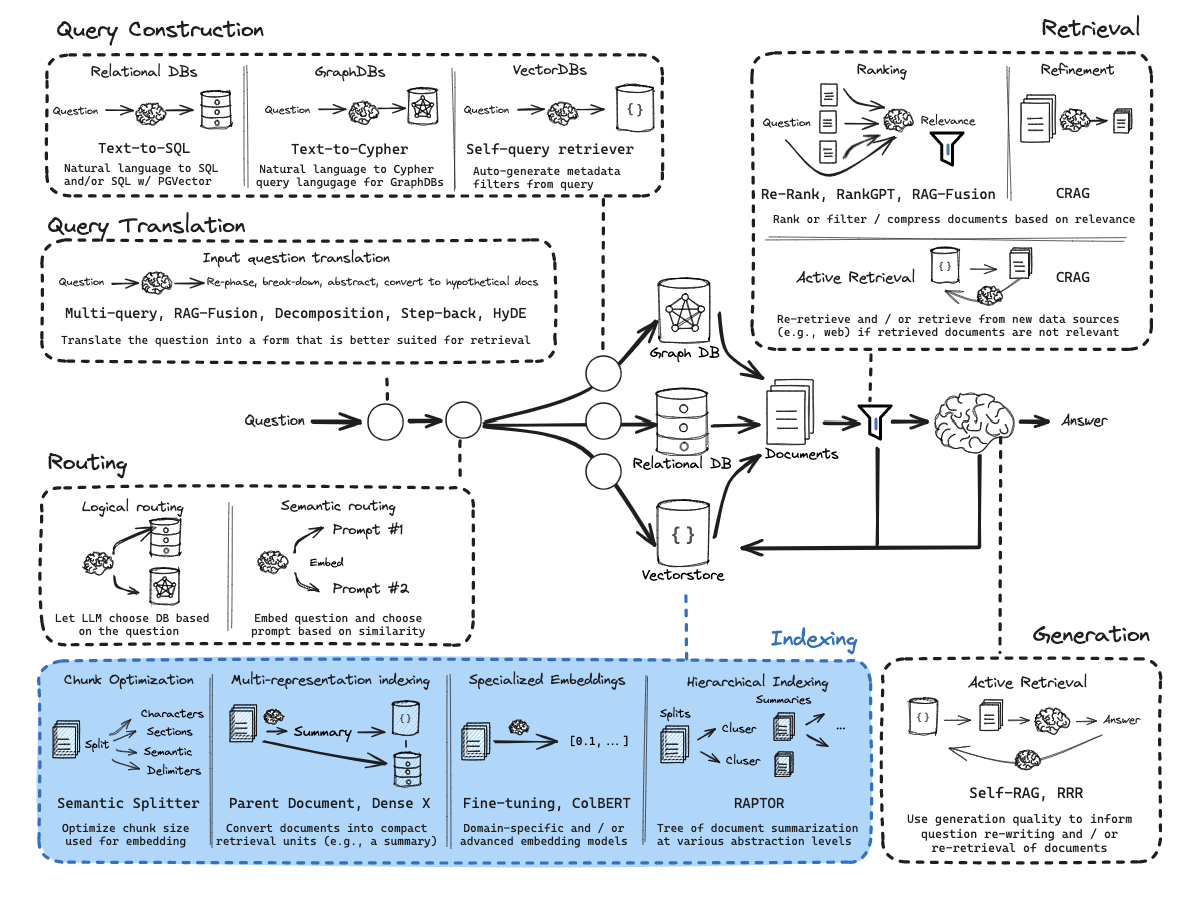
文本检索流程
文本预处理
文本预处理是一个多步骤的过程,其核心是构建倒排索引以实现高效的文本检索:
- 步骤1(文本预处理):在文本预处理阶段,对原始文本进行清理和规范化,包括去除停用词、标点符号等噪声,并将文本统一转为小写。接着,采用词干化或词形还原等技术,将单词转换为基本形式,以减少词汇的多样性,为后续建立索引做准备。
- 步骤2(文本索引):构建倒排索引是文本检索的关键步骤。通过对文档集合进行分词,得到每个文档的词项列表,并为每个词项构建倒排列表,记录包含该词项的文档及其位置信息。这种结构使得在查询时能够快速找到包含查询词的文档,为后续的文本检索奠定了基础。
- 步骤3(文本检索):接下来是查询处理阶段,用户查询经过预处理后,与建立的倒排索引进行匹配。计算查询中每个词项的权重,并利用检索算法(如TFIDF或BM25)对文档进行排序,将相关性较高的文档排在前面。
在实际应用中,倒排索引的构建和维护需要考虑性能问题,采用一些优化技术来提高检索效率,如压缩倒排索引、分布式索引等。这些步骤共同构成了一个有序而逻辑完整的文本检索流程。
文本检索与语义检索
下面是文本检索和语义检索的区别和联系的表格形式:
| 文本检索 | 语义检索 | |
|---|---|---|
| 定义 | 通过关键词或短语匹配文本数据的过程 | 强调理解查询与文本之间的深层语义关系 |
| 方法 | 基于关键词匹配,使用TFIDF、BM25等权重计算 | 使用NLP技术,如词嵌入、预训练的语言模型 |
| 特点 | 强调字面意义,关注表面文本的匹配 | 关注词语之间的关联、语境和含义 |
| 应用场景 | 大规模文本数据的快速匹配 | 对语义理解要求较高的场景 |
| 优势 | 处理速度较快,适用于大规模文本数据 | 能够处理一词多义、近义词等语义上的复杂情况 |
| 联系 | 结合使用,先使用文本检索筛选出候选文档,然后在这些文档上应用语义检索 | 可以利用语义模型提取关键词的上下文信息,提升检索效果 |
在一些场景中,文本检索和语义检索可以结合使用,以充分利用它们各自的优势。例如,可以先使用文本检索筛选出候选文档,然后在这些文档上应用语义检索来进一步提高检索的准确性。当然具体使用哪种检索方法,需要具体分析,在RAG中可以结合两种方法一起进行使用。
TFIDF
词项在文档中的频率(TF)
逆文档频率(IDF)
TFIDF的计算
BM25
BM25Okapi的主要参数
BM25Okapi是BM25算法的一种变体,它在信息检索中用于评估文档与查询之间的相关性。以下是BM25Okapi的原理和打分方式的概述:
- BM25Okapi的主要参数:
- :控制词项频率对分数的影响,通常设置为1.5。
- :控制文档长度对分数的影响,通常设置为0.75。
- :用于防止逆文档频率(IDF)为负值的情况,通常设置为0.25。
打分的计算过程
其中,是文档集合中的平均文档长度。BM25Okapi通过合理调整参数,兼顾了词项频率、文档长度和逆文档频率,使得在信息检索任务中能够更准确地评估文档与查询之间的相关性,提高检索效果。
语义检索流程
语义检索是通过词嵌入和句子嵌入等技术,将文本表示为语义丰富的向量。通过相似度计算和结果排序找到最相关的文档。用户查询经过自然语言处理处理,最终系统返回经过排序的相关文档,提供用户友好的信息展示。语义检索通过深度学习和自然语言处理技术,使得系统能够更准确地理解用户查询,提高检索的准确性和效果。
文本编码模型
文本编码模型对于语义检索的精度至关重要。目前,大多数语义检索系统采用预训练模型进行文本编码,其中最为常见的是基于BERT(Bidirectional Encoder Representations from Transformers)的模型,或者使用GPT(Generative Pre-trained Transformer)等。这些预训练模型通过在大规模语料上进行训练,能够捕捉词语和句子之间的复杂语义关系。选择合适的文本编码模型直接影响到得到的文本向量的有效性,进而影响检索的准确性和效果。
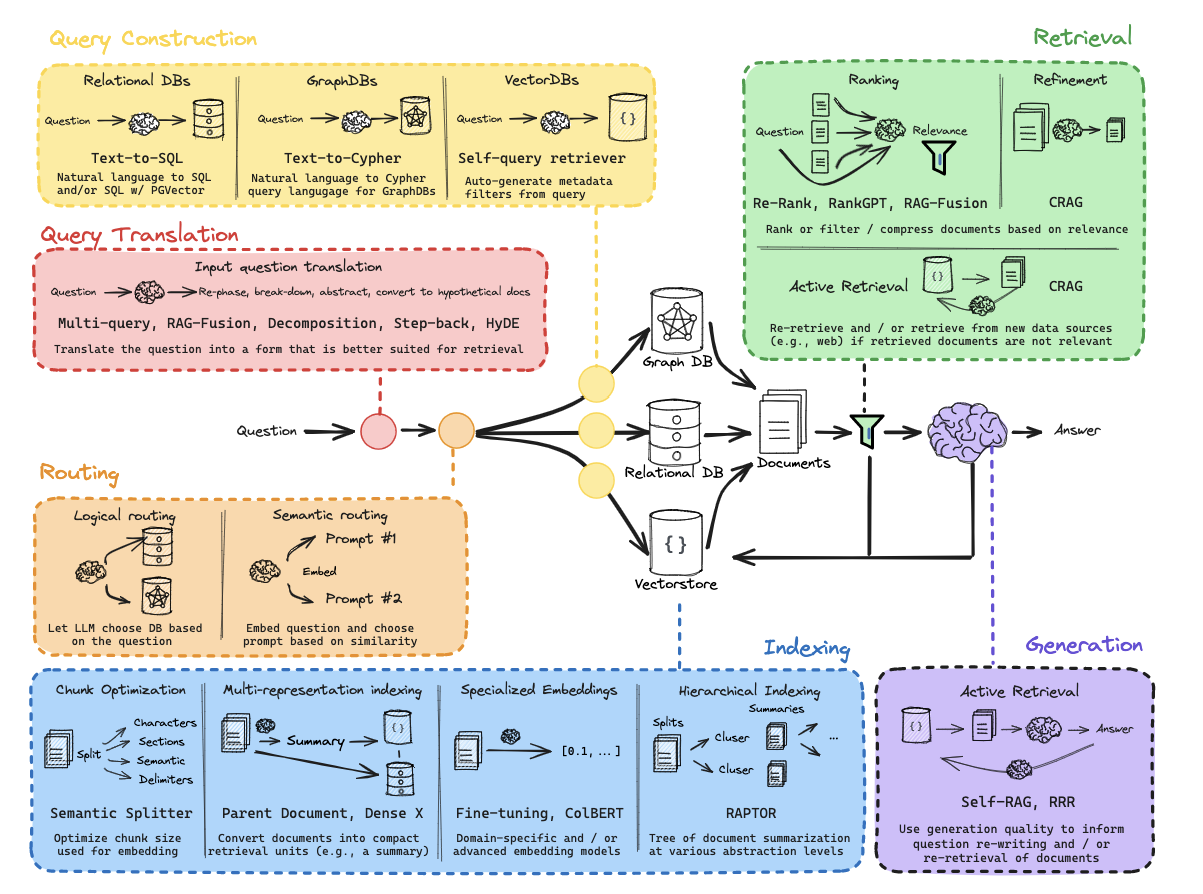
文本切分方法
文本的长度是另一个关键因素,影响了文本编码的结果。短文本和长文本在编码成向量时可能表达不同的语义信息。即使两者包含相同的单词或有相似的语义,由于上下文的不同,得到的向量也会有所不同。因此,当在语义检索中使用短文本来检索长文本时,或者反之,可能导致一定的误差。针对文本长度的差异,有些系统采用截断或填充等方式处理,以保持一致的向量表示。
| 名称 | 分割依据 | 描述 |
|---|---|---|
| 递归式分割器 | 一组用户定义的字符 | 递归地分割文本。递归分割文本的目的是尽量保持相关的文本段落相邻。这是开始文本分割的推荐方式。 |
| HTML分割器 | HTML特定字符 | 基于HTML特定字符进行文本分割。特别地,它会添加有关每个文本块来源的相关信息(基于HTML结构)。 |
| Markdown分割器 | Markdown特定字符 | 基于Markdown特定字符进行文本分割。特别地,它会添加有关每个文本块来源的相关信息(基于Markdown结构)。 |
| 代码分割器 | 代码(Python、JS)特定字符 | 基于特定于编码语言的字符进行文本分割。支持从15种不同的编程语言中选择。 |
| Token分割器 | Tokens | 基于Token进行文本分割。存在一些不同的Token计量方法。 |
| 字符分割器 | 用户定义的字符 | 基于用户定义的字符进行文本分割。这是较为简单的分割方法之一。 |
| 语义分块器 | 句子 | 首先基于句子进行分割。然后,如果它们在语义上足够相似,就将相邻的句子组合在一起。 |
对于自然语言,可以推荐使用Token分割器,结合Chunk Size和Overlap Size可以得到不同的切分:
- Chunk Size(块大小):表示将文本划分为较小块的大小。这是分割后每个独立文本块的长度或容量。块大小的选择取决于应用的需求和对文本结构的理解。
- Overlap Size(重叠大小):指相邻两个文本块之间的重叠部分的大小。在切割文本时,通常希望保留一些上下文信息,重叠大小就是控制这种上下文保留的参数。
多路召回逻辑是在文本检索中常用的一种策略,其目的是通过多个召回路径(或方法)综合获取候选文档,以提高检索的全面性和准确性。单一的召回方法可能由于模型特性或数据特点而存在局限性,多路召回逻辑引入了多个召回路径,每个路径采用不同的召回方法。
- 实现方法1:将BM25的检索结果 和 语义检索结果 按照排名进行加权
- 实现方法2:按照段落、句子、页不同的角度进行语义编码进行检索,综合得到检索结果。
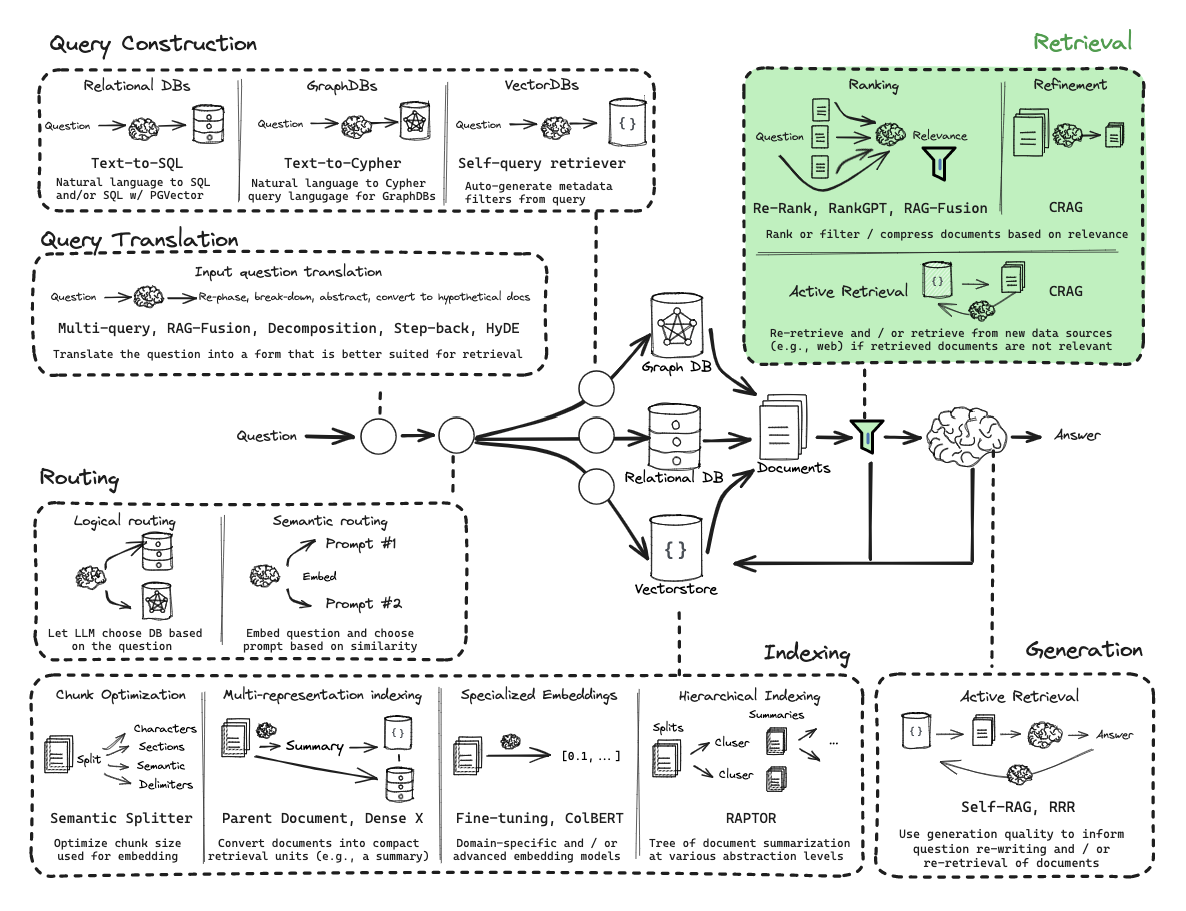
重排序逻辑(BM25 + BGE Rerank)
重排序逻辑是文本检索领域中一种重要的策略,主要用于优化原有文本检索方法返回的候选文档顺序,以提高最终的检索效果。在传统的文本检索方法中,往往采用打分的逻辑,如计算BERT嵌入向量之间的相似度。而重排序逻辑引入了更为复杂的文本交叉方法,通过特征交叉得到更进一步的打分,从而提高排序的准确性。
- 重排序逻辑常常使用更为强大的模型,如交叉编码器(cross-encoder)模型。这类模型能够更好地理解文本之间的交叉关系,捕捉更复杂的语义信息。
- 首先通过传统的嵌入模型获取初始的Top-k文档,然后使用重排序逻辑对这些文档进行重新排序。这样可以在保留初步筛选文档的基础上,更精确地排列它们的顺序。